Inspiration
Here is something that bothers us. India actually has strong consumer protection laws. The Consumer Protection Act 2019 lets you file complaints for free if the amount is under Rs 5 lakh. DGCA has a dedicated portal for airline grievances. IRDAI has one for insurance. These systems exist and they work.
But nobody uses them.
Not because people don't get cheated. They do, all the time. Late deliveries, cancelled flights with no refund, insurance claims that get rejected for no clear reason. The problem is that the distance between "this company screwed me over" and "here is my formal complaint citing Section 39 of the CPA 2019, filed on the correct portal" is just too large for a regular person to cross. You don't know which authority handles your case, you don't know what law applies, and you definitely don't know how to write something that carries legal weight. So you tweet about it, maybe argue with customer support for a week, and eventually just drop it.
We wanted to build something that actually closes this gap. Not a chatbot that tells you "you can file a complaint on consumerhelpline.gov.in" and leaves you hanging. Something that writes the complaint for you, tells you exactly where to file it, and explains your rights in language you can actually understand. And we wanted all of it to run on your own machine because if you are filing a complaint, you are sharing personal details (order IDs, amounts, what happened), and that should stay with you.
What it does
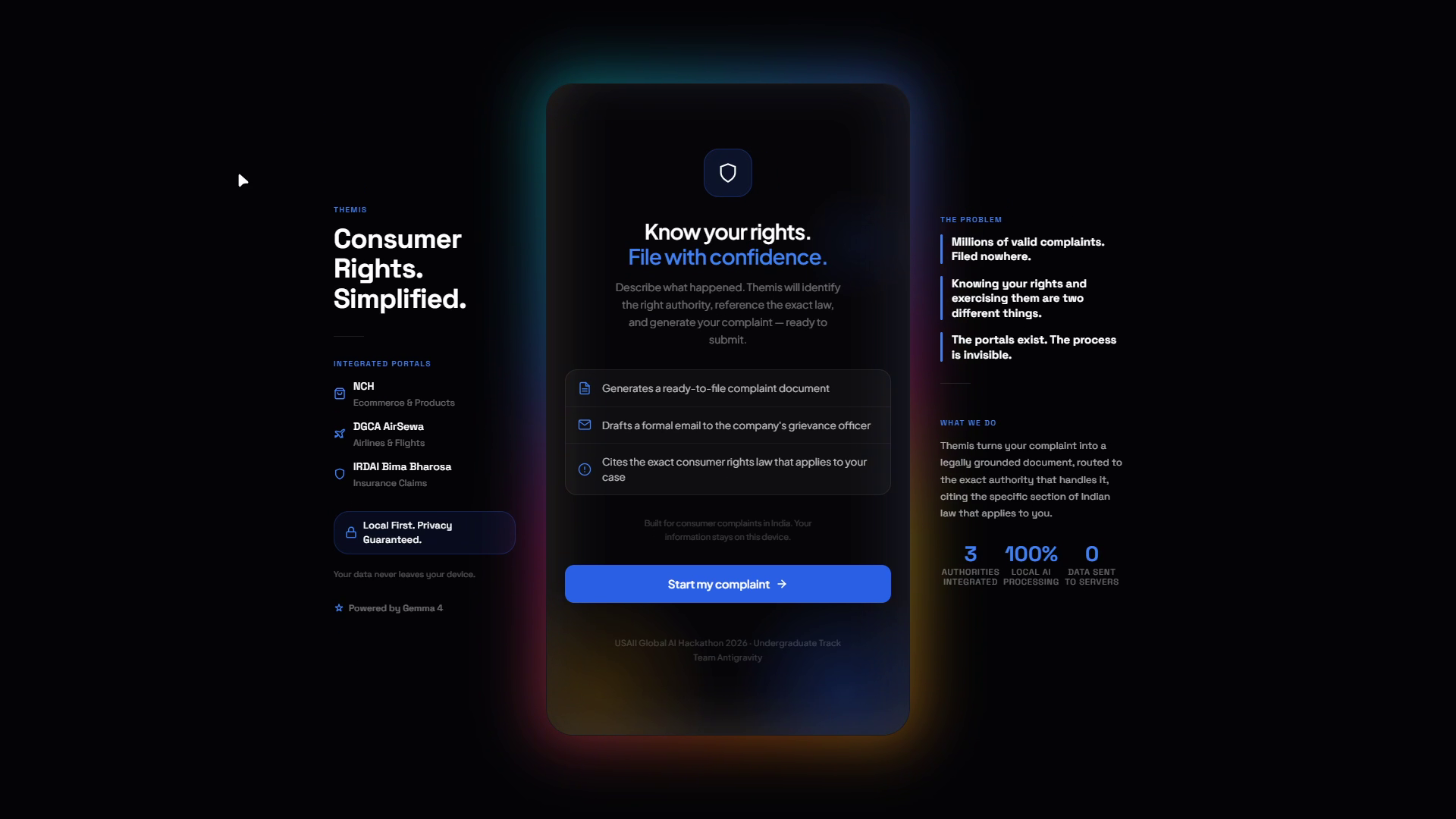
THEMIS is an AI consumer rights complaint assistant for India. You tell it what went wrong in plain language, and it handles the rest.
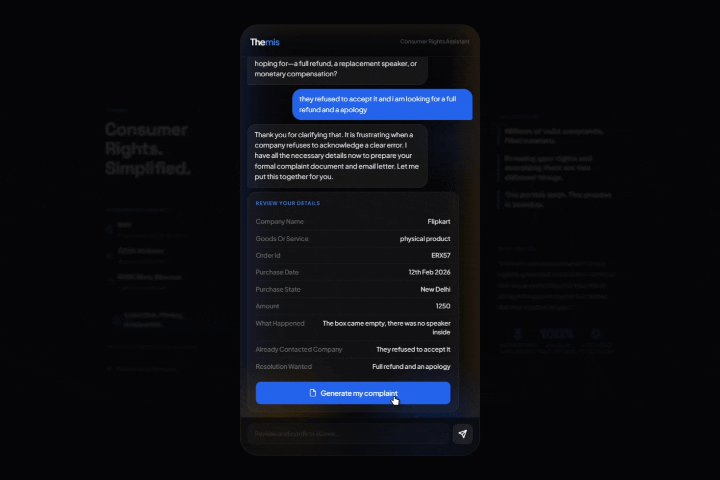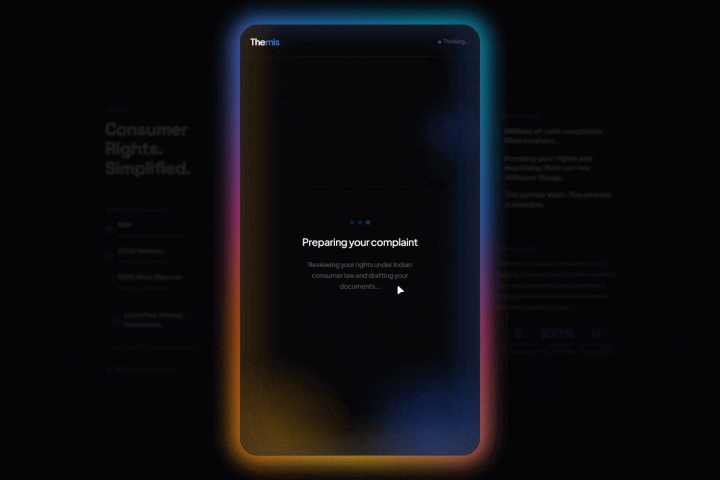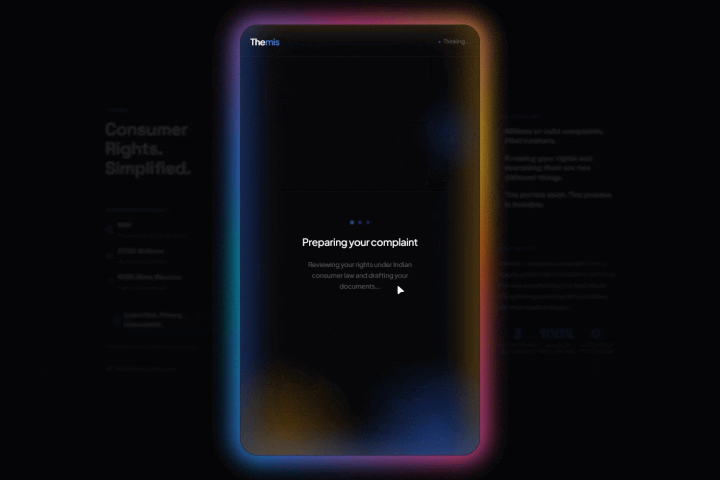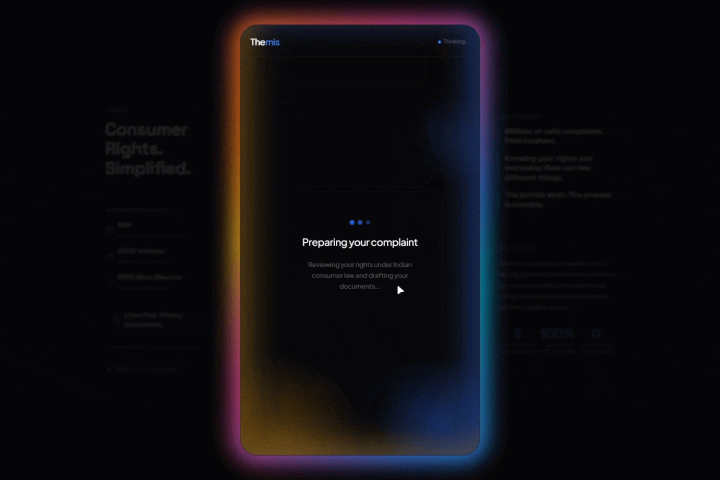
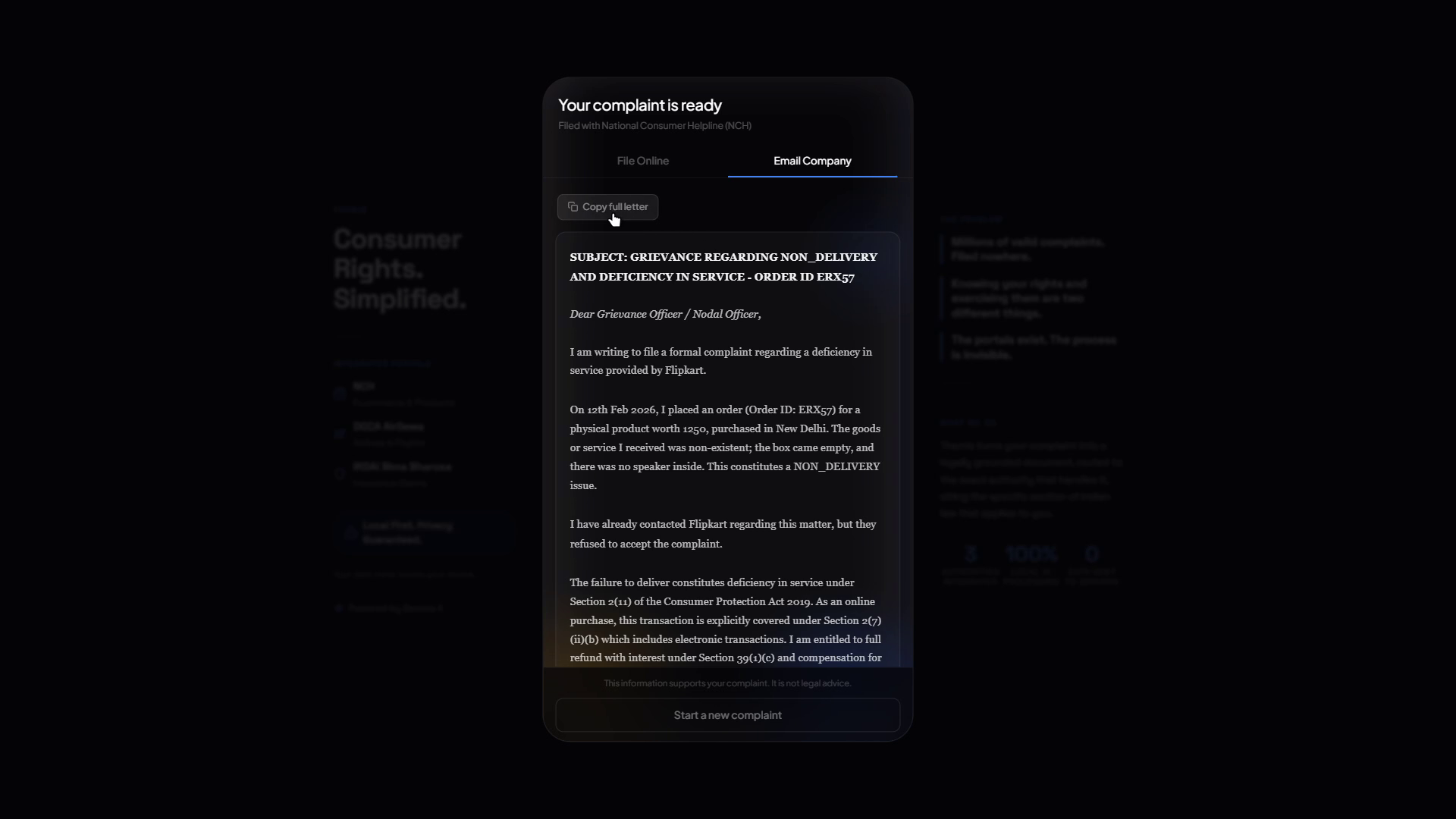
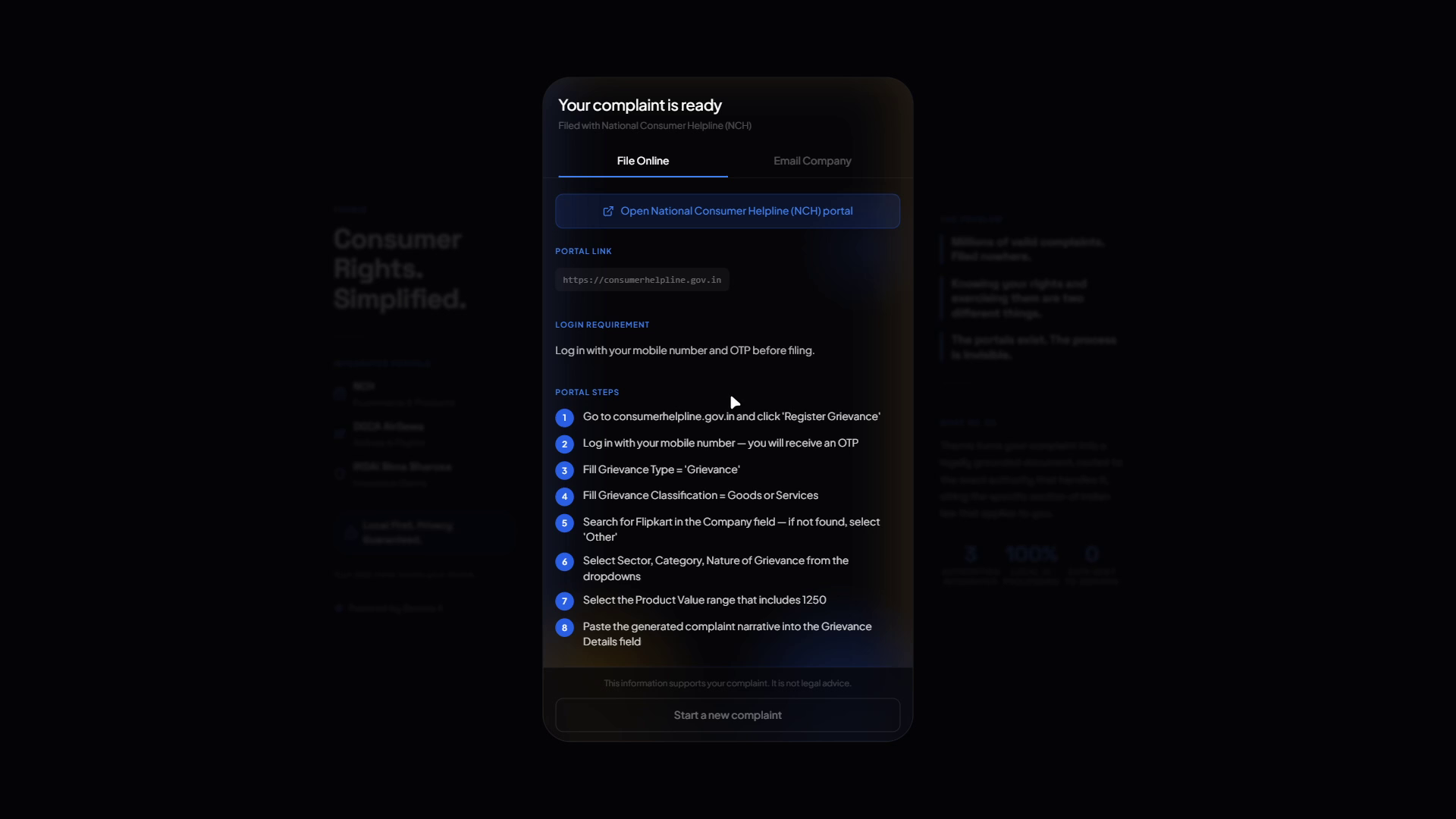
It identifies which of three authorities handles your case: National Consumer Helpline for ecommerce, DGCA AirSewa for airlines, or IRDAI Bima Bharosa for insurance. Then it collects the details it needs through a conversation (not a form). Once you confirm everything looks right, it generates three things:
- A portal submission guide with step-by-step instructions and a paste-ready complaint narrative citing the specific sections of Indian law that apply to your situation
- A formal complaint email to the company's grievance officer, referencing exact legal provisions
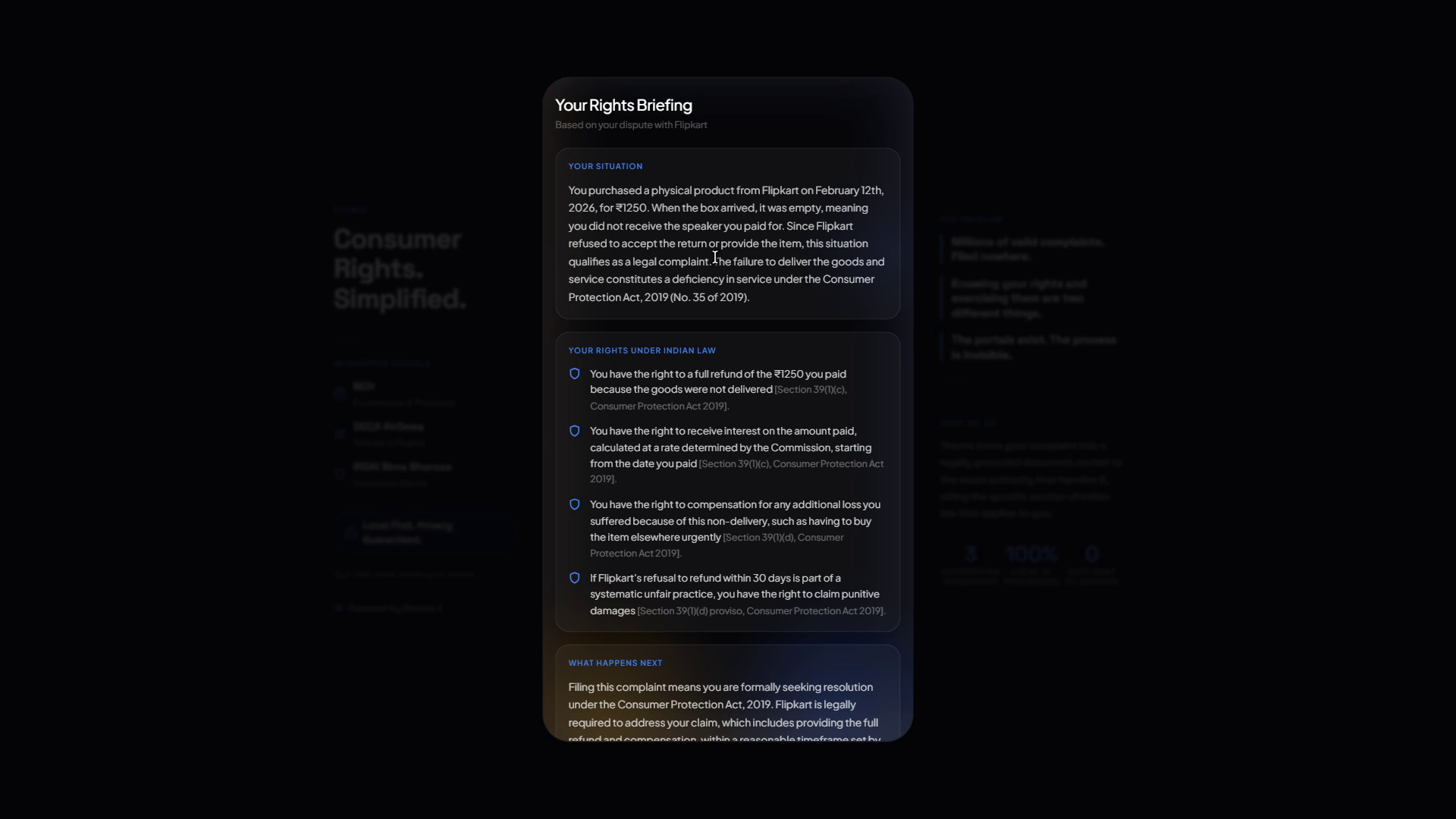
- A personalized rights briefing explaining what you are legally entitled to, written for a normal human, not a lawyer
Every single legal reference comes from a knowledge base we built by reading actual statute text. The model never generates legal content from its training data. That was a hard line for us from day one.
How we built it
Frontend is React + Vite + Tailwind, mobile-first because most people in India will use this on their phones. Framer Motion for animations. Backend is Node.js + Express, three routes, completely stateless, no database.
The interesting part is the AI layer. We run Gemma 4 E4B locally through llama.cpp with CUDA on an RTX 3050 (6GB VRAM). The quantized model fits entirely on GPU at ~3.5GB and generates 20-35 tokens/second. No cloud, no external API calls, everything on localhost.
The conversation flows through five states: INTAKE (describe your problem), CONFIRM (we show which authority handles it), COLLECT (model gathers required fields conversationally), REVIEW (you verify everything), GENERATE (documents are produced). State lives on the client, backend is stateless.
One thing we are really happy with: the model never outputs JSON. We tried it early and Gemma would break JSON formatting unpredictably. So we built a plain-text signal system where structured data is embedded as simple tags like CLASSIFICATION: IN|ecommerce|Flipkart or [FIELD: order_id = ORD123], parsed with basic string operations on the backend. It sounds low-tech but it literally never breaks.
The knowledge base was honestly the hardest part. We went through the Consumer Protection Act 2019, DGCA CAR Section 3 Series M Part IV (Rev 4, Jan 2023), and IRDAI Policyholder Protection Regulations 2017. Every entitlement, section reference, and legal phrase in the generated output traces directly back to these statutes. 13 issue types across 3 domains, each with legal basis, entitlements, what you need to prove, and exact phrases usable in legal filings. Built from primary sources, not summaries.
We also use four separate system prompts (intake, collect, generate, rights) each doing one narrow job. Splitting them made outputs significantly better than one big prompt trying to do everything.
Challenges we ran into
Gemma with reasoning mode would sometimes spend its entire token budget thinking and return literally nothing. Empty response, conversation just dies. We had to cap maxTokens at 2048 on every call and build explicit empty-response handling with retry logic.
The intake classifier kept asking unnecessary follow-up questions instead of recognizing obvious company names. Fixed it by hardcoding a comprehensive list of known Indian companies into the prompt so it classifies immediately when it sees "Flipkart" or "IndiGo" or "LIC."
The halo effect on the frontend (a rainbow conic gradient spinning around the phone frame during AI processing) uses CSS Houdini @property to animate a custom angle variable. Getting blur, opacity, and speed to transition smoothly between idle, welcome, and thinking states took way more iterations than expected.
Accomplishments we're proud of
It works. End to end. On a college student's laptop with a 6GB GPU. You describe a problem, go through the conversation, and get actual complaint documents with correct legal citations. No cloud, no API keys, no paid services.
The legal knowledge base is not a demo. It is genuinely usable. And the UI honestly does not look like a hackathon project. The thinking halo, ambient orbs, card animations, desktop three-column layout with fading sidebars. We put real effort into making this feel like something you would trust with a serious complaint.
What we learned
Local AI is genuinely viable for real applications if you design around the model's strengths instead of fighting its limitations. Text signals instead of JSON, focused prompts instead of mega-prompts, aggressive token budgets. All of these came from learning what a 4-billion parameter model can and cannot do reliably.
Also: the hardest part of building a legal tech tool is not the tech. It is reading actual law and turning it into structured, verifiable data. That took more hours than writing code.
And something that stuck with us: India's consumer protection infrastructure is actually solid on paper. The portals exist, the laws have teeth, the fees are low. The problem is purely access and knowledge. That is exactly the kind of gap AI should be filling.
What's next
Ecommerce, airlines, and insurance are just three domains. India has dedicated redressal for banking (RBI), telecom (TRAI), real estate (RERA), and more. THEMIS is architected to scale: adding a new domain means adding an authority config and a rights database entry.
We also have a reserved integration for SearXNG (privacy-respecting search) to look up company grievance officer emails and recent resolution patterns in real time, all locally.
The vision is simple: if a company wrongs you in India, you should be able to open THEMIS, say what happened, and walk out with everything you need to hold them accountable. No lawyer needed, no confusion, no giving up.
Built With
- cuda
- express.js
- framer-motion
- gemma-4
- google-fonts
- llama.cpp
- ngrok
- node.js
- react
- tailwind-css
- vite
- wsl-2


Log in or sign up for Devpost to join the conversation.