-

Web Interface
-
Pipeline
Inspiration
One of our team members was at a holiday party when she overheard one of the organizers ask if anyone had a non-explicit playlist to play during the party. Upon a quick search of google, there are about a hundred websites that convert Youtube videos to mp3 files and 0 websites that take the expletives out of songs. However, there are about ten articles on how to take curse words out of songs, complete with nine steps. Since no one had done something like this, we decided to make CleanBeats.ai our hack.
What it does
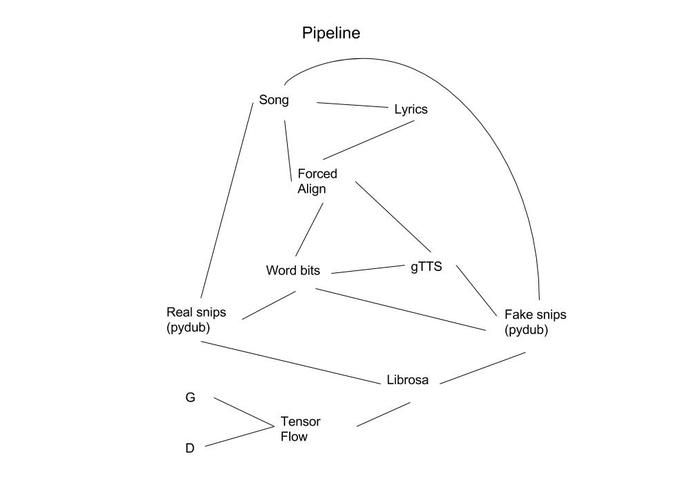
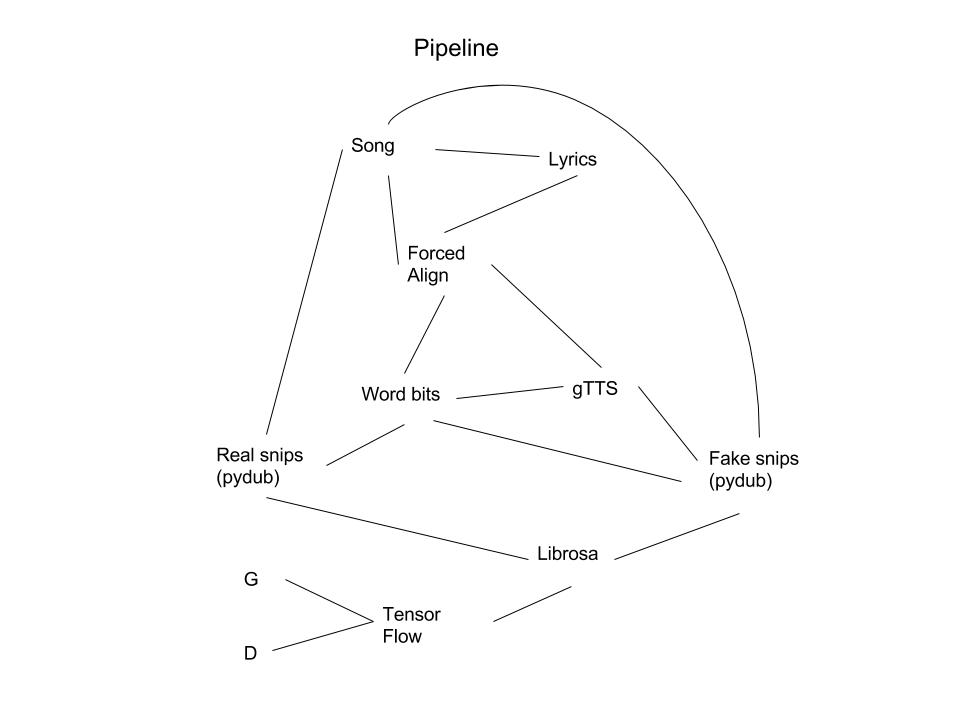
Our python script first takes an audio file along with an untimed transcript and identifies the location of each word contained. Then, based on which word the user wants cancelled out, the script splices the audio file, inverts one of the two stereo channels, and combines the channels back together to cancel the voice in this region out. This is based on the assumption that voice is centered in stereo, which is largely true. We now have a censored version of the track!
This would probably be good enough, but we wanted to go a step further. Bleeped out intervals of audio are a real party-killer. We decided that it would be awesome if you could replace the bleeped out word with ANY other word: think of all the possibilities! Our software uses a pre-trained machine learning model to try to adapt the desired word to the context of the music and then inserts it into the right spots.
We have an intuitive web interface that allows users to easily upload their audio and receive the edited version in return.
How I built it
Chronologically, out first step was to determine the most optimal way to find the position of each word in the audio. We used a custom version of the forced alignment algorithm called Canetis that is trained specifically to run forced alignment with heavy noise, identifying almost every word in the lyrics. We parallely figured out an efficient Python implementation with the PyDub library that filtered out the words that had to be removed and their locations and removed the voice from it. 4 hours in, and we had made significant progress! Our next step was to figure out an efficient way to make the machine learning model learn how to mimic the style and genre of the desired audio. We considered many different approaches, including style transfer and recurrent neural networks, but ultimately settled on using a GAN that would try to mimic the style. For our input data, we decided to give the network the new word and the context of the song it would be inserted in. However, we had to convert text to audio to make it easier for the model to generate the audio, so we used the Google text-to-speech engine to get a sufficiently good approximation of what it would sound like as our seed value. Our fake was thus generated and our real audio would be the original track itself. In order to build up a training set, we built up a data pipeline using our Forced Aligner’s values that automatically builds up training sets for our GAN’s stored as .npy files. After running the model, we would run the overlaid text-to-speech engine word with the context of the music through the generator to construct the desired portions of the track.
Challenges I ran into
It takes about four minutes to process a three-minute song and have it ready for download, which is apparently the fastest our algorithm can achieve this result. Furthermore, regarding the machine learning aspect of our hack, training the model takes a long time. There are many ways in which our whole pipeline could be made far more efficient to achieve quicker results. In particular, we did not have sufficient time to build the architecture necessary to consistently effect this style transfer.
Accomplishments that I'm proud of
Our forced alignment algorithm is responsible for determining and inserting a word that has a similar style to the rest of the song sequence. However, where we’re particularly proud is our robust data pipeline that automatically builds up more training data each time our CleanBeats is used, so that in the future training our Models will be a breeze. We were able to build a GAN that learned to mimic the style of the song, but were not yet successful at changing the pitch of the generated voice.
What I learned
Generative Adversarial Networks do NOT translate easily over to audio. We vaguely knew this, but we still underestimated the number of factors that affect the quality of the output. What still motivated us was the fact that the length of the average word in a song <200ms, which we believed was short enough for the network to produce a relatively satisfactory output that would blend in with the rest of the music.
Furthermore, we discovered the importance of covering all edge cases in the process of building a data pipeline.
What's next for CleanBeats.ai
There is a lot of room for improvement, but it looks promising. We hope to be able to train our model with a lot more music, which will take quite a bit of time, but hopefully helps it generalize well and give us better results for any track. We also hope to make the forced alignment more efficient to make the pipeline more efficient - reducing the time for which a user has to wait before being able to download their track. We have a strong data pipeline established so we can now easily and automatically build up our datasets and keep training our models. We also hope to use better text-to-speech engines with more versatile audio output.


Log in or sign up for Devpost to join the conversation.