








Inspiration
ClimateIQ originated from a practical climate downscaling challenge: converting coarse Earth System Grid Federation data into a fast, actionable decision-support pipeline. Early work focused on loading NetCDF files, warming a neural network with GraphCast-derived weights, and generating reports highlighting generalization gaps and cross-validation results. Version four (4) reframes the system as a “Climate Downscaling Pipeline” with explicit attention to uncertainty, baseline comparisons, and spatial generalization shifting the goal from pure prediction to making climate intelligence reliable and defensible for real-world use.
What it does
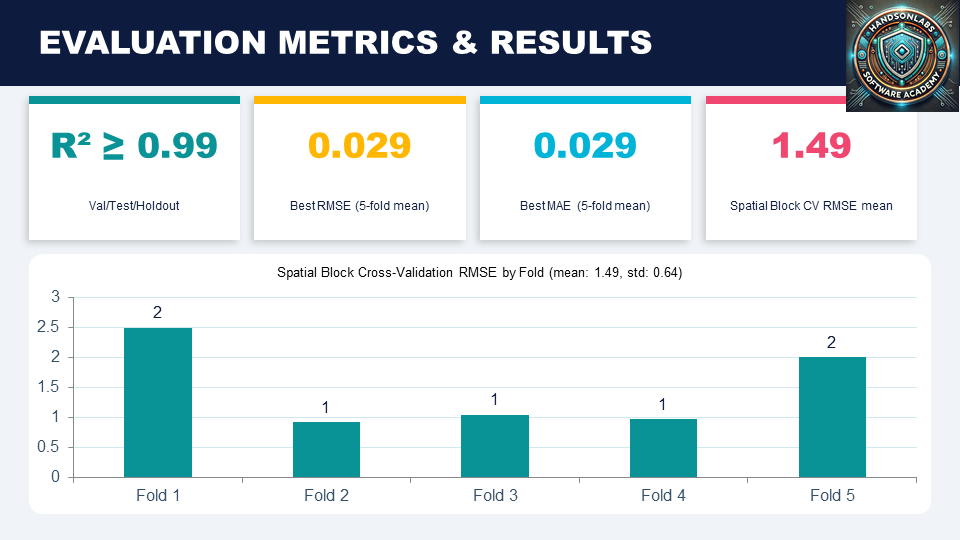
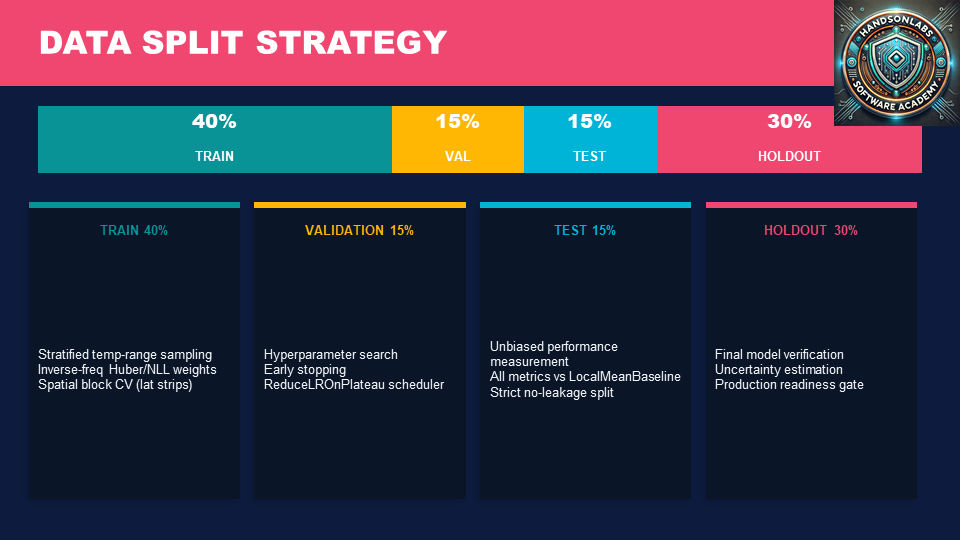
ClimateIQ delivers an end-to-end downscaling workflow. The initial version discovered .nc files, split data into train/validation/test/holdout sets, and trained a neural downscaling head using GraphCast warm initialization and Huber loss. The updated pipeline adds stratified sampling, a local-mean baseline, spatial block cross validation, heteroscedastic loss, uncertainty aware prediction, tail fine tuning for extreme temperature ranges, and export of model metadata (tokenizer and scaler configurations). The result is a robust predictive system that turns raw climate fields into performance reports explaining accuracy, uncertainty, and generalization behavior.
How we built it
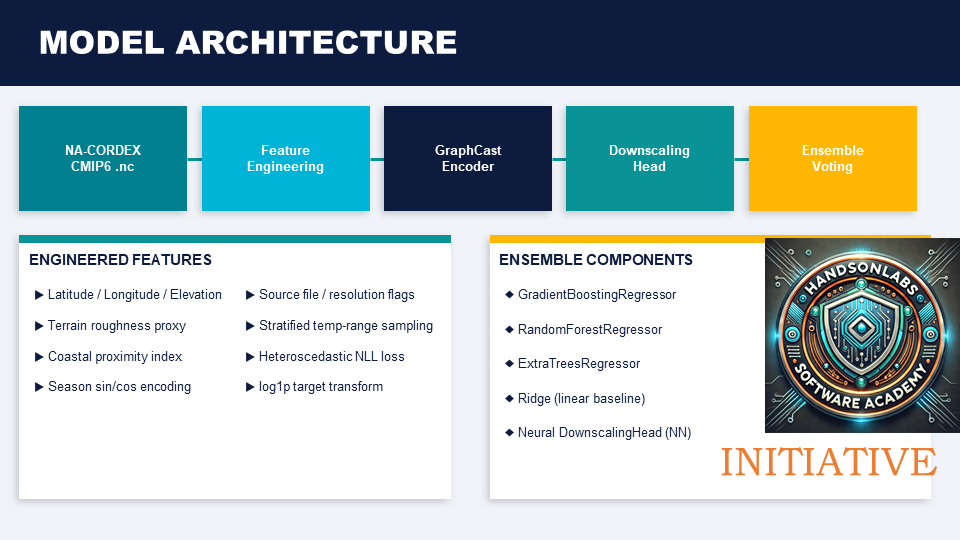
The build process began with data discovery and ingestion, then movesd through feature preparation, scaling, model training, evaluation, and report generation. The earlier pipeline used features like latitude, longitude, seasonal trigonometric transforms, interaction terms, cell level statistics, anomalies, and a fine grid indicator, with mixup augmentation, AMP support, AdamW, ReduceLROnPlateau, and early stopping. The updated code keeps the same structure but is more deliberate and research oriented: it removes sin_lat to reduce multicollinearity, adds terrain and coastal proxies, compares against a local mean baseline, and writes a richer report that records hybrid uplift, spatial vs random cross validation gaps, saved plots, and exported fine tuned artifacts. This reflects a shift from “train a model” to “build a reproducible climate analytics system.”
Challenges we ran into
Key technical pain points had to be solved directly in code. Model stability and training correctness required explicit fixes for training verbosity, RMSE calculation, and the PyTorch AMP API. Controlling bias and leakage in climate evaluation led to stratified sampling, spatial block cross validation, and a local mean baseline to avoid overly optimistic results from random splits. Heteroscedastic loss, uncertainty outputs, and tail fine tuning addressed the broader challenge that climate targets are noisy, skewed, and hardest to model at extremes, forcing the system to become robust to both variance and rare event error.
Accomplishments that we’re proud of
A major achievement is moving from a functional downscaling notebook to a mature pipeline with explicit scientific controls. The updated notebook not only trains a model but produces a structured report comparing hybrid performance to a baseline, tracking two forms of cross validation, saving plots, exporting configuration files, and recording algorithmic changes for full reproducibility. Another accomplishment is the successful integration of GraphCast derived weights first as warm initialization, then as part of a polished hybrid pipeline. This combination of model reuse, uncertainty handling, and baseline aware evaluation signals strong engineering maturity.
What we learned
The evolution of ClimateIQ offers several lessons. First, climate downscaling is about more than model fitting; feature design is critical, especially when correlated geographic variables distort learning (hence removing sin_lat and adding terrain/coastal proxies). Second, evaluation must reflect spatial reality, not just shuffled samples leading to spatial block cross validation and baseline comparisons. Third, uncertainty is not a bonus in climate work; it is part of model specification, which is why the pipeline uses heteroscedastic loss and uncertainty aware outputs. Overall, the notebooks show a progression from general ML competence to climate domain modeling discipline.
What’s next for ClimateIQ: The Climate Downscaling AI Pipeline
The next step is to move from a strong notebook prototype to a broader operational climate intelligence platform. The updated code already points in that direction by exporting standardized model and tokenizer configs, generating detailed reports, and tracking spatial generalizationke y ingredients for deployment, auditing, and extension to new regions. Future expansions will support more variables, more geographies, and more localized decision layers while preserving scientific rigor around uncertainty and validation. In short, the project has moved beyond a simple predictor and is ready to become a reusable climate downscaling framework adaptable to different continents, sectors, and user groups.
Built With
- na-cordex
- python

Log in or sign up for Devpost to join the conversation.