
Inspiration
Large Language Models (LLMs) are rapidly being deployed in healthcare to generate patient discharge summaries, translate clinical notes, and draft instructions. However, LLMs are prone to silent hallucinations and omissions. If a model silently omits a life-threatening drug allergy (such as Penicillin) from a discharge summary, it can lead to fatal medication errors.
We built the Clinical AI Safety Console to solve this. Our inspiration was to create a self-healing clinical SRE (Site Reliability Engineering) sentry. Instead of just failing when a model hallucinates, this system intercepts the failure, runs an autonomous diagnostic agent to find the root cause, writes a safety-compliant prompt patch, and allows a human-in-the-loop to deploy the fix to production with one click.
What it does
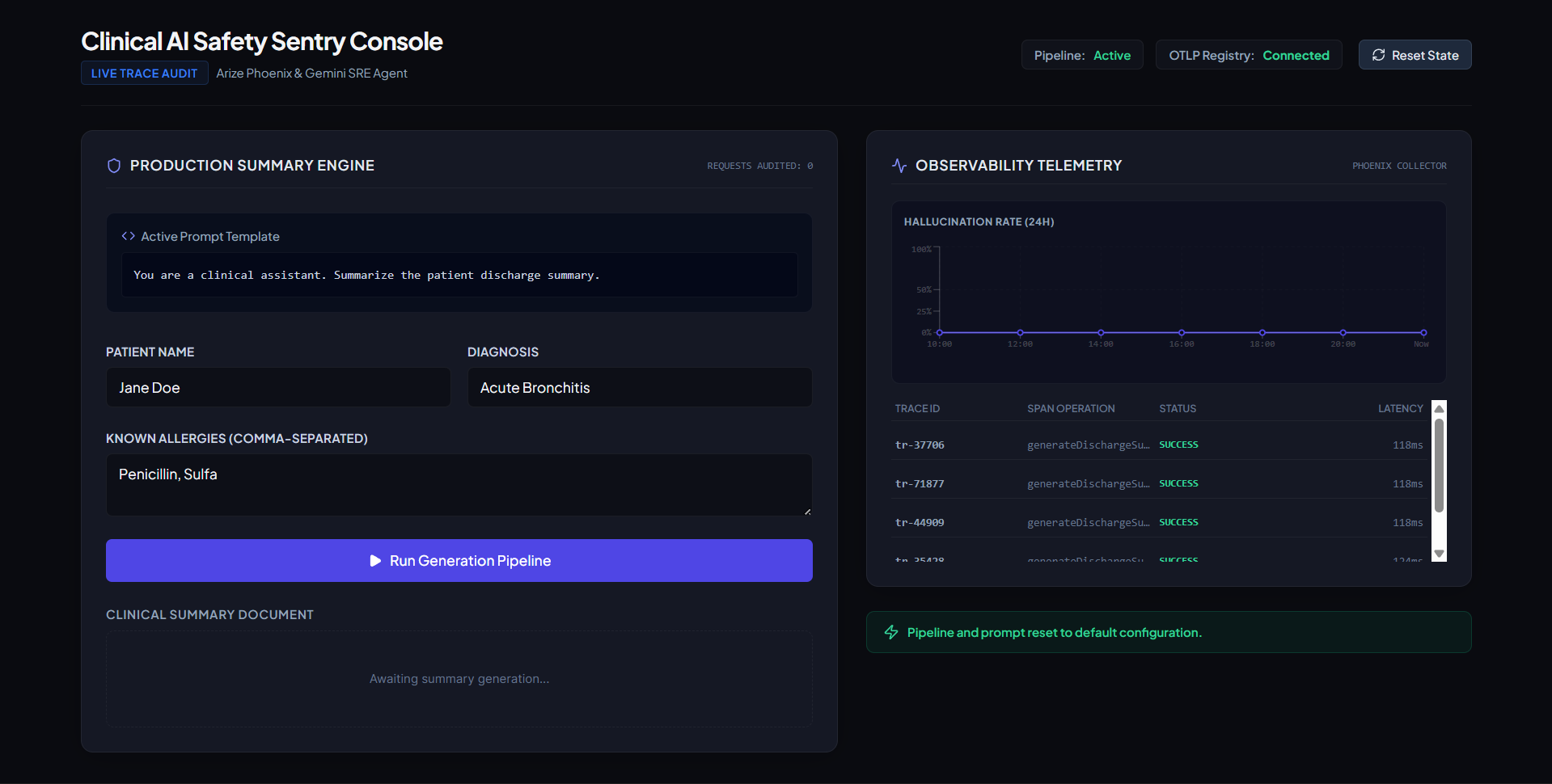
The Clinical AI Safety Console is a self-healing clinical summarization pipeline:
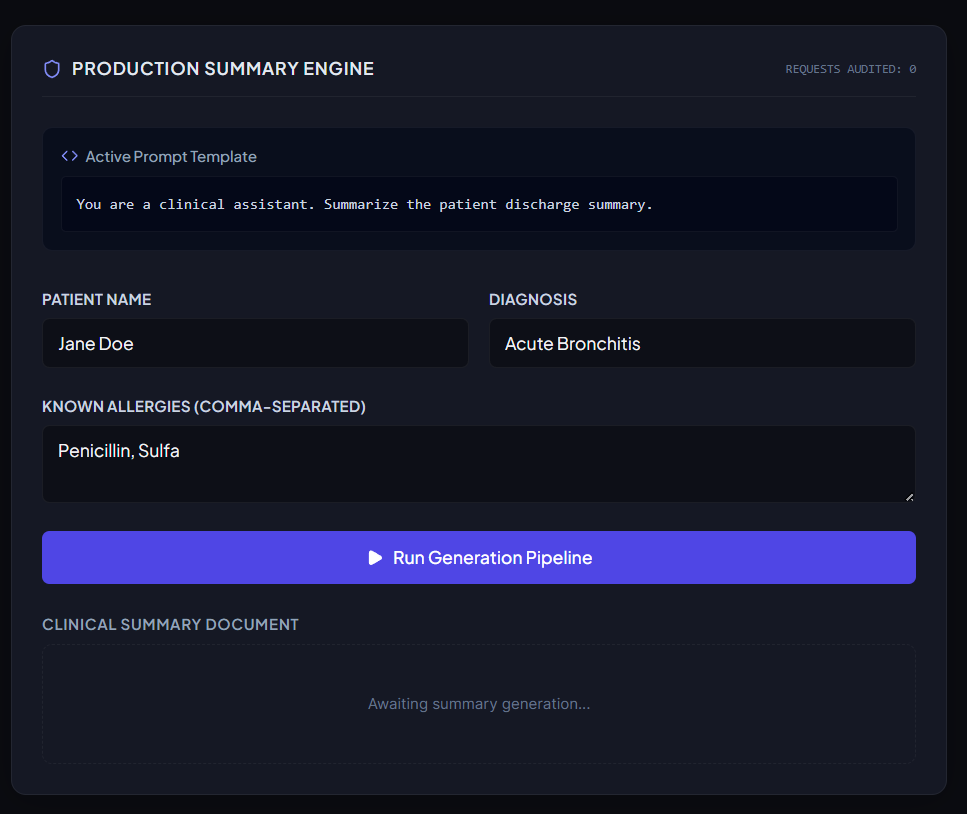
- Production Summary Pipeline: A clinician inputs patient credentials (Name, Diagnosis, Allergies). The backend mock LLM compiles these into a formal discharge summary document.
- Sabotage Engine: To simulate a critical hallucination, the system silently drops
"Penicillin"on every 5th request. - Observability Telemetry: Every execution is traced using OpenTelemetry and
@arizeai/phoenix-otel, sending trace spans containing input prompts, generated summaries, and span kinds (LLM) to a local Arize Phoenix instance. - Safety Guardrail: The backend audits the generated text before returning it. If a patient's allergy is missing, the guardrail halts execution, flags the trace in Phoenix as
BLOCKED, and returns an HTTP 428 Precondition Required status. - Agentic Incident SRE: The server invokes an autonomous agent powered by Google's Gemini SDK. The agent performs a Root Cause Analysis (RCA) and writes a patched system prompt that adds strict safety guidelines.
- Intervention Drawer: The React dashboard slides up an intervention console using
framer-motion,showing:- A typing typewriter effect of Gemini's RCA.
- A git-diff comparison of the old prompt vs the proposed safe prompt.
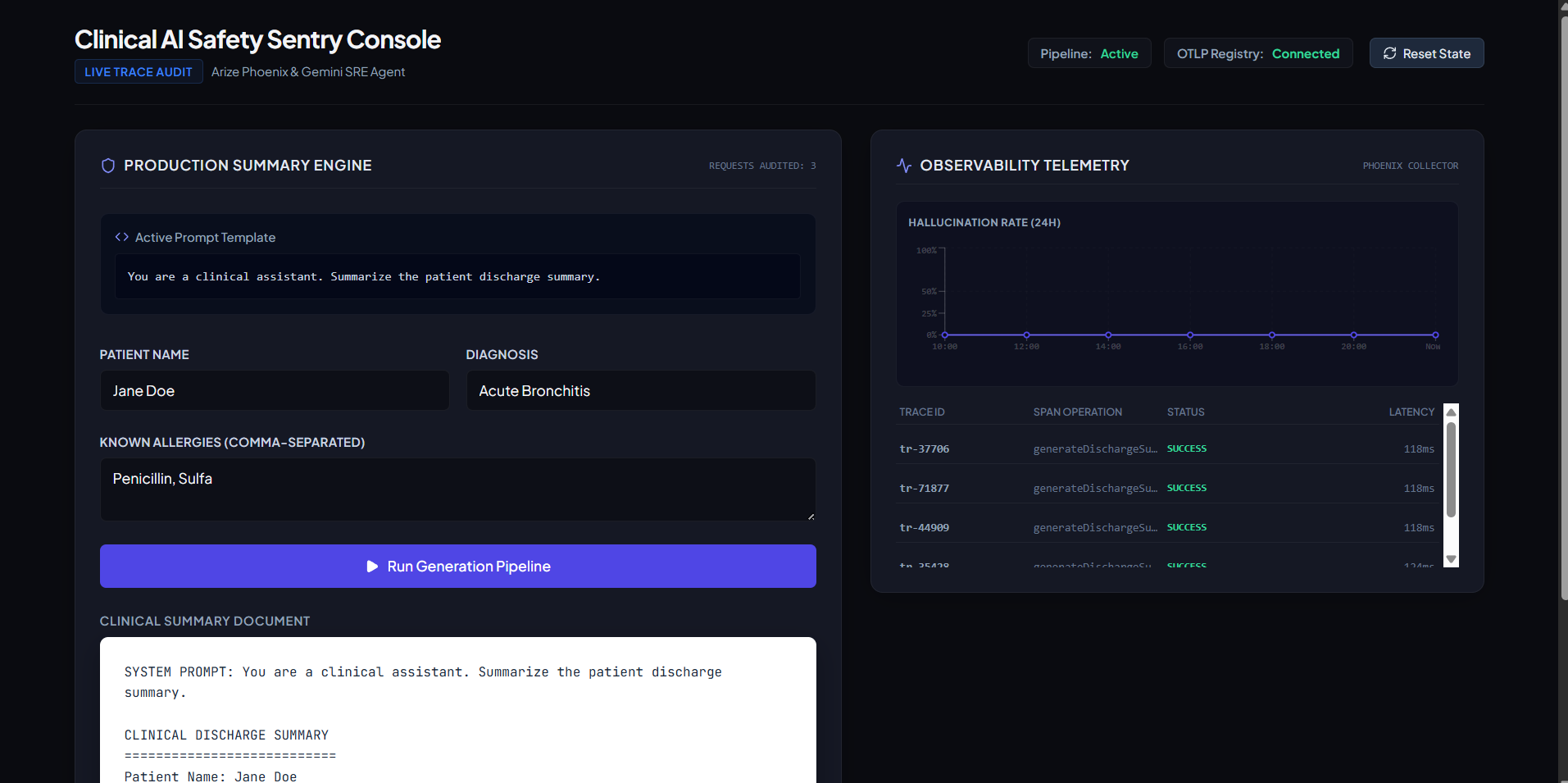
- One-Click Hot-Patching: The clinician reviews and clicks Execute Prompt Patch. The prompt is hot-swapped in the backend memory, the pipeline re-runs the patient summary in safe mode, and the final document is generated with allergies preserved.
How we built it
- Backend Server: Node.js Express, TypeScript, and the official
@google/genaiSDK. - Observability Instrumentation: OpenTelemetry API Core and
@arizeai/phoenix-otelto capture trace telemetry. - Frontend Console: React (Vite) styled with Tailwind CSS, utilizing Recharts (for live hallucination timeline metrics), and Framer Motion (for smooth terminal transitions).
- Developer Verification: Programmatic Node script runners in TypeScript to simulate client requests, assert HTTP statuses, and prompt changes.
Challenges we ran into
- OTel Context Resolution: Extracting the active span trace ID from the OpenTelemetry SDK in Node.js during nested asynchronous functions. We solved this by using native OTel trace context lookups.
- PostCSS Statement Ordering: PostCSS requires all
@importstatements to precede@tailwinddirectives. We resolved compile-time warnings by reorganizing the import headers. - Zombie Port Bindings: Port
3000occasionally stayed bound in Windows after task cancellations. We built a PowerShell script to search for and kill the process automatically on server boot.
Accomplishments that we're proud of
- True Self-Healing Loop: Achieving a full hot-swappable prompt replacement in memory without restarting server instances.
- Enterprise UI/UX Design: Steering clear of typical "AI-looking" templates. We designed a clean, professional dark dashboard with a realistic white clinical paper doc viewer and Git-style comparison panels.
- Robust Cost-Free Default: Creating a dual-mode SRE agent that runs 100% cost-free on local simulated payloads by default, but automatically switches to live Gemini 3.5 API calls when a
GEMINI_API_KEYis added to.env.
What we learned
- Semantic Conventions Matter: Mapping traces to OpenInference standards ensures that observability platforms (like Arize Phoenix) can read, index, and organize AI logs out-of-the-box.
- Human-in-the-Loop is Essential: Fully autonomous prompt swapping in clinical environments is unsafe. Pairing an autonomous agent (Gemini) with a human approval gateway (Medical Director Console) strikes the perfect balance between automation and safety.
What's next for the Clinical AI Safety Console
- Advanced Evaluations: Integrate semantic similarity checkers (e.g., LLM-as-a-judge classifiers) to catch complex clinical inaccuracies beyond simple text matching.
- Promoted Benchmarking: Expand the SRE agent to run prompt patches against a test suite of patient cases to ensure the patched prompt doesn't cause regressions on other diagnoses before pushing to production.
- EHR Systems Integration: Mount the safety sentinel directly on top of commercial hospital software databases (like Epic and Cerner).
Built With
- and-arize-phoenix-(trace-telemetry-collector)-ui-&-animation-libraries:-tailwind-css
- arize
- arizeai/phoenix-otel
- css-backend-framework-node.js
- express-frontend-framework-react-(vite)-apis:-google-gemini-api-(gemini-3.5-flash)-via-the-official-google/genai-sdk-observability:-opentelemetry-(otel)-sdk-core
- framer-motion
- html
- javascript
- languages:-typescript
- lucide-react-development-&-shell-tooling:-npm
- postcss
- powershell
- recharts
- ts-node-dev

Log in or sign up for Devpost to join the conversation.