-
-
Clinical Decision Room
Inspiration
Tumor boards work because they put structurally different minds in the same room. The oncologist, the radiologist, the surgeon, the pathologist — each one looks at the same patient through a different lens, and the value isn't the consensus, it's the disagreement. The moment someone says "wait, what if it's actually this?" is the moment a blind spot gets caught.
Most clinical decisions don't get that treatment. A clinician in the ED at 3 a.m. is running probabilistic reasoning, pattern matching, worst-case thinking, and guideline recall — all in one tired brain, at the worst possible time. The frameworks blur together, and whichever one is loudest wins.
We wanted to externalize that. Give each way of thinking its own room, run them in parallel, and show the clinician the shape of the decision they're already making — not a single AI verdict.
What it does
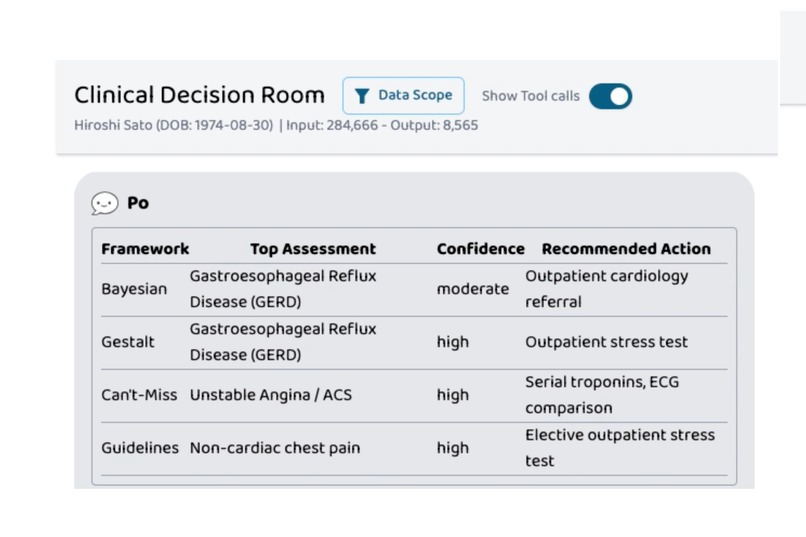
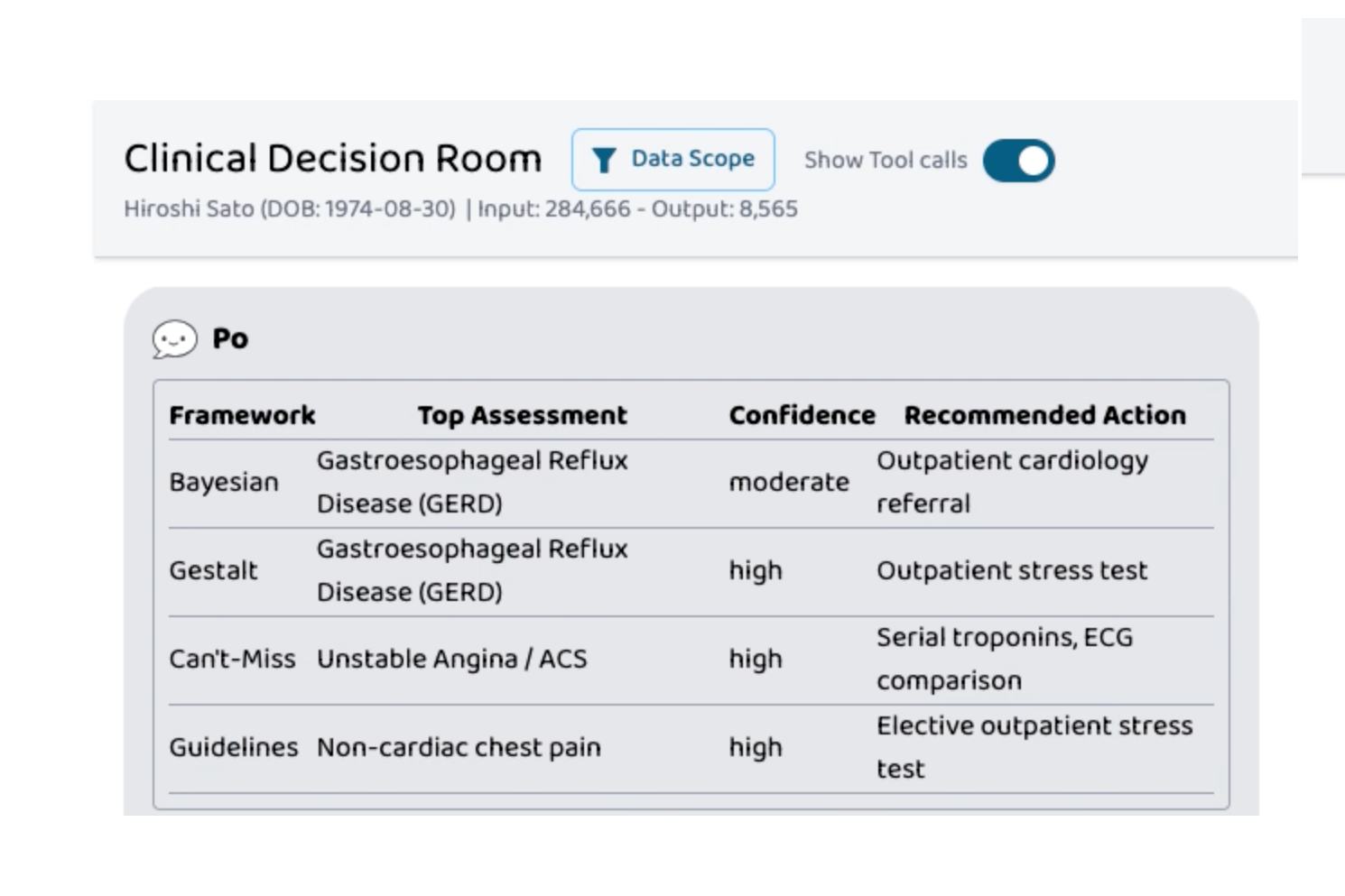
Clinical Decision Room takes a patient case and runs it through four structurally distinct reasoning frameworks in parallel:
- Bayesian — base rates, likelihood ratios, ranked differential with probabilities
- Gestalt — illness-script matching, pattern fit, atypical features
- Can't-Miss — adversarial worst-case reasoning, flags dangerous diagnoses even when unlikely
- Guidelines — published clinical practice guidelines, recommendation classes, validated risk scores
A synthesis pass then produces a structured report that preserves:
- Agreements — what the frameworks converge on (your solid ground)
- Divergences — where they split, and why the structural difference produces a different answer
- Current recommendation — single best next action, with honest uncertainty
- Decision-flip conditions — the specific findings that would change the recommendation
The output is a decision scaffold, not a verdict. It tells the clinician where the disagreement lives and exactly what would change their mind.
Full Technical Write-Up
I wrote a deeper breakdown of the architecture, reasoning frameworks, A2A integration, and decision-scaffold design here:
How we built it
The core is an A2A (Agent-to-Agent) server in Python, designed to be consumed by external agent hosts — in our demo, Prompt Opinion. Given a clinical question, the executor fans out to four Gemini-powered "panelists" running in parallel, each with a prompt structured around its specific reasoning framework. A fifth Gemini call synthesizes the four outputs into the final report, returned as a structured JSON artifact.
When the host provides FHIR context, the executor pulls patient demographics, conditions, medications, labs, and allergies from the specified FHIR server before running the panelists, so the analysis is grounded in real chart data rather than just the typed question.
We deployed the agent to Google Cloud Run with Docker, with a local development path through ngrok for fast iteration against the live Prompt Opinion frontend.
Challenges we ran into
The hardest part wasn't the reasoning — it was the protocol. The A2A spec has evolved through several versions, and different clients speak different dialects: some use tasks/send, some use message/send, some use proto-style SendMessage; some send content, some send parts; some expect role enums as user, others as ROLE_USER. We ended up writing a compatibility middleware that normalizes both incoming requests and outgoing responses, so the agent works across the dialect range instead of being locked to one client.
The second hard problem was prompt design. It's surprisingly easy to write four "different" prompts that all converge on the same answer, because the underlying model has its own priors. Getting genuine structural disagreement — where Can't-Miss really does push back on a case Bayesian wants to clear — required prompts that don't just describe a framework, but force the model into the framework's failure mode. Can't-Miss has to be paranoid. Guidelines has to refuse to leave the document. Otherwise you just get four polite agreements and the whole point evaporates.
Accomplishments that we're proud of
The demo case is a real one: a 51-year-old with reflux history, normal troponin, a HEART score of 4 — the exact ambiguous presentation where flattening into one answer is dangerous. Three frameworks lean toward GERD. Can't-Miss dissents. The synthesis doesn't paper over it; it names the disagreement, anchors on guidelines for the middle path (serial troponin, then likely discharge with outpatient workup), and lists the specific findings — troponin bump, dynamic ECG changes, exertional pain, PPI failure — that would flip the call. That's the artifact we wanted to build, and on this case it works.
We're also proud that the whole thing is pluggable. The four frameworks aren't hardcoded into one giant prompt — each one is its own panelist, and a fifth one can be added, swapped, or replaced over A2A without touching the others.
What we learned
The most useful clinical AI output isn't an answer. It's a decision scaffold — current recommendation plus the conditions that would change it. Clinicians already do this; they just don't usually get to see it written down. Once you see your own reasoning externalized as a structure with named disagreement, the next decision is faster and you notice your blind spots earlier.
We also learned that "multi-agent" only earns its keep when the agents are structurally different. Four instances of the same model with four polite system prompts will converge. Real disagreement requires real structural difference in how each agent is allowed to reason.
What's next for Clinical Decision Room
- More frameworks. Bias-aware (anchoring, premature closure), cost-of-care, patient-preference-weighted. The architecture supports any number of panelists.
- Calibration on real cases. We want to run the system on retrospective case archives where the eventual outcome is known, and measure how often Can't-Miss was right to dissent.
- Tighter EHR integration. The FHIR fetch works; the next step is feeding the output back as a structured note that lives next to the chart.
- Specialty packs. The current panelists are general internal medicine. Specialty-tuned versions (cardiology, oncology, psychiatry) would change which "can't miss" diagnoses are weighted, which guidelines apply, and which patterns count as classic.
- Human-in-the-loop disagreement logging. Track which divergences clinicians found useful vs noisy, and tune the panel composition from real feedback.

Log in or sign up for Devpost to join the conversation.