-
-

-
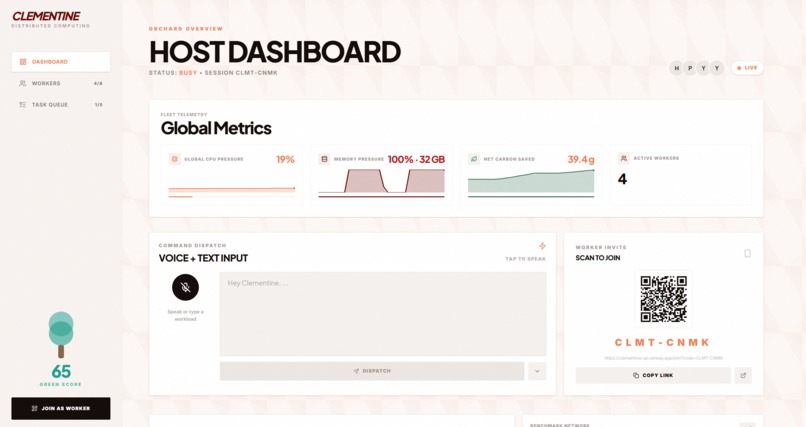
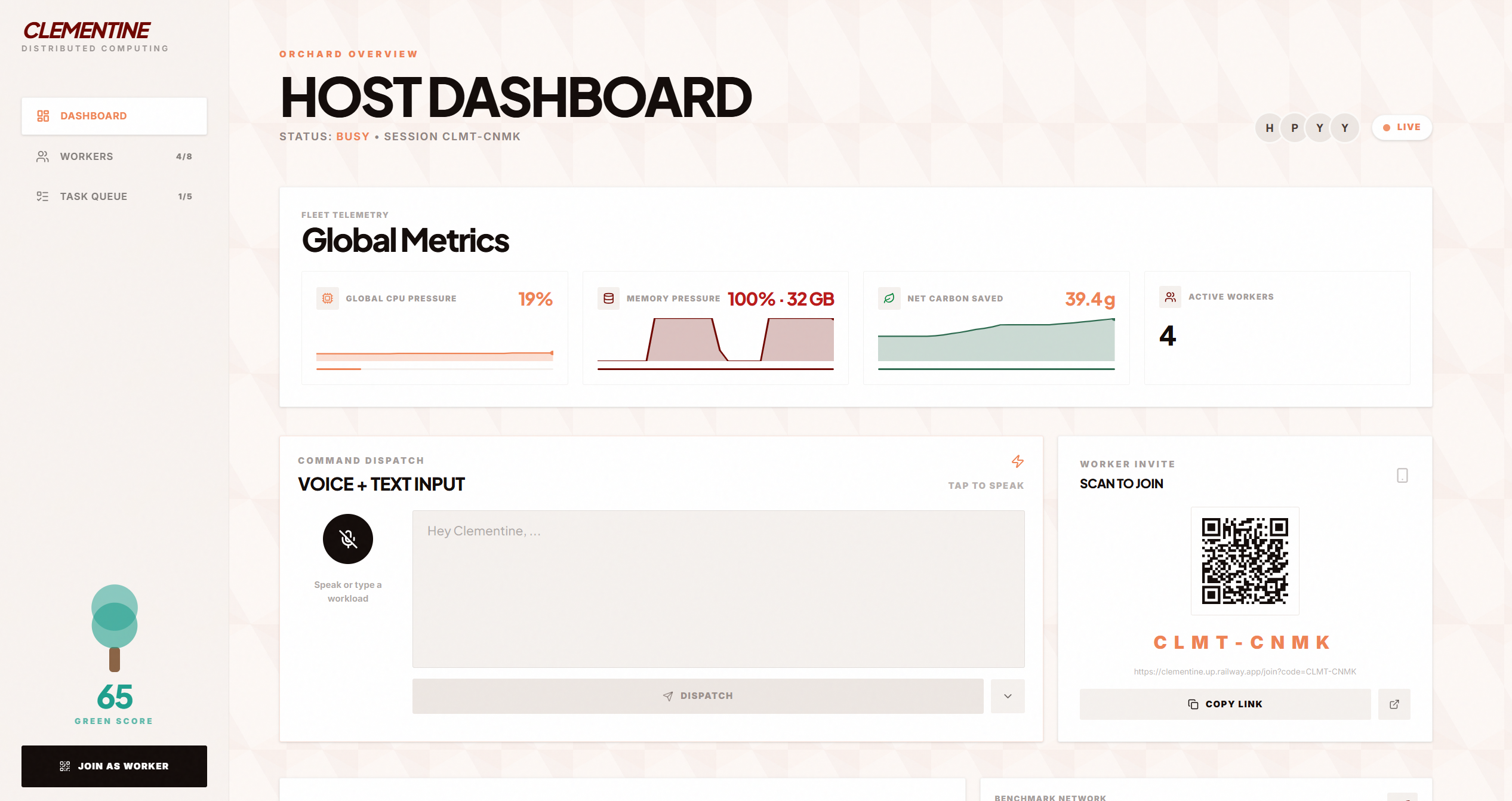
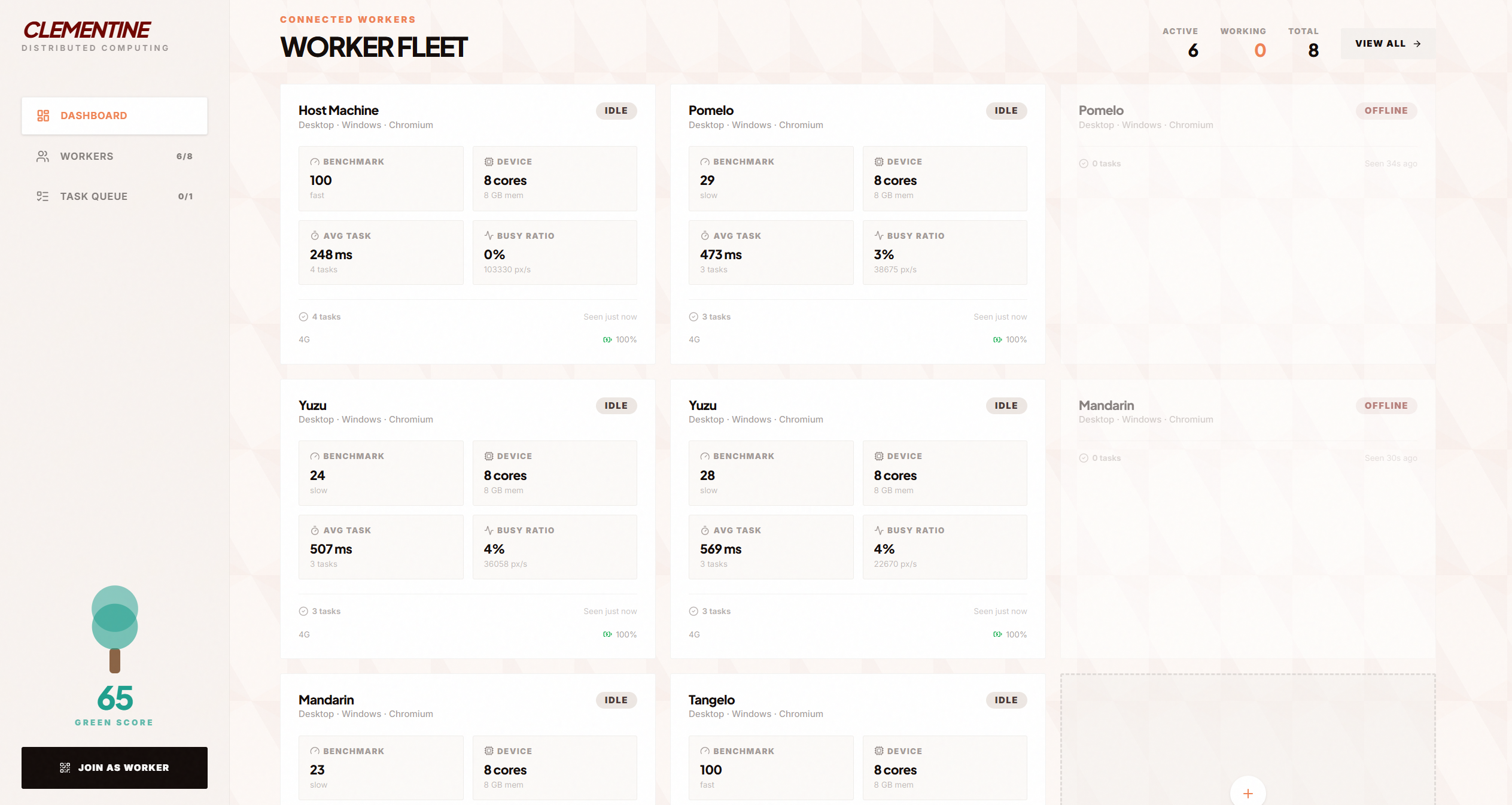
Host Dashboard
-
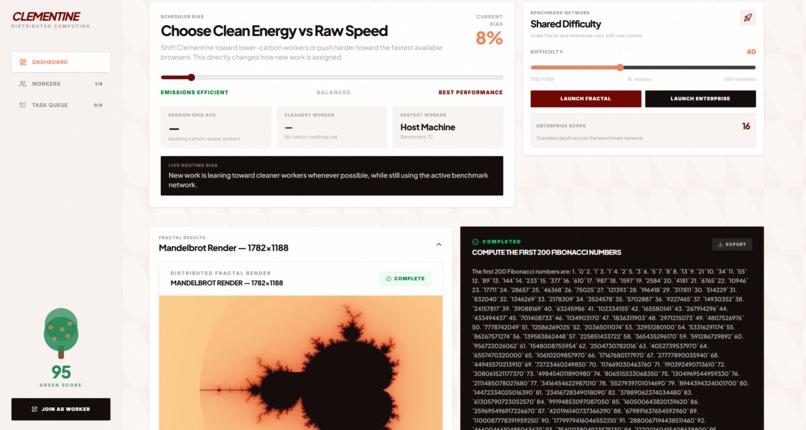
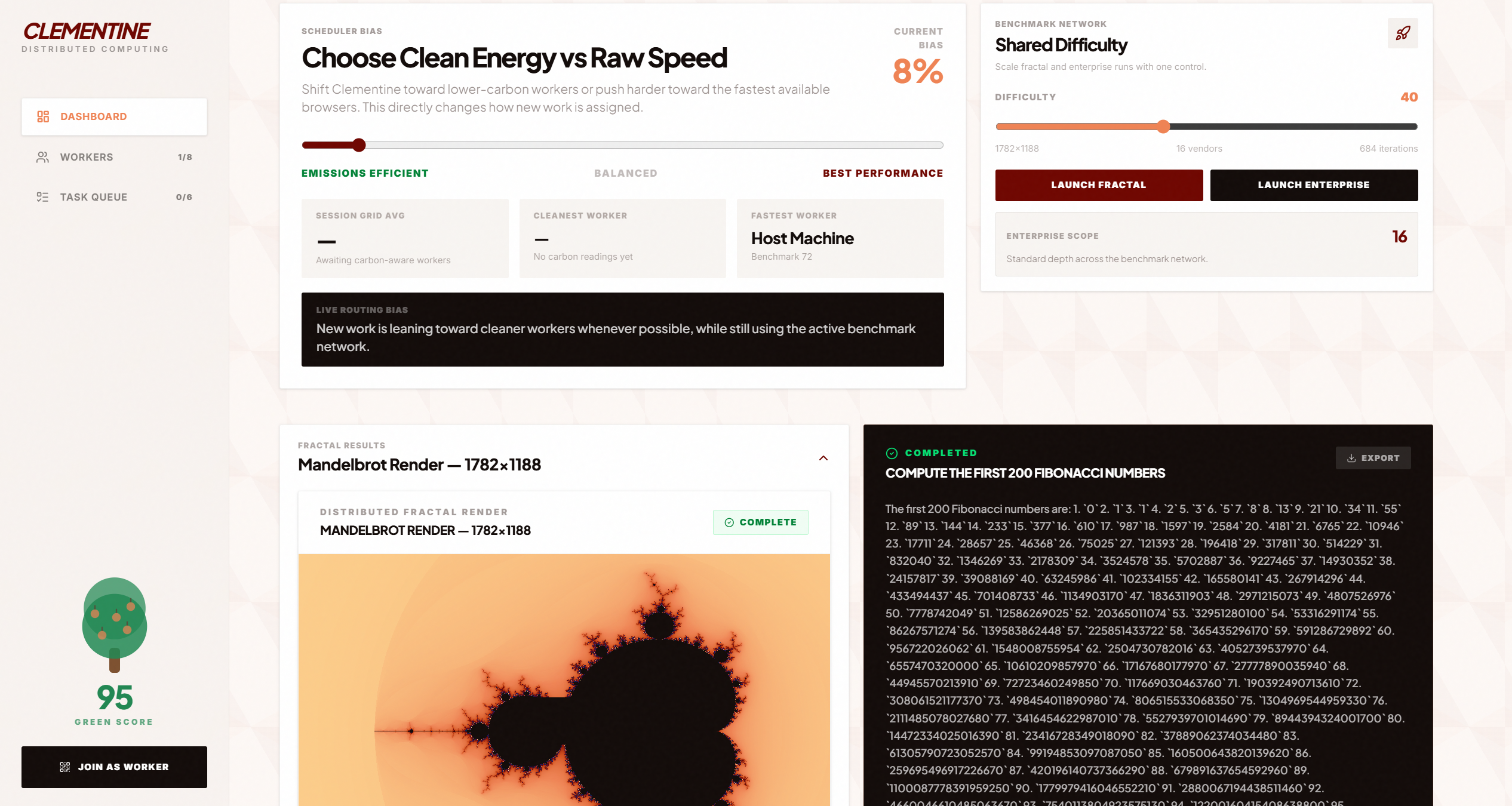
Clean energy bias, Benchmarks, and Outputs
-
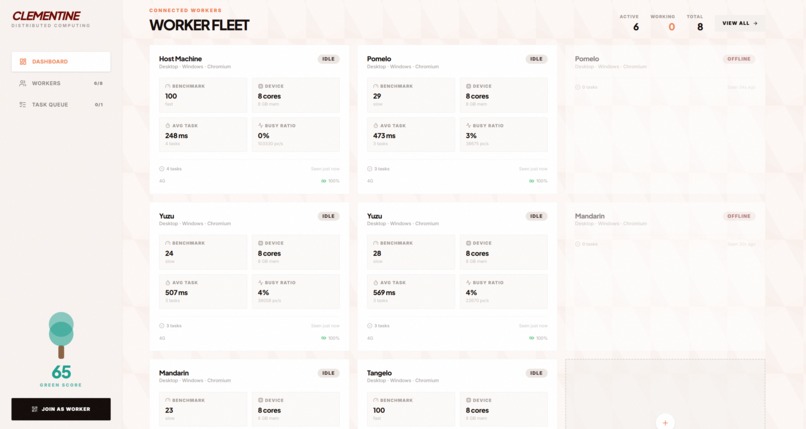
Worker Overview
-
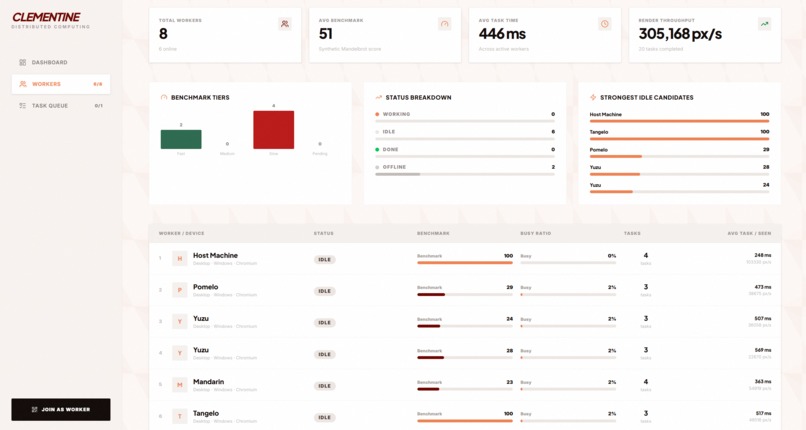
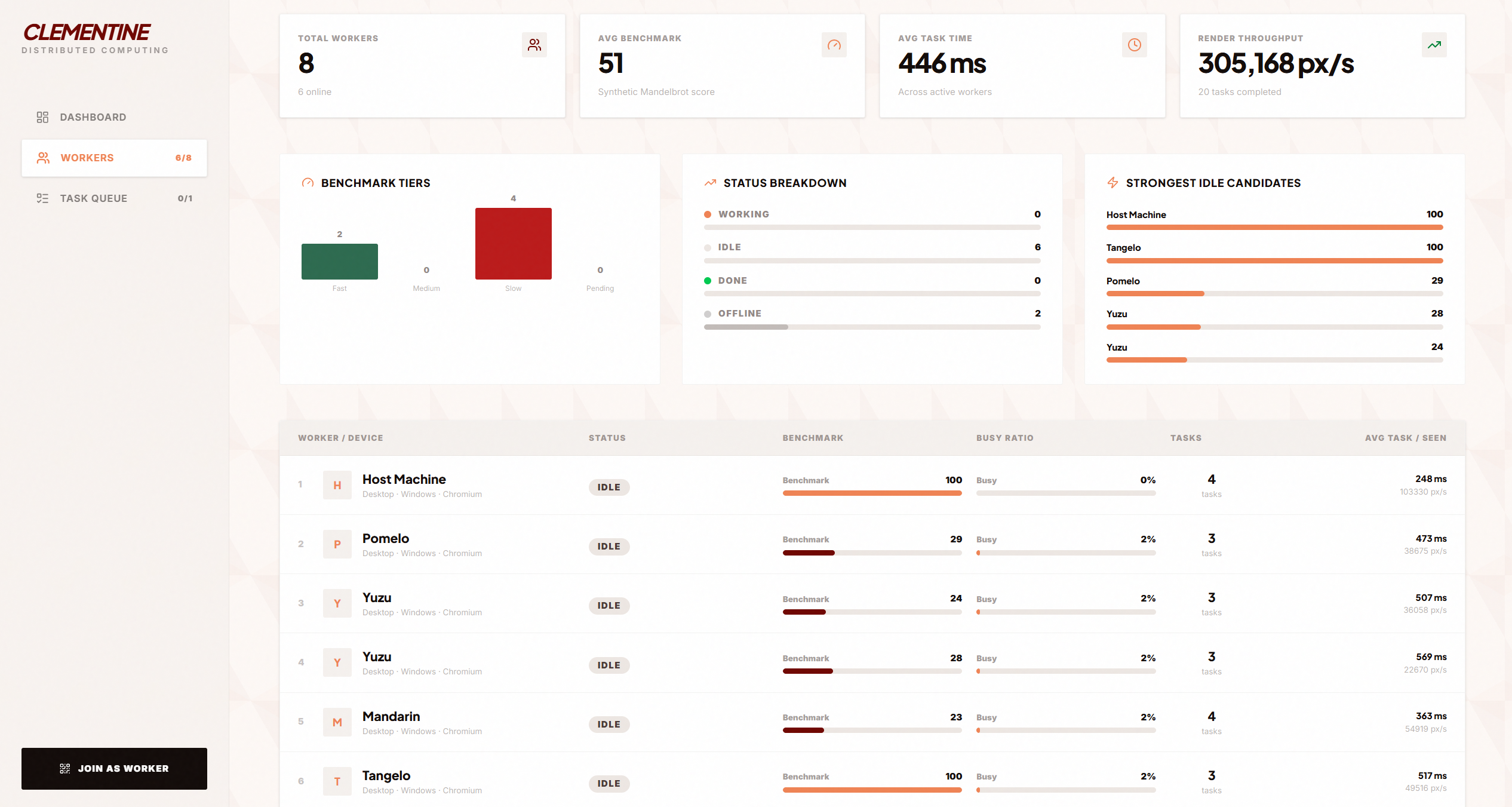
Worker Management
-
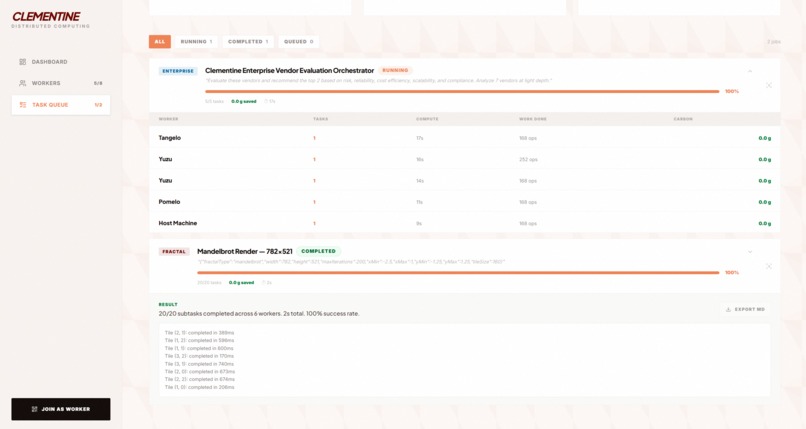
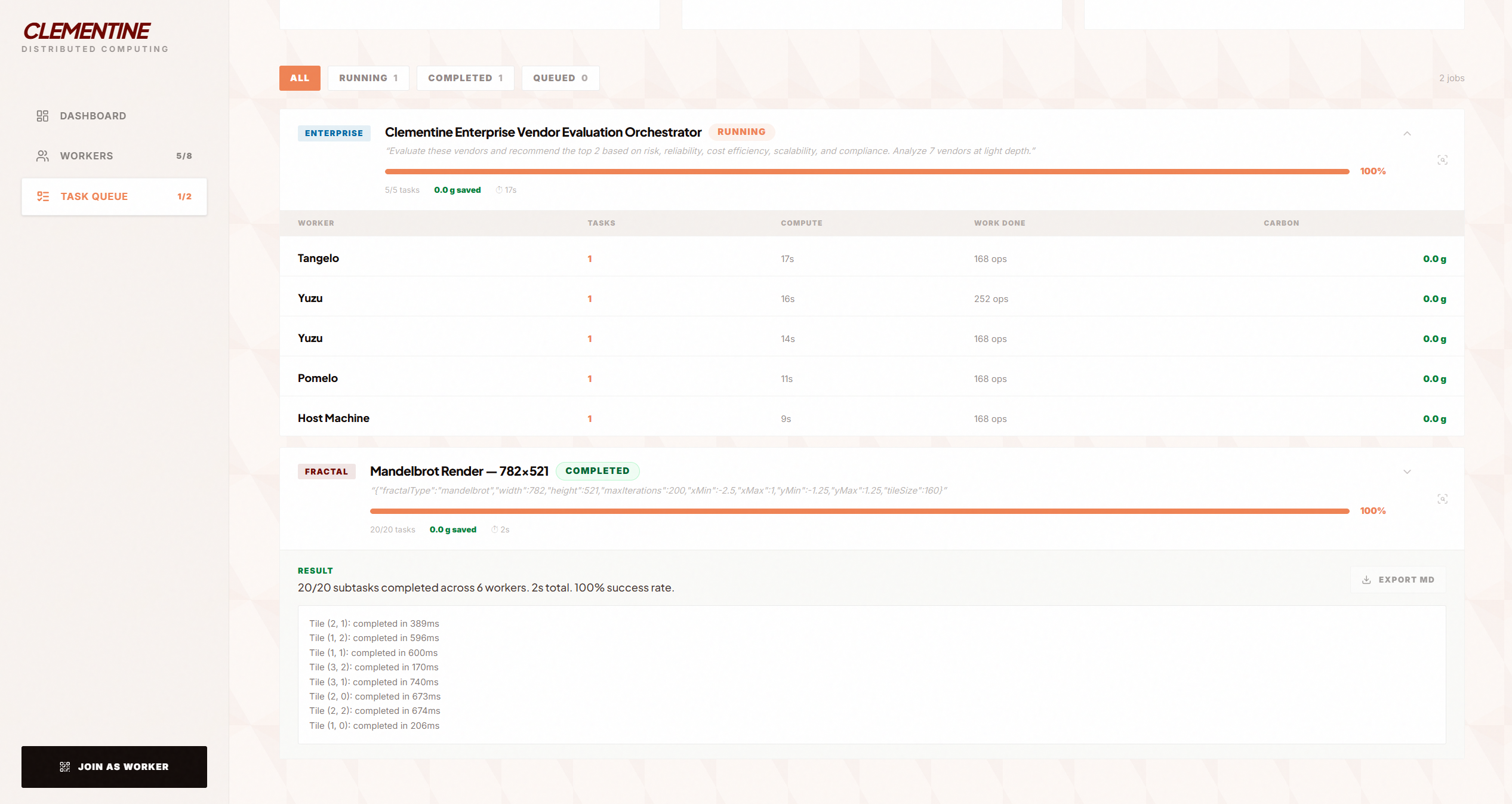
Task Queue
-
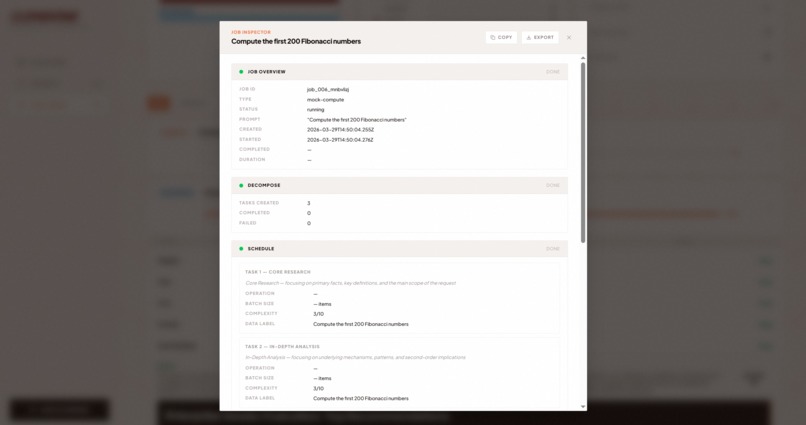
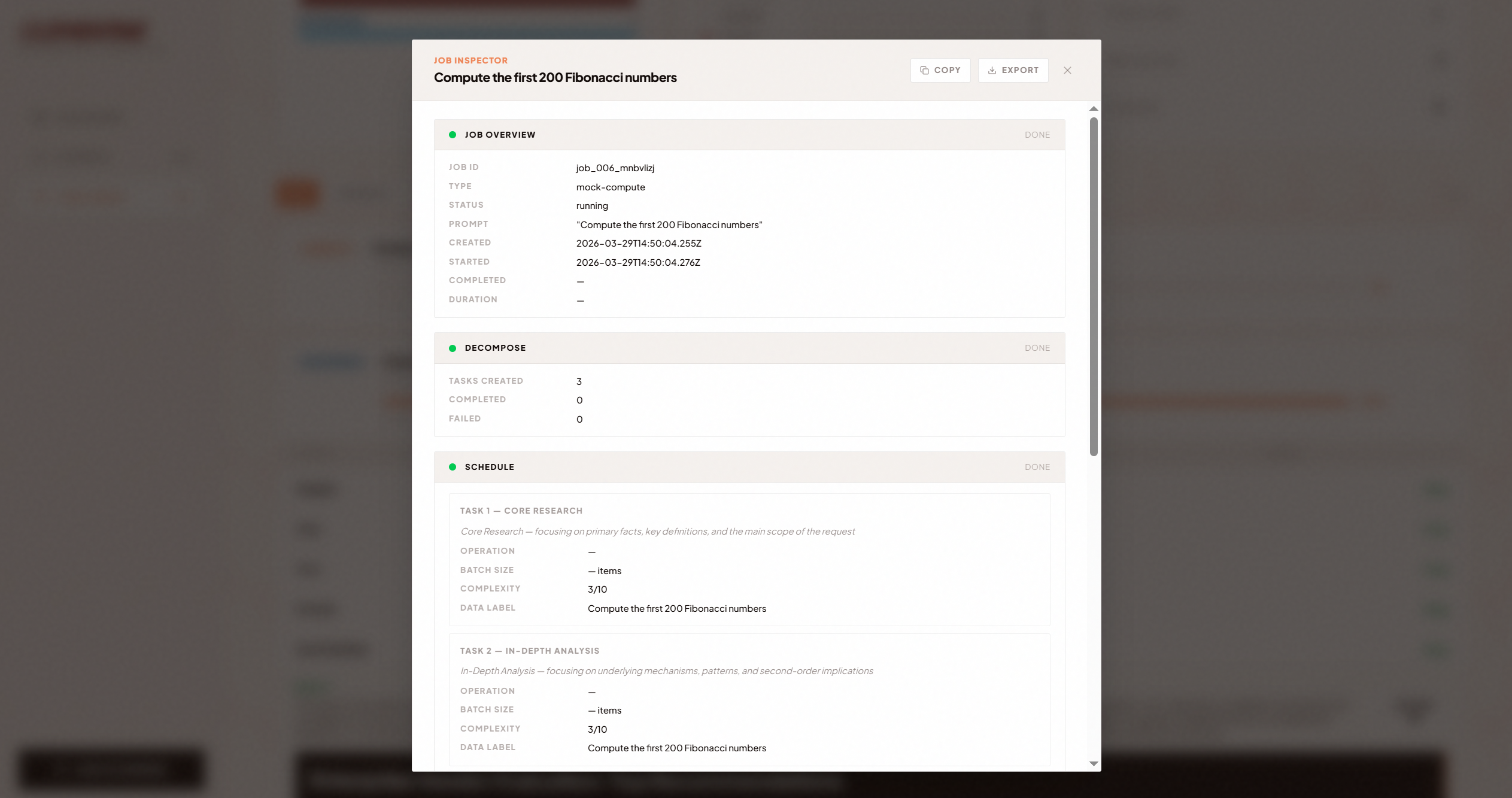
Task Insights

Inspiration
3.7 billion people are still offline or underconnected. But even for the billions who are online, "access" often means a $50 phone with 2GB of RAM — not a machine that can run serious compute.
Meanwhile, cloud computing costs keep rising and data centers now consume up to 4% of global electricity, pulling massive amounts of water for cooling and energy that often comes from fossil fuels.
We kept coming back to one question: what if compute didn't have to be centralized? The hardware to close the digital divide is already sitting in people's pockets, mostly idle. Ten cheap phones pooled together can match the power of a laptop. A student in Lagos could connect their phone to a friend's laptop in London and share its compute instantly.
That's Clementine. We built it because the digital divide isn't just about internet access anymore — it's about compute access.
What it does
Clementine turns any group of devices — phones, tablets, laptops — into a distributed compute cluster, entirely through the browser.
A host opens the dashboard and gets a session code. Workers join by scanning a QR code or typing the code — under 5 seconds from "scan this" to contributing compute. The host dispatches tasks via text or voice, and Clementine handles the rest: decomposing jobs into subtasks, scheduling them across workers by real capability, executing in parallel, and reducing results into a single output.
Key features
- Any device, no install: If it has a browser, it's a compute node
- Intelligent decomposition: AI pipeline splits jobs into real subtasks using K2 Think V2 (low hallucination), then synthesizes final results with Gemini
- Real distributed compute: Fractal benchmarks use actual Mandelbrot computation via Web Workers — not simulated progress bars
- Carbon-aware scheduling: Live data from Electricity Maps lets the scheduler route to lower-emission workers, with a slider to balance green vs. fast
- Voice dispatch: Say "Hey Clementine" and dictate your compute job
- Fault tolerant: Device drops off? Tasks requeue automatically. Host always acts as a fallback worker
- Full observability: See every step from prompt → decomposition → subtask execution → reduction → final artifact
- Private by design: Data never leaves your network
Demo modes
- Fractal benchmark: Mandelbrot rendering distributed across devices with live tile-by-tile canvas streaming
- Enterprise benchmark: Multi-agent vendor risk analysis (1-40 vendors) with role-based analyst subtasks producing a full Markdown report
- Difficulty slider: Scale compute from trivial to intensive to demo with any number of devices
How we built it
Architecture: Custom Node.js server running Next.js 16 and Socket.IO in a single process — one tight orchestration loop, fast iteration, no premature backend splitting.
Real-time: Socket.IO handles host↔worker communication with reconnection and state recovery. Workers survive page refreshes and network drops.
AI pipeline (multi-model, each chosen for a specific failure mode):
- K2 Think V2 for task decomposition — chosen specifically because reasoning traces reduce hallucination during job splitting. Fabricated subtasks = fabricated results that poison everything downstream.
- Anthropic Claude as a fallback decomposition path
- Gemini for final synthesis — one clean pass producing the user-facing result
- LangGraph orchestrating the full lifecycle as a directed graph: decompose → schedule → execute → reduce
Browser compute: Real Web Workers running Mandelbrot computation. Browser telemetry APIs (hardwareConcurrency, deviceMemory, battery, network info) provide honest capability signals — we don't fake OS-level metrics. A synthetic benchmark on join gives each worker a real performance score.
Green scheduling: Electricity Maps API for real-time regional carbon intensity. Scheduler scores workers on both emissions and performance, with host-controlled bias.
Persistence: MongoDB for lightweight session/job/worker snapshots and exportable session dumps. Core orchestration runs in-memory for speed.
Frontend: React 19, Tailwind CSS 4, Three.js (React Three Fiber) for the landing page 3D mesh viz, Framer Motion for polish, react-qr-code for instant onboarding.
TypeScript everywhere: Strict shared types across server, sockets, browser workers, and AI payloads — critical with this many structured payloads crossing boundaries.
Challenges we ran into
Socket.IO state sync was brutal. Workers joining and leaving dynamically while a server orchestrates everything in real-time produces constant race conditions. Worker disconnects mid-task, reconnects 3 seconds later — did the task complete? Requeue? Same session? We rebuilt reconnection logic multiple times.
Browser APIs are a beautiful lie. navigator.deviceMemory returns 8 on a 16GB machine. Battery API is deprecated in some browsers. Network info is Chromium-only. We had to build a composite telemetry layer that gracefully degrades plus a synthetic Mandelbrot benchmark to get real capability scores.
LLMs skip the distributed compute step and just make stuff up. This was the hardest problem. We'd send "analyze risk across 15 vendors" and the model would fabricate a plausible analysis — no decomposition, no subtasks, no actual distributed work. This is why we moved to K2 Think V2: reasoning traces force explicit task splitting, which dramatically reduced hallucinated subtasks. We also had to build sanitization to strip leaked model artifacts (dangling </think> tags, echoed system prompts).
Carbon-aware scheduling with real data. Integrating Electricity Maps meant handling geolocation permissions, async carbon lookups during worker joins, and building scoring that meaningfully balances emissions against compute — not just picking the "greenest" worker regardless of capability.
Accomplishments that we're proud of
- Phones, laptops, and tablets genuinely computing in parallel — fractal tiles streaming live from teammates' devices to the host canvas. Watching a Mandelbrot set assemble from 6 devices is visceral.
- Sub-5-second onboarding tested with people who'd never seen the project. Scan QR → contributing compute.
- Each AI model earns its place solving a specific failure mode we hit during development — not model-hopping for show.
- Real carbon data producing measurably different scheduling behavior when you flip the bias slider.
- Full task transparency from prompt to artifact with no black boxes.
What we learned
- Distributed systems are hard even at tiny scale. Three devices on the same WiFi produce surprisingly complex failure modes.
- LLMs need guardrails for decomposition, not just generation. The failure mode isn't wrong answers — it's skipping orchestration entirely and answering directly.
- Browser APIs are powerful but fundamentally untrustworthy. You can build real distributed compute in the browser, but treat every API as "maybe available, probably lying."
- Green computing is a real design constraint, not a checkbox. Speed-vs-emissions tradeoffs are nontrivial.
- Running Next.js + Socket.IO in one process was the right hackathon architecture call. TypeScript strict mode caught dozens of payload mismatches that would've been silent runtime bugs.

Log in or sign up for Devpost to join the conversation.