-
-

ClearGBM - Interpretable gradient boosting
-
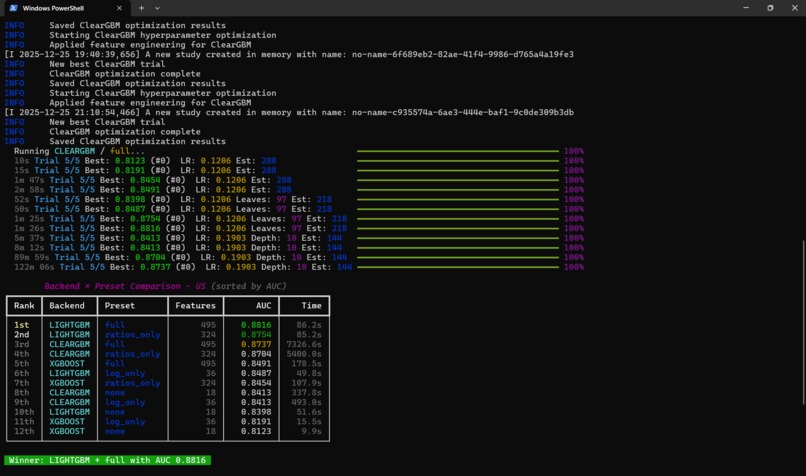
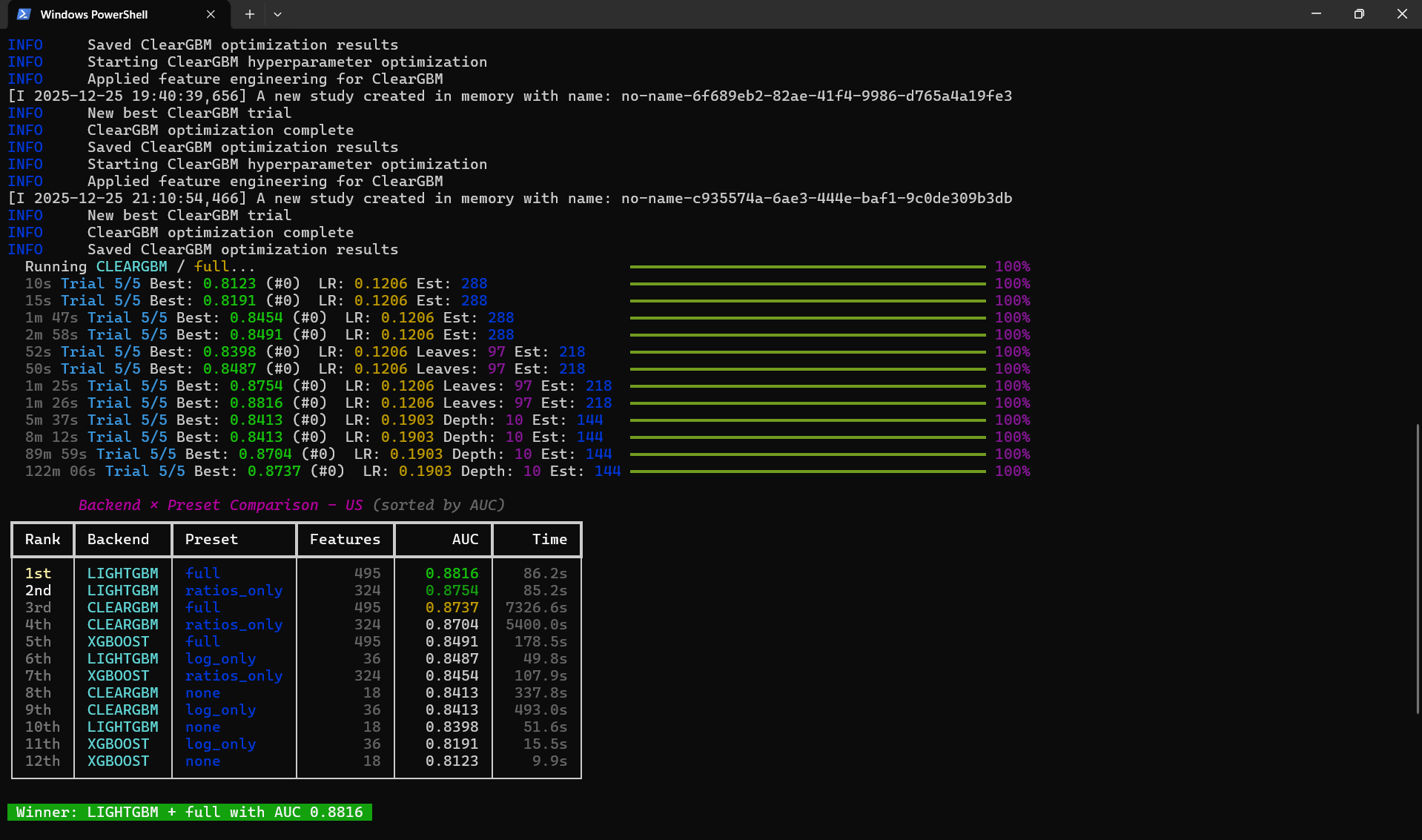
ClearGBM comparison against existing models: XGBoost, and LightGBM

ClearGBM — Interpretable Gradient Boosting
Inspiration
I wanted to understand how gradient boosting actually works, not the API, but the math and mechanics underneath.
What it does
ClearGBM is a gradient boosting machine built from scratch in pure Python with zero dependencies. Every prediction includes the exact rules and feature contributions that produced it.
How I built it
Started with binary log loss and its derivatives. Built decision trees that use gradients to find optimal splits. Added the boosting loop where each tree corrects the previous. Implemented histogram binning to bucket values into 64 bins for faster splits. Added sibling subtraction to derive child histograms from the parent. Built rule extraction and feature contribution tracking on top.
Challenges I ran into
Zero dependencies meant no numpy arrays, so everything is tuples and pure stdlib. No sklearn metrics, instead I wrote our own AUC. Every piece had to be understood and implemented, not imported.
Accomplishments that I'm proud of
Strict mypy typing with 100% test coverage. Histogram optimization that matches LightGBM's approach. Readable rule extraction like debt_ratio > 0.4 AND coverage ≤ 1.2. A complete model where every prediction can be fully explained.
What I learned
How gradient and hessian sums determine optimal splits. Why histogram binning reduces complexity from O(n \log n) to O(k). How L1 regularization soft-thresholds leaf values. The mechanics behind every "magic" library call.
What's next for ClearGBM
Multi-class classification. Regression support. GPU acceleration while keeping the pure Python fallback.


Log in or sign up for Devpost to join the conversation.