-
-
Climb's landing. The promise is in three words: context, pattern, execution. The full thesis of the product compressed into one screen.
-
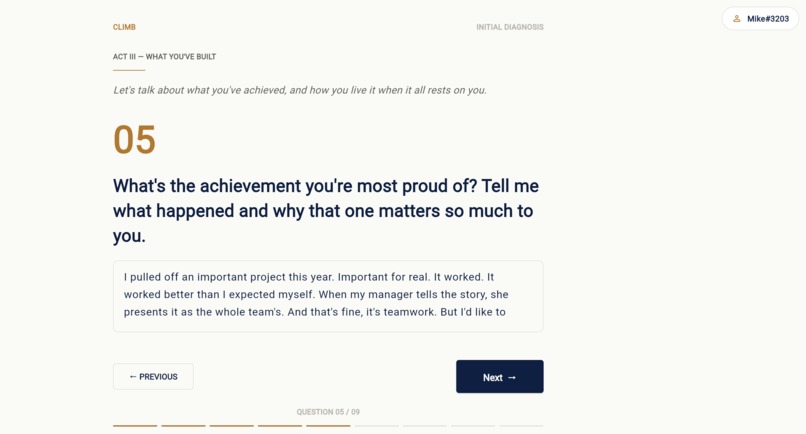
Question 5 of 9. Mike writes the way he talks — repetition, voice markers, a small confession. Raw input is exactly what Scout needs.
-
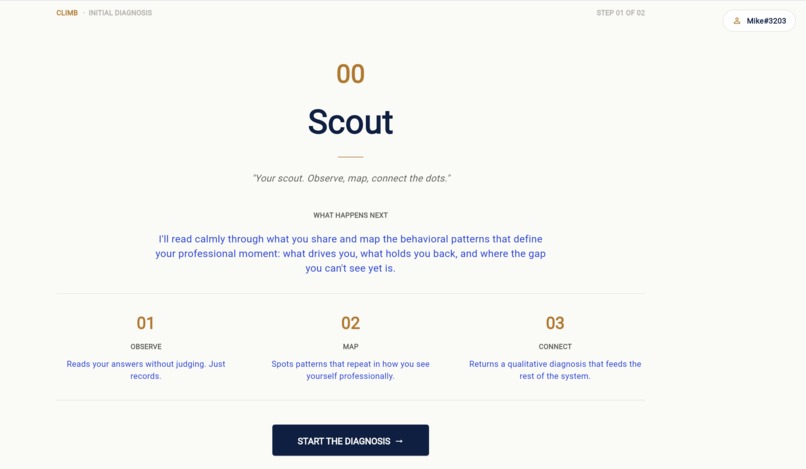
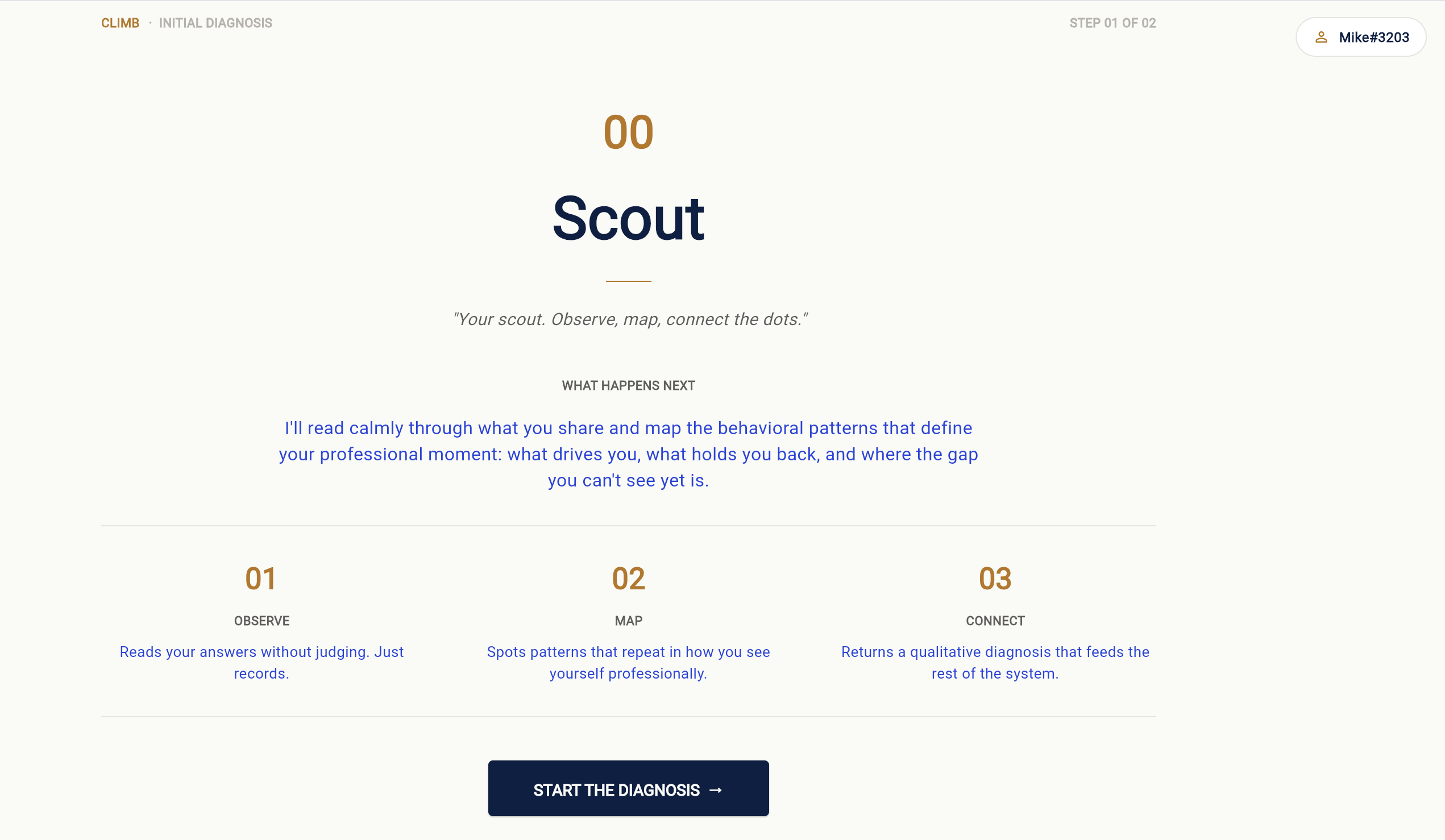
Scout, the first agent Mike meets. Observe, map, connect. Reads raw onboarding and returns a qualitative diagnosis, not a checklist.
-
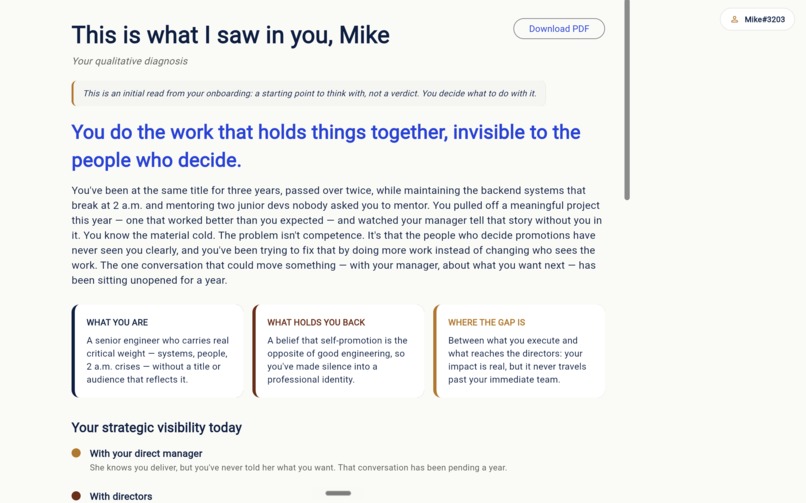
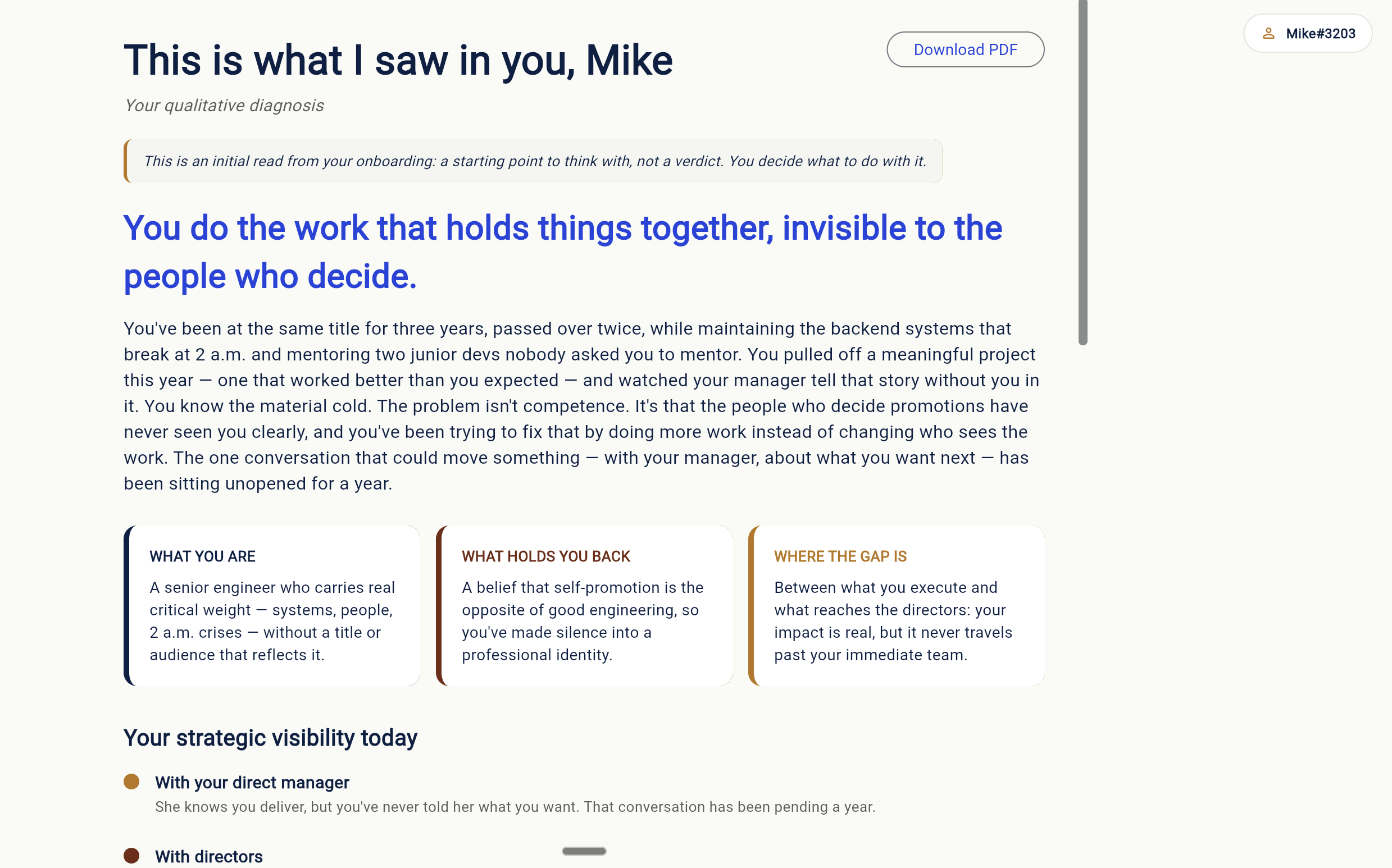
Scout's diagnosis. A pivot phrase, three named angles (what you are, what holds you back, where the gap is). A starting point, not a verdict
-
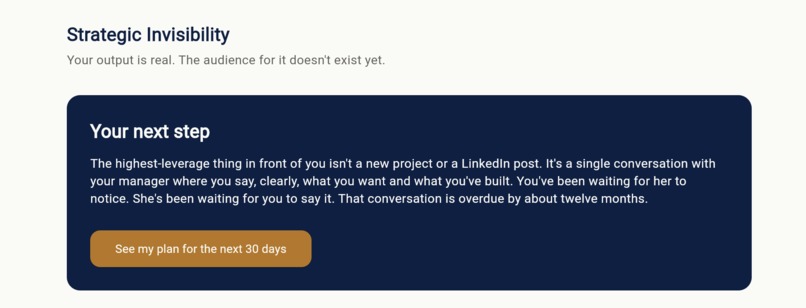
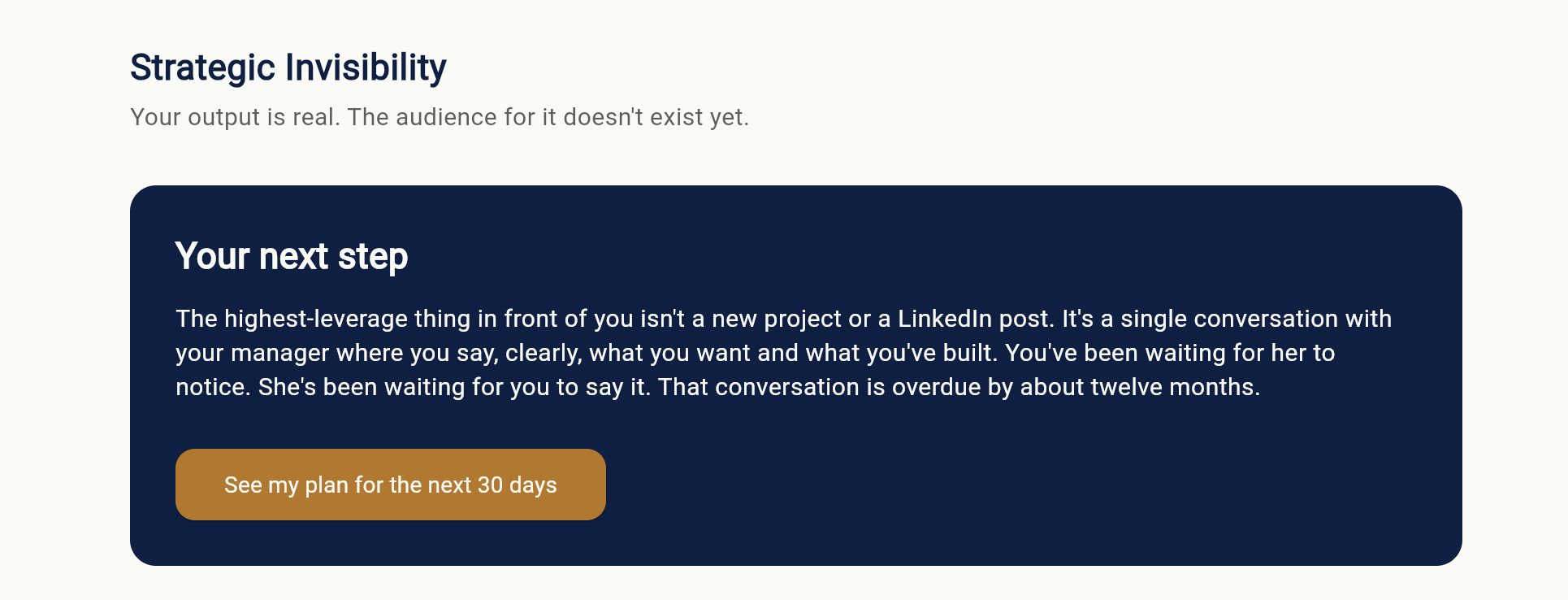
Mike's stuck pattern, named. Strategic Invisibility: real output, no audience yet. The next step points to one overdue conversation.
-
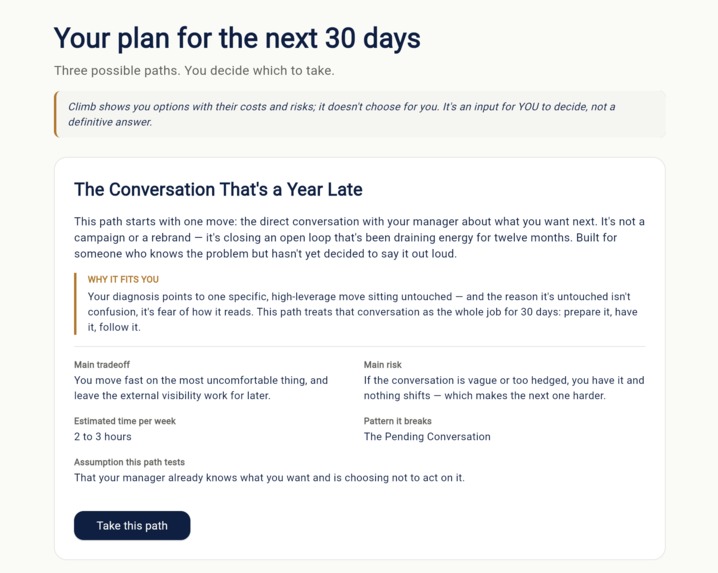
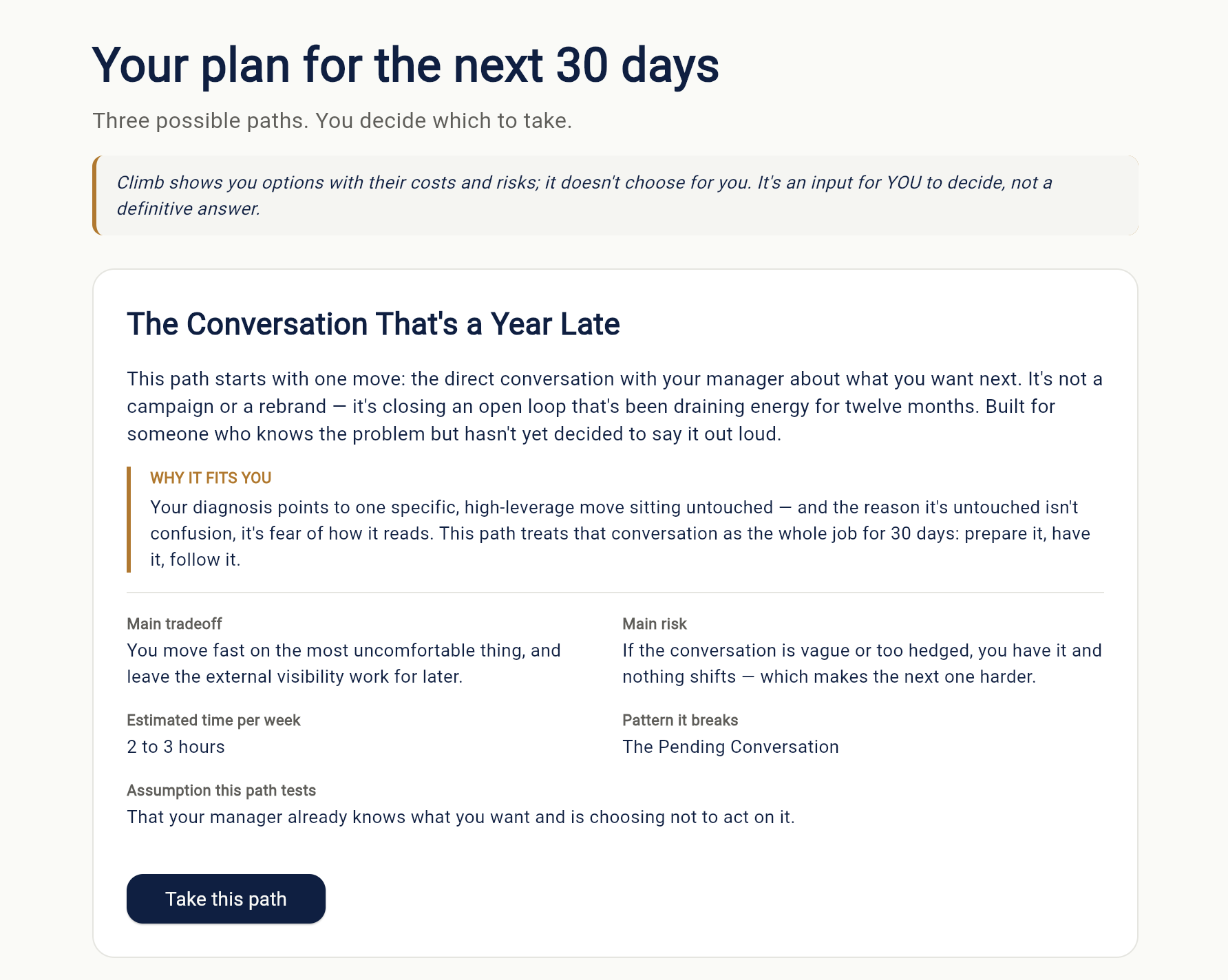
Climb's defining moment. Three 30-day paths with tradeoffs, risks, and assumptions visible. Climb shows options. The user decides
Inspiration
Mike is 28 years old, a systems engineer in Monterrey, México. Three years at the same company. He does good work. He has been passed over for promotion twice — not for lack of work, but for lack of visibility.
Mike isn't one person. He's thousands of mid-level professionals across Latin America who do the work but never learn to make it visible. In our region, internal promotion is decided more by perception than by measurable performance, and that costs promotions to the people already holding the business together.
We built Climb because the existing tools fail this person. Coaches are expensive, hard to schedule, and forget what you said three months ago. Career platforms treat the problem as résumés and job boards, not as the day-to-day work of making your impact legible upward. Generic LLM assistants can generate text on demand, but they don't remember who you are, they don't notice patterns in how you talk about your work, and they don't push you toward concrete action.
We wanted to build a system that does what a great mentor does at their best moments: reads what you actually say, names the patterns you can't see from the inside, shows you options with their real costs, and pushes you toward a first step that either happens or doesn't this week.
What it does
Climb is your career's right hand — an AI multi-agent system that takes a vague professional ambition and turns it into a 30-day plan with a concrete first step for this week.
The flow:
- Onboarding. The user answers nine open questions across four acts, in raw narrative form. No résumé fields, no LinkedIn voice — they write the way they talk.
- Diagnosis. Scout, the first agent, reads the nine responses and returns a qualitative diagnosis: a pivot phrase that names what's underneath, three patterns with their own names (not generic categories), a limiting belief quoted directly from the user's words, and the type of stuck they're in.
- Three paths. Scout also generates three possible 30-day paths. Each one has its own tradeoff, its own risk, the assumption it tests, the pattern it breaks, and the realistic weekly time it requires. The user chooses — Climb never chooses for them.
- Weekly mission. Once the path is chosen, Pacer turns it into a weekly mission with three to five verifiable actions. Not "work on your visibility" but "send your manager an update on the project where the one showing up is you, before Friday."
- Six specialized agents. Beyond Scout and Pacer, the user has access to Mirror (works limiting patterns through Socratic questions), Archive (documents wins as structured cards for performance reviews), Editor (translates technical impact into executive language while preserving the user's voice), and Clarity (helps think through decisions, citing real material from other agents by database index — not by model memory).
Climb doesn't promise promotions. It promises a system that remembers what you build, names the patterns that hold you back, translates your work into the language of those who decide, and pushes you toward the next concrete step every week.
How we built it
Climb is a single Python application built on Flet 0.85.3, which lets us ship the same codebase as a desktop app and a web app. We deploy on Render, manage secrets with python-dotenv, and talk to the models through the anthropic SDK 0.109.1. All persistence is local, in SQLite.
Models
We split work across two models by role. The six user-facing agents (Scout, Pacer, Mirror, Archive, Editor, Clarity) run on Claude Sonnet 4.6, because their output is what the user reads. The backstage classification calls run on Claude Haiku 4.5: Mirror's boundary detector, Archive's achievement extractor, Clarity's findings extractor, and the voice profile updater. They do narrow, structured jobs where speed matters more than prose.
Relational memory
Memory is relational, not vector-based. Everything Climb knows lives in typed SQLite tables: Usuarios and Usuario_Perfil for identity and the nine onboarding answers, Hallazgos_Perfil for insights (each tagged with a type and an origin), Historico_Resumenes for the consolidated profile, Camino_Elegido for the chosen path, Mirror_Patrones, Logros_Personales, Misiones, Voice_Profile, and Editor_Borradores. Because findings carry type and origin, agents retrieve facts by query instead of trusting the model to remember them.
Agent pattern
Every agent call is built the same way. A shared identity prompt from core/identidad.py is prepended to each request through _con_identidad(), so all six agents speak in the same voice. On top of that sits the agent's own task prompt. Non-conversational agents (Scout's diagnosis, Pacer's missions and fichas) return structured JSON output. Mirror is conversational, and runs each user turn past the boundary classifier before answering.
Cross-reference by index
When Clarity references work from Mirror or Archive, it never quotes from the model's memory. We pull the real rows from the database, hand them to the model as a numbered list, and the model may only answer with an index. The app resolves that index back to the stored record and renders the verbatim text. A citation is a real database row or it does not exist.
Voice profile
The voice profile is built incrementally. We track a sample counter and a confidence level (baja, media, alta), and the profile only firms up as evidence accumulates. It learns style only: tone, lexicon, rhythm. It never uses content from Clarity sessions.
Challenges we ran into
Making Scout sound like a person, not a template
Our first diagnoses read like generic coaching: "areas of opportunity," "growth mindset." Useless. We fixed it with explicit few-shot examples in the prompt and hard prohibitions against abstract categories. Pattern names have to be specific and memorable, like "the invisible architect pattern," never a generic label.
Drawing Mirror's boundary
Mirror works on professional patterns, so it has to notice when a conversation crosses into mental health territory. The hard part was precision: we needed to catch real crises without false positives that interrupt legitimate work frustration. We run a dedicated Haiku classifier before each Mirror response, and when it fires, Climb stops and hands the choice back to the user rather than pushing through.
One brand voice across six agents
Scout diagnoses, Editor rewrites, Pacer assigns missions. Very different jobs, but they cannot sound like six different products. The shared identity prompt in core/identidad.py, prepended to every call, keeps the voice consistent without us re-tuning each agent in isolation.
Latency versus quality
Sonnet 4.6 gives us the depth we want in user-facing output, but running every call through it would make the app feel slow. Splitting roles between Sonnet 4.6 and Haiku 4.5 let the heavy generation stay rich while the classifiers (boundary, extractors, voice profile) return fast.
Hallucinated references
When one agent mentions another's material, a paraphrase that drifts is worse than silence. The index-based cross-reference solved this: the model points at a database row, and the app supplies the actual words. The model cannot invent a quote because it never holds one.
Voice profile without touching sensitive content
We wanted agents to write in the user's voice, but Clarity is a private thinking space. So the voice profile analyzes style only and excludes Clarity content entirely. It learns how someone writes without reading what they confided.
Cold start
A coach that knows nothing on session one is dead on arrival. We made the nine-question onboarding the bootstrap for the profile, so a new user walks out of the first session with a full diagnosis, named patterns, and three concrete paths.
Accomplishments that we're proud of
A real multi-agent system in seven days. Six specialized agents, each with a focused role, sharing a relational memory schema across twelve database tables. Not a wrapper around a single chat — a system where agents reference each other's outputs by stable database indices, which is how Climb avoids hallucinating references.
The three-paths screen. This is the moment that defines Climb. Most career tools give one recommendation and hide the tradeoffs. Climb shows three paths side by side, each with its tradeoff, its risk, the assumption it tests, and the pattern it breaks — and then steps aside. The decision belongs to the user. We're proud that we built the UI and the prompts that make this work as a real moment of agency, not as a checkbox.
Responsible AI implemented in code, not in copy. We didn't add a disclaimer at the bottom of a screen. We built a boundary classifier that detects when a Mirror conversation crosses into mental health territory and redirects to a professional. We built a voice profile that learns the user's writing style but never uses content from Clarity, their reflection space. We made the choice between paths a decision Climb never takes — programmatically, not aspirationally.
Coherence between language and product. Climb has a documented voice: warm, direct, specific, never motivational, no clichés, no emojis. Every prompt across six agents respects it. Every screen of the UI respects it. The brand isn't a layer painted on top — it's how the system was built.
Naming patterns with their own identity. Scout doesn't return "you lack visibility." It returns the invisible architect pattern, with a description of how it specifically operates in this user's role and industry, backed by direct quotes from what they wrote. That naming work — turning raw narrative into interpretive language that hits — is the part of Climb we're most proud of as a craft.
What we learned
The difference between an LLM wrapper and a real system is the memory schema. Vector embeddings work for retrieval. They don't work when you need typed evidence — when one agent has to cite, by exact reference, what another agent said three sessions ago. A relational schema with explicit types (finding, summary, pattern, achievement, mission, draft) gave us a memory that composes cleanly across agents without hallucination.
Prompts without few-shot examples produce generic output. Our first version of Scout returned categories like "you tend to be analytical" or "you struggle with visibility." Useless. The version that worked included three concrete examples of what a named pattern looks like (e.g., the invisible architect, the half-conversation with your boss) and explicit prohibitions against generic categories. That single change moved the output from coaching template to specific reading.
Responsible AI is a design decision, not a copy decision. Writing "this is not a verdict" at the bottom of a screen is decoration. Building a classifier that stops Mirror from continuing when the user crosses into mental health, or making the path selection structurally impossible for the AI to make on behalf of the user, is design. We learned the difference by trying both.
Brand voice protects against feature drift. Every time we considered adding something (more agents, more dashboards, more features), the documented identity helped us say no. Climb is supposed to feel like a lucid person who knows you and tells you the truth without ornament. That sentence killed more good-looking-but-wrong features than any product debate did.
Latency matters as much as quality. A diagnosis that takes 90 seconds to generate feels broken even if it's perfect. We learned to split work across two models — Sonnet 4.6 for user-facing generation, Haiku 4.5 for backstage classifiers — to keep responsiveness without sacrificing the parts that need a stronger model.
What's next for Climb
Beta with real users in Monterrey and CDMX. Before adding any new features, we want to validate Climb with twenty real users who match the Mike archetype: mid-level Latin American professionals stuck on visibility. Not to validate the technology — to validate that the pivot phrases Scout returns hit hard enough to change what the user does on Monday morning.
Migrate to persistent infrastructure. Move from SQLite to Postgres so users can return across devices and across months. The composing-context thesis only works if the system actually keeps that context over real time, not just within a demo session.
Climb for Teams. A B2B layer where companies can understand, at an aggregate and fully anonymized level, why their mid-level talent isn't getting promoted. Not surveillance — pattern visibility for HR and engineering managers who today have no data on this.
Deeper inter-agent composition. Right now Clarity already cites Mirror and Archive by index. We want every agent to be able to compose context from every other agent, so that after three months of use Climb has a working understanding of the user that no single conversation could build alone.
A real conversation about the business model. Subscription, marketplace of coaches, B2B layer — we have three possible monetization paths mapped, but launching well means choosing one for the first eighteen months. That decision happens after we have real-user data, not before.
Built With
- anthropic
- claude
- claude-haiku
- claude-sonnet
- desktop
- flet
- python
- render
- sqlite
- visual-studio
- web

Log in or sign up for Devpost to join the conversation.