-
-
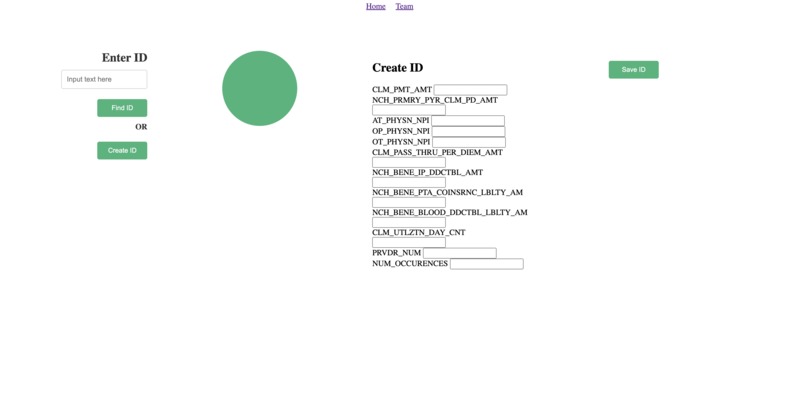
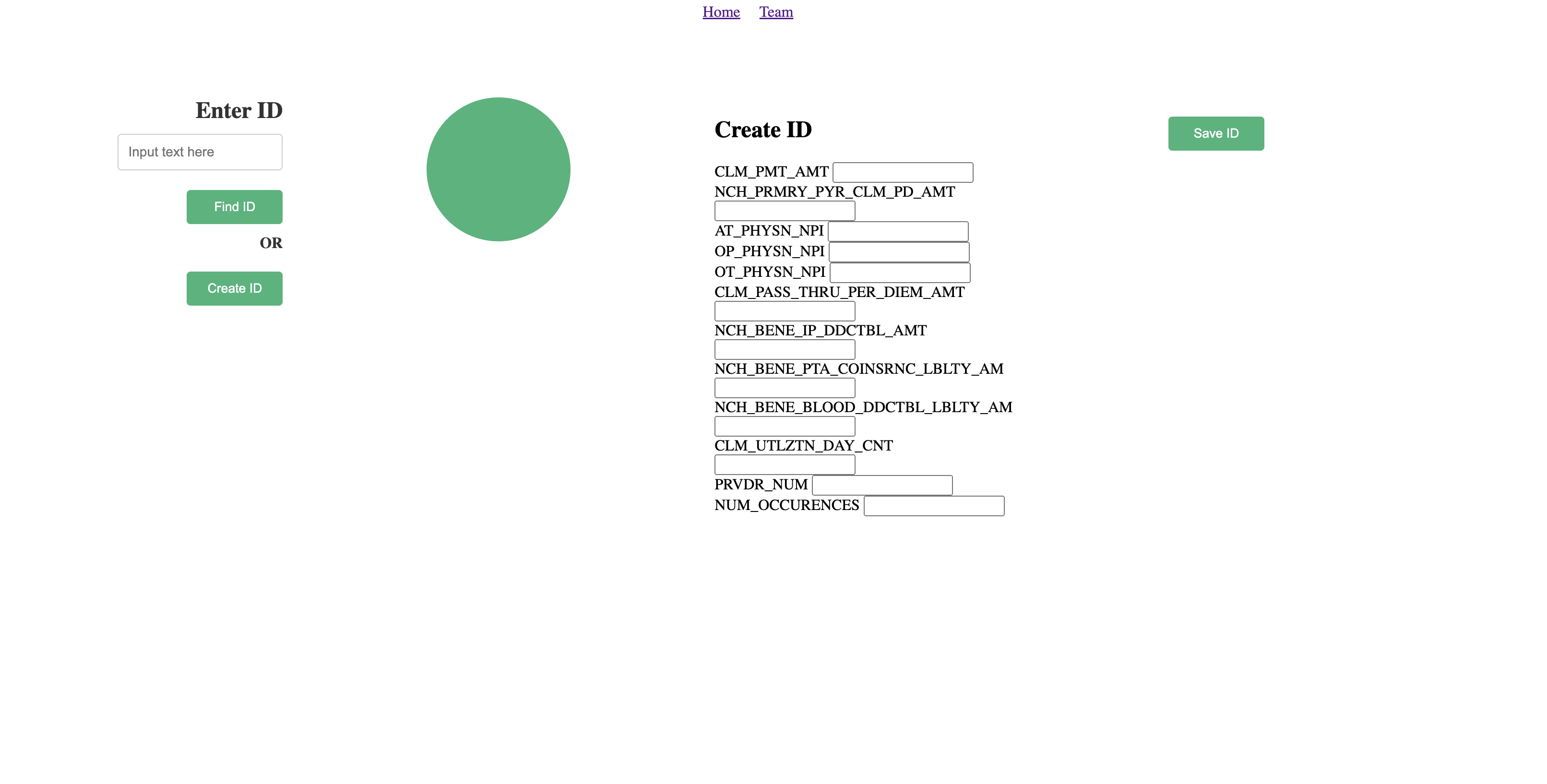
upon clicking "create id" we can input claim parameters
-
Inspiration:
As individuals accustomed to US healthcare systems, we realized that healthcare is a field in which medical jargon and extensive documentation may make the task of parsing data efficient and labor-intensive. We were interested in exploring the possibilities of AI, especially because of its ability to make costly tasks more time-efficient. By exploring different methods of classification models, we naturally decided upon building a project that expedites the labor-intensive process of detecting healthcare fraud to improve the overall workflow of insurance providers looking to manage their healthcare records.
What it does
Our website application features a user-friendly interface in which users can pull up individual records from an existing database. The website shows a graphic indicating the likelihood of the individual record having features which would indicate the existence of fraud. Additionally, we offer functionality where users can manually input fields commonly used in standardized CMS (Centers for Medicare & Medicaid Services) datasets. This data is then loaded into our machine learning model, and its results are displayed on the website as well.
How we built it
We chose this project as we are all interested in the many applications of machine learning. Through some research, we discovered the prevalence of fraud within medical records and a few research papers attempting to define what type of machine learning model would be best to detect such fraud. We decided to make a minimum viable product of such a solution, using our own knowledge on ml models.
We found a dataset of the CMS (Centers for Medicare & Medicaid Services) website so it is more accurate and real life applicable.
The model is an isolation forest and when an anomaly is detected we have fraud detection set to -1, while when it is not, we have fraud detection set to 1. We use StandardScaler to normalize the features because Isolation Forest is sensitive to the scale of features. We set n_estimators=100: This sets the number of trees in the forest. More trees generally provide better accuracy but increase computation time.
We add the predictions to our DataFrame as a new column 'fraud_prediction'. We then filter the DataFrame to get all cases flagged as potential fraud.
We save the trained model using pickle, allowing us to load and use it later without retraining.
A flask backend under app.py takes in the request from the front end to load the prediction model using pickle.load. Then we can use a predict function to take in input_data, and then return the prediction as a JSON file.
Then our front end was coded using Angular with components for different tabs and button logic for creating an id, saving the id, then detecting fraud.
Challenges we ran into
Challenges with front-end formatting, as a few of us did not know Angular previously. Not enough time to come up with a clean, finished product in the short hackathon period.
Accomplishments that we're proud of
We are proud of working through several bugs including errors with TypeScript front end, and python flask errors.
Additionally, we are proud of our team effort in delegating tasks so that each individual can provide a meaningful contribution. In practice, this generally involved having individuals work on different areas within frontend and backend, as well as github documentation, in order to maximize efficiency during the hackathon.
What we learned
We learned about angular front end. We learned which models are best for detecting fraud which include linear regression and isolation forest. We learned about the power of teamwork and utilizing everyone’s strengths. We came together.
What's next for Clean Care
We can add reasoning for why fraud is detected and which parameters were flagged. We want to clean up our angular product and make it more usable for healthcare providers that would potentially use this application.
Additionally, since we are dealing with healthcare data, we would want to provide end-to-end encryption of data to ensure that users of the website can trust that their data is secure and protected. Some potential methods could involve RSA encryption of JSON tokens received and transmitted between the frontend and backend servers of our application.
Built With
- angular.js
- colab
- flask
- numpy
- pandas
- python
- sklearn

Log in or sign up for Devpost to join the conversation.