The problem
People in crisis can't find the right help. Resource directories use keyword search, so "help" returns a suicide hotline even if you're dealing with domestic violence. Search engines give confident answers. Directories give long lists. Neither asks what you actually need. Neither tells you when it's not sure.
Maria, escaping domestic violence at 2 AM. She types "help" and gets a suicide hotline, not a shelter. She closes the tab. Every wrong result is a lost chance. Someone finally reaches out for help and gets sent to the wrong place. They don't try again. That gap between the right resource and the wrong one? It can be fatal.
What inspired us
We started by watching how social services actually work in the US. 211.org, Benefits.gov, HUD housing locators. We typed real queries into them. "I can't pay rent." "I need food for my kids." "My husband hits me." The results were lists. Long, unranked, often outdated lists. The first result was usually wrong. The right resource was somewhere on page 3, behind a broken link.
We thought: if someone finally reaches out for help, the system they reach should understand what they actually need. Not match keywords. Understand meaning. That's where the idea started.
Who it's for
Maria. And anyone else who finally reaches out for help and gets the wrong answer. We serve 6 cities right now: Houston, New York, Los Angeles, Chicago, Dallas, Miami. National resources like 988 and the Crisis Text Line show up regardless of where you are. The resource database was hand-curated from public 211.org listings, Benefits.gov, HUD, and SAMHSA. No paid data partnership. No API deal. Two high school students, May 2026, every entry verified manually.
Why AI
AI gets meaning, not just keywords. "My husband hurts me" and "I want to end it all" both contain the word "help" but need totally different resources. Natural language inference tells the difference and routes each person to the right place.
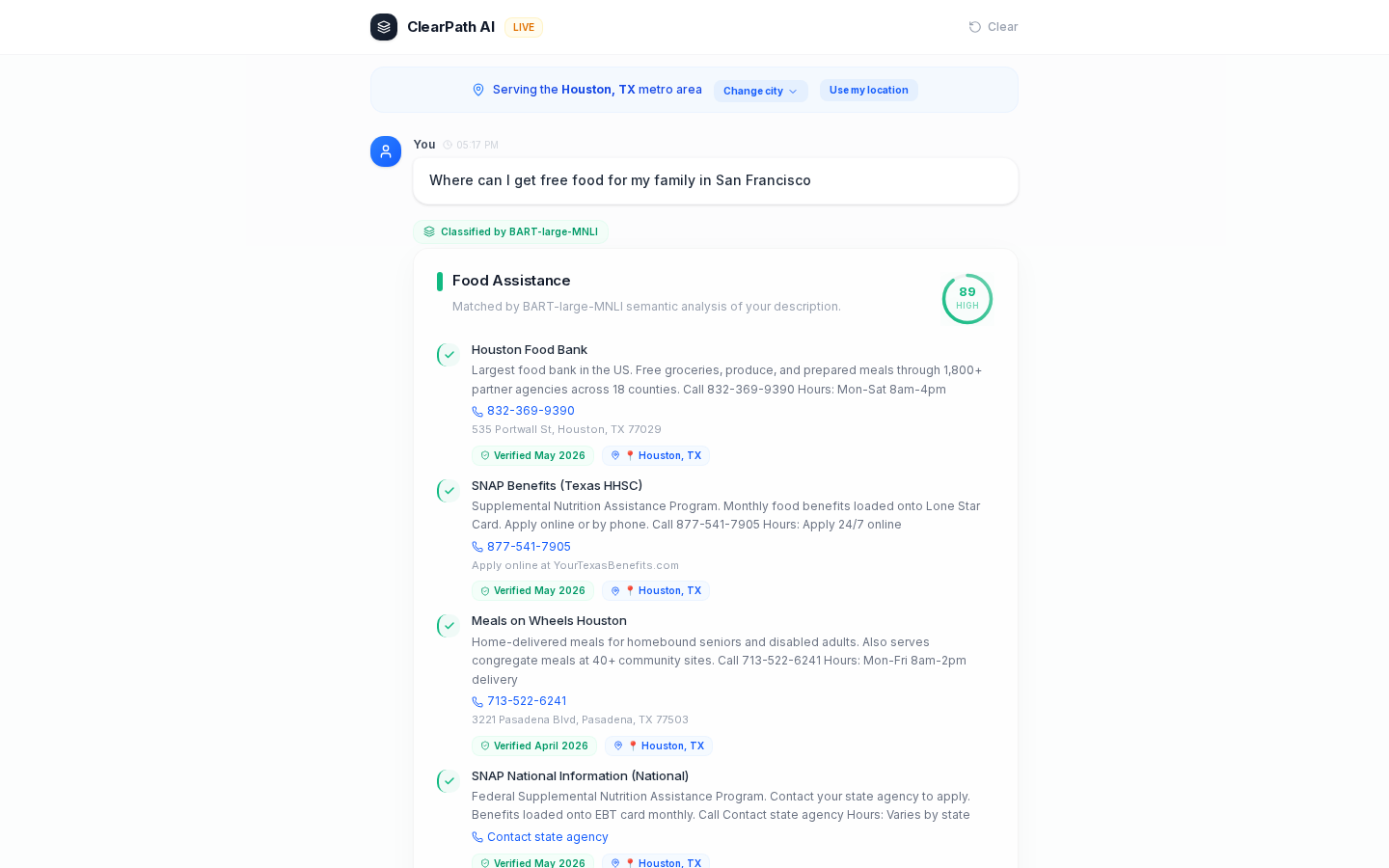
We picked BART-large-MNLI specifically. It's a zero-shot NLI model, no fine-tuning, no training data. We picked it over RoBERTa-MNLI because BART handles longer premise-hypothesis pairs. Our labels aren't single words. The housing label is "rent help, emergency shelter, facing eviction, homeless, housing assistance, can't afford rent, mortgage help." BART scores the input against the full semantic of each label, then we map it back to a short display name like "Housing Assistance."
The 8 categories were derived from the 211.org top-level taxonomy, cross-referenced with the most frequent request types in publicly available 211 impact reports. We started with 7 at qualifier time. During testing we realized Healthcare was too broad. Seniors have Meals on Wheels and Medicare. Veterans have VA-specific programs. Lumping them under Healthcare hid these resources. We split Senior Services and Veteran Services out as their own categories. Crisis Support is not a BART category. It's a regex layer. The AI never sees crisis input.
How it works
You type what's happening in your own words. The system runs a 6-layer pipeline before it shows you anything.
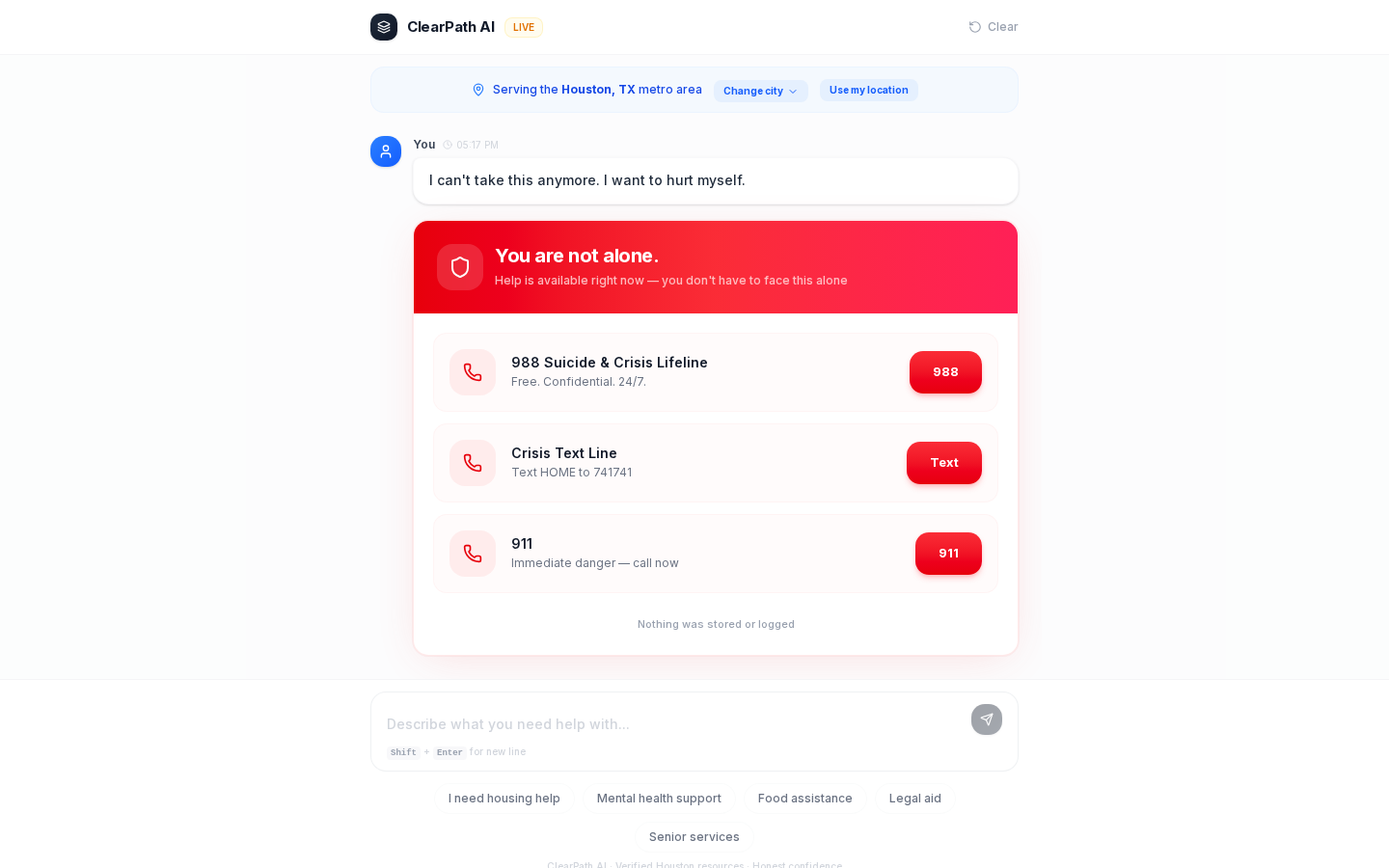
Layer 1: Crisis detection. 185 regex patterns, 9 crisis sub-types. Suicidal ideation, self-harm, domestic violence, sexual assault, child abuse, elder abuse, weapons, homicidal ideation, medical emergencies. This runs first. If it matches, the AI is bypassed entirely and the right crisis line shows up. Crisis routing cannot depend on a probabilistic model.
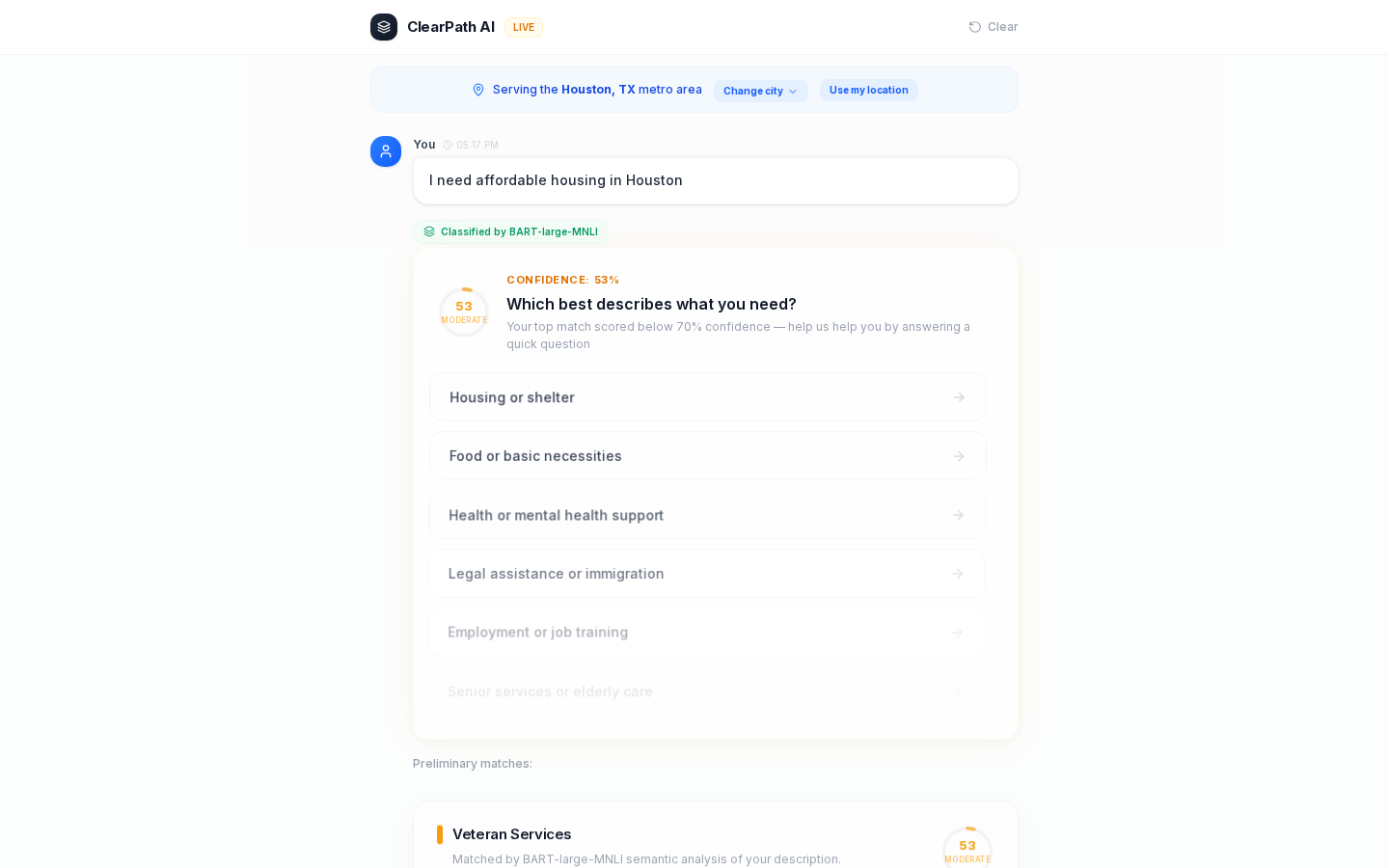
Layer 2: Vague input detection. If you type "hi" or "test" or "help" alone, we don't call BART. Zero-shot models produce false confidence on meaningless input. We ask you to describe your situation in more detail.
Layer 3: Injection detection. XSS, SQL, prompt injection, repeated-character spam. Rejected before BART.
Layer 4: Multi-label classification. BART-large-MNLI via HuggingFace Inference API, multi_label=true, against 8 descriptive labels.
Layer 5: Confidence gate. Above 70%, the top match gets a "recommended" badge. Below 70%, no badge. The system asks a clarification question specific to the top category. Multi-label threshold is 10%. Any category scoring 10% or higher shows up alongside the top match, up to 5 categories. "I lost my job and can't pay rent. My kids need food." is not one problem. We show Employment, Housing, and Food at the same time. No need gets silently dropped.
Layer 6: Human escalation. We don't auto-dial. We show phone numbers as tel: links. The user clicks. The user calls. A real person has to be the one helping.
Three-tier fallback on the BART call. Raw fetch, then HuggingFace SDK, then keyword match. When the API is down, the UI badge says "Keyword match. BART AI not connected." No pretending.
Challenges we ran into
The regex was harder than expected. "I want to die" is obvious. "I don't want to be here anymore" isn't. "I'm dying" can mean a medical emergency or "I'm dying laughing." We had to add negative lookaheads. The list is 185 patterns after many iterations.
BART's raw scores look confident even when wrong. We chose a hard 70% threshold for the recommended badge. Below it, the result shows but the system asks a clarification question. We also dampen single-match Mental Health scores in the keyword fallback by 0.7, because "stress" alone shouldn't route someone to therapy.
HuggingFace's free tier is unstable under load. We added a three-tier fallback, a 15-second timeout on each fetch, and a single 20-second retry on 503. When all three fail, the user sees the keyword match badge. They know what they're getting.
What we tested
Before submitting, we ran a 1,000-bot stress test against the classify endpoint. Each bot had a different input and persona. Some typed crisis language. Some typed vague input. Some tried injection. Some sent non-English text. Some typed realistic resource requests. About 4,400 requests total. HuggingFace cost: $0.08.
The stress test caught real bugs. Crisis patterns we had missed. Healthcare label too broad. Vague detection too aggressive on single question words. Each fix is in the git history. Commits "expand crisis detection + vague patterns based on 1000-bot stress test" and "1000-bot stress test findings" document what changed.
What we learned: a single missed crisis pattern can route a survivor to the wrong hotline. The regex list is the part of the system where one missing pattern can cause real harm. That's why we kept iterating on it.
Accomplishments we're proud of
The fallback badge. When BART is unavailable, we don't pretend. The UI badge reads "Keyword match. BART AI not connected." The classification source is exposed in the response object: classificationSource: 'bart' | 'keyword' | 'vague-detection'.
The crisis type detection. A self-harm input gets 988 first. A domestic violence input gets the National Domestic Violence Hotline first. A medical emergency gets 911 first. The system doesn't treat "crisis" as one bucket.
The vague input interception. Zero-shot models always return high scores, even on "hello." We refuse to call BART on input that has no semantic content.
What we learned
Responsible AI isn't a section in a form. It's a thousand small decisions: showing the real score, refusing to call BART on vague input, rejecting injection attempts, falling back honestly when the API is down, displaying a human hotline number no matter what. Each one is small. Together, they're the product.
We also learned that the model isn't the system. The system is the model plus the regex plus the vague-input filter plus the injection filter plus the multi-city geolocation plus the resource database plus the confidence gate plus the clarification flow. The model is one piece. The interesting engineering is in how the pieces refuse to trust each other.
What's next
More cities. Spanish language support. The Houston Spanish-speaking population needs this. A version for hotline operators themselves, so the person picking up the call already knows what the caller typed. A proper calibration dataset for the dampening factors. Right now they're heuristic, not derived from held-out evaluation data. But the core stays: type what's wrong. Get the right resource. Real confidence score. A human stays in the loop. That's it.
Built With
- bart-large-mnli-(facebook/bart-large-mnli
- framer-motion
- huggingface-inference-api-(@huggingface/inference)
- lucide
- next.js-16
- prisma-orm-(sqlite)
- radix-ui-toast
- react-19
- tailwind-css-4
- typescript
- vercel
- zero-shot-nli)


Log in or sign up for Devpost to join the conversation.