-
-
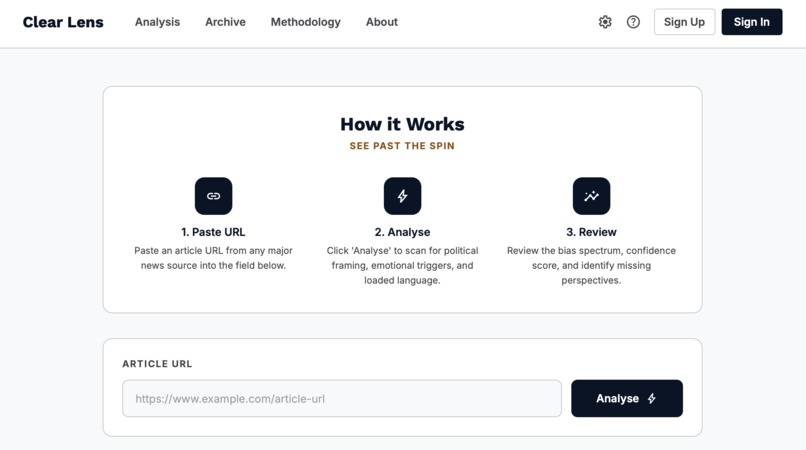
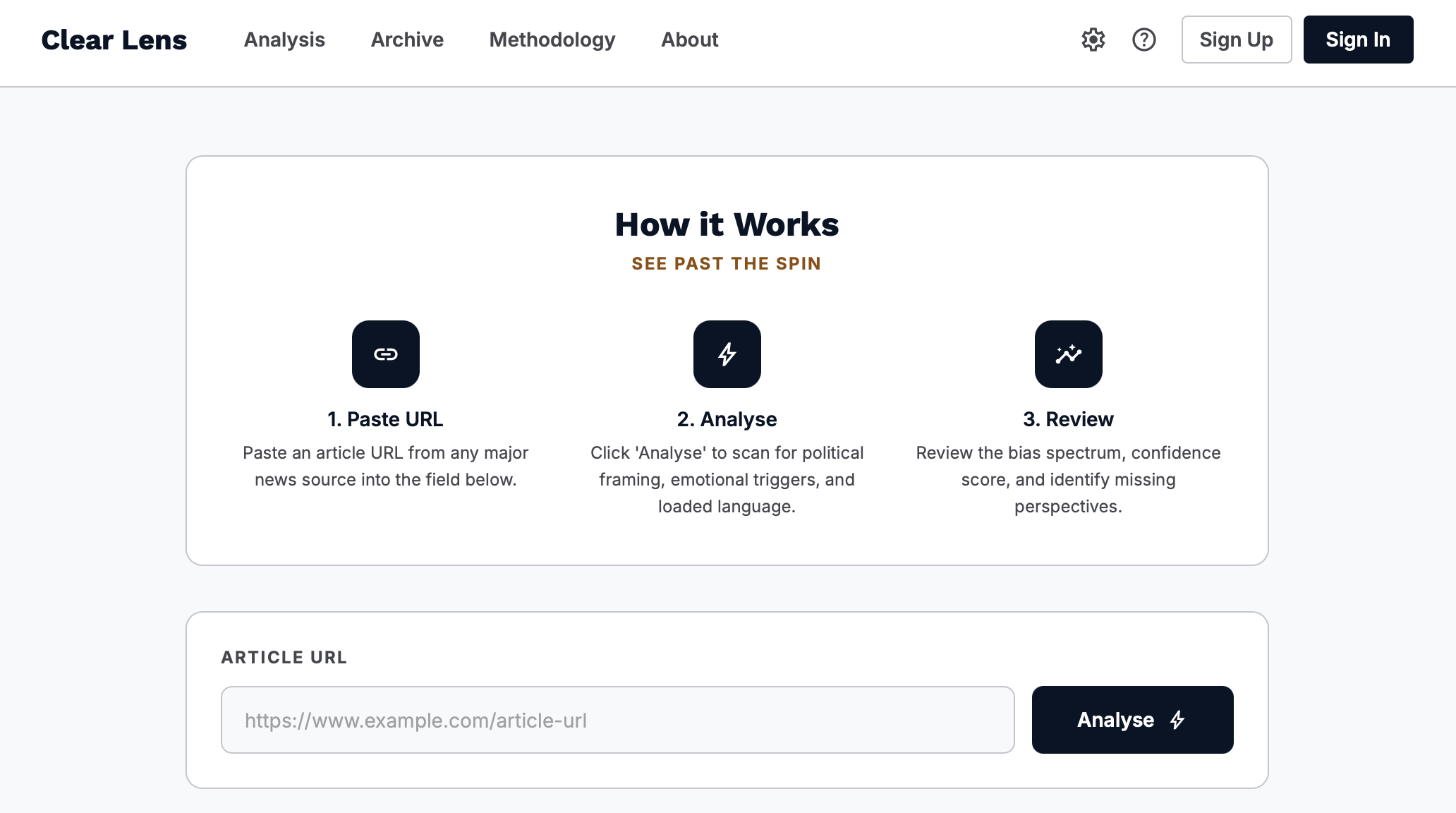
Paste any article URL in this page to instantly reveal political framing, emotional triggers, and biased language.
-
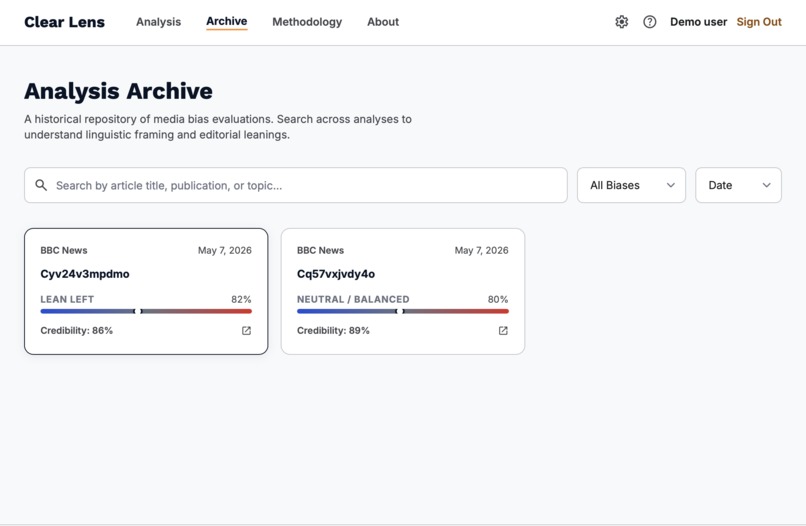
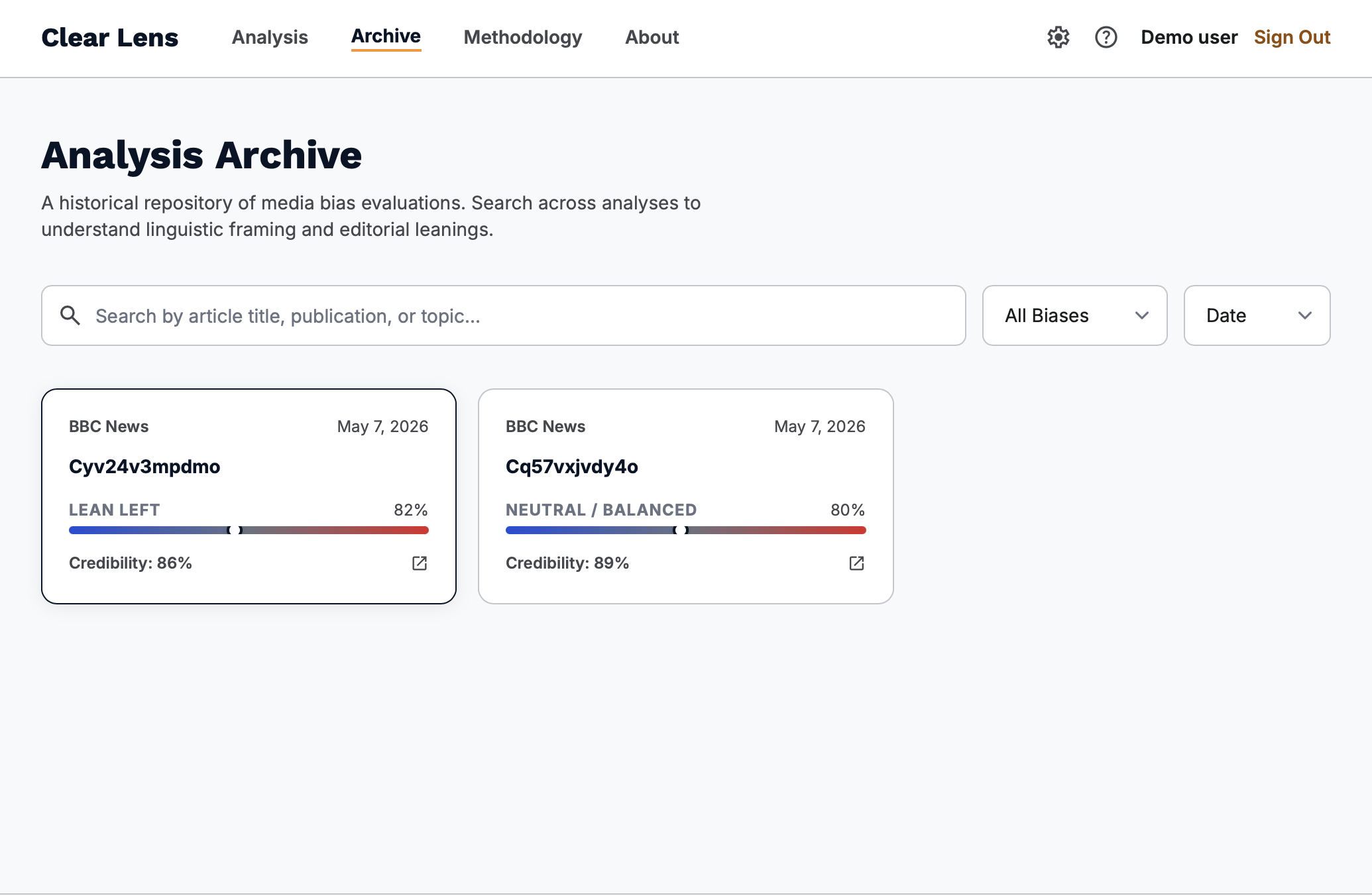
Archive page: Where every analysis you did is stored.
-
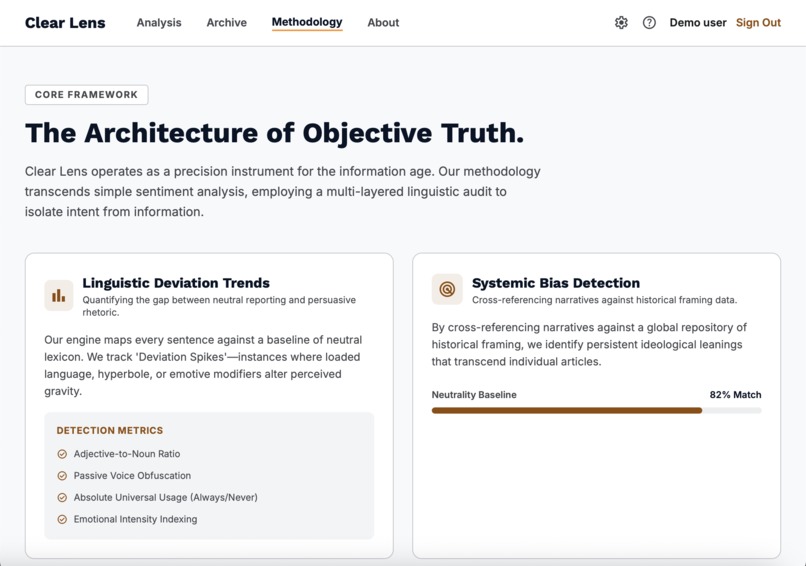
Methodology page.
-
All about Clear Lens is shown in this About page.
-
Login page.
-
Sign up page.
Inspiration
We built ClearLens because we were tired of not knowing whether to trust what we were reading.
Every day we consume news from outlets with clear editorial agendas but the framing is subtle enough that most readers don't notice it. A headline that says "border crisis" and one that says "immigration surge" describe the same event through completely different political lenses. We wanted a tool that could surface that gap instantly, without requiring a media studies degree to interpret.
The deeper motivation came from a simple question: what if you could hold a news article up to a light and see its skeleton? Not just what it says, but how it says it which perspectives it foregrounds, which it omits, and what rhetorical techniques it uses to move the reader. That idea became ClearLens.
What it does
ClearLens is a single-page media literacy tool that analyses any news article URL and returns a structured bias report in seconds. Paste a link from BBC, Fox News, The Guardian, Breitbart, Reuters, or dozens of other outlets and ClearLens tells you:
- Where it sits on the political spectrum: from Strongly Progressive to Strongly Conservative, rendered as an animated sliding marker on a gradient bias bar.
- Its credibility score: a 0–100 rating based on editorial standards and sourcing practices of the outlet.
- Loaded language: specific phrases flagged as politically weighted, each with a plain-English explanation of why the term carries rhetorical bias.
- Missing perspectives: viewpoints the article structurally omits, matched to the source's editorial lean.
- Framing strategy: a written description of the narrative approach: whether the piece uses systemic framing, individual liberty framing, false equivalence, or another technique.
Beyond analysis, the app includes a live Analysis Archive where every report is saved per user, searchable by title or source, and filterable by political direction. A News Suggestions panel fetches real headlines from BBC, The Guardian, and Reuters via live RSS so users always have fresh articles to examine.
The bias score is computed as:
$$S_{final} = S_{source} + \sum_{i} \delta_i^{path} + \varepsilon$$
where \( S_{source} \) is the outlet's baseline bias score, \( \delta_i^{path} \) are directional adjustments from URL keyword signals, and \( \varepsilon \) is a small variance term that reflects article-level variation within a source.
How we built it
ClearLens is a zero-dependency, single-file web application with no build step, no backend, and no API key required.
Stack:
- Vanilla HTML, CSS, and JavaScript
- Tailwind CSS (via CDN) for the editorial design system
- AllOrigins as a CORS proxy for live RSS feed fetching
Analysis Engine:
The core of the app is a client-side bias engine built on three layers:
// 1. Source profile lookup
const profile = SOURCE_PROFILES[domain]; // bias score + credibility
// 2. URL path keyword adjustment
for (const kw of TOPIC_BIAS_SIGNALS.left) {
if (path.includes(kw)) biasScore -= 8;
}
// 3. Variance + clamping
biasScore = Math.max(-100, Math.min(100, Math.round(biasScore)));
The source profile database covers 50+ outlets with bias scores derived from established media research organisations including Ad Fontes Media and AllSides. Loaded terms, missing perspectives, and framing strategies are drawn from curated pools matched to the article's detected political lean.
Authentication & Storage:
All user data, including accounts, analyses, and sessions, is stored in a single structured localStorage key. Each analysis is scoped to the signed-in user's email address, keeping histories cleanly separated.
Design:
The visual language follows a "Precision Instrument" aesthetic: deep navy #091426, amber accent #fe932c, flat surfaces, 1px structural borders, and a strict 8px spacing grid. Work Sans handles headlines; Inter handles everything functional.
Challenges we ran into
The CORS wall. Our initial plan was to call the Anthropic Claude API directly from the browser for live article analysis. We hit the CORS policy immediately, browsers block cross-origin requests to api.anthropic.com from frontend code. Rather than build a backend proxy just to pass API calls through, we pivoted to a fully client-side engine. This turned out to be a better decision: it meant zero infrastructure, instant load times, and no API key management for end users.
RSS feed reliability. Live news feeds are inconsistently formatted across outlets. BBC, Guardian, and Reuters all structure their RSS differently, and some endpoints block direct browser requests. We solved this with the AllOrigins proxy and wrote a graceful fallback to a static curated pool so the UI never breaks.
Making bias feel credible without being reductive. Bias scoring is genuinely hard. A single number on a spectrum risks oversimplifying nuanced editorial choices. We spent significant time calibrating source baselines against existing research, and added URL keyword signals and framing strategy text to give users qualitative context alongside the quantitative score.
Accomplishments that we're proud of
- Zero infrastructure. The entire app ships as a single HTML file that runs in any modern browser with no setup. No server, no database, no API key.
- 50+ outlet coverage with research-backed bias and credibility scores, URL-level signal detection, and per-lean loaded term libraries which are all running client-side in milliseconds.
- A complete product experience with six fully designed pages, a working auth system, per-user persistent archive, live news feeds, and a polished design system built within the hackathon window.
- Design quality. The UI matches a high-fidelity production standard: animated bias markers, gradient spectrum bars, skeleton loading states, toast notifications, and a fully responsive layout.
What we learned
- Browser security constraints are a feature, not a bug. Being forced off the easy path (direct API calls) led us to build something more robust and more deployable.
- Framing is as important as data. The hardest part of the project wasn't the code, it was deciding how to present bias information responsibly. A score without context is just another opinion. We learned to design for nuance.
- Single-file apps are underrated. Stripping away build tools forced us to think clearly about architecture. Everything in one file meant every dependency was a conscious choice.
- Media literacy is a design problem. Surfacing bias isn't just an NLP challenge, it's a UX challenge. How you show the information shapes how people interpret it.
What's next for ClearLens
- Real article content analysis via a lightweight backend proxy, enabling full-text NLP rather than URL-signal inference, returning to the original vision with proper server-side integration.
- Browser extension so users can analyse any article they're already reading without leaving the page.
- Source comparison mode submit the same story covered by two different outlets and see a side-by-side bias delta.
- Trend dashboard aggregate bias data across users to surface which topics are being most heavily framed across the media landscape in real time.
- Shareable reports generate a public permalink for any analysis so readers can share bias breakdowns directly.

Log in or sign up for Devpost to join the conversation.