-
-
-
-
-
-
-
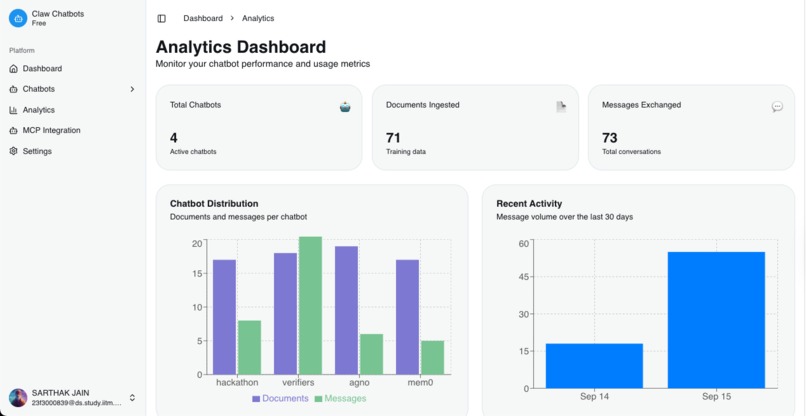
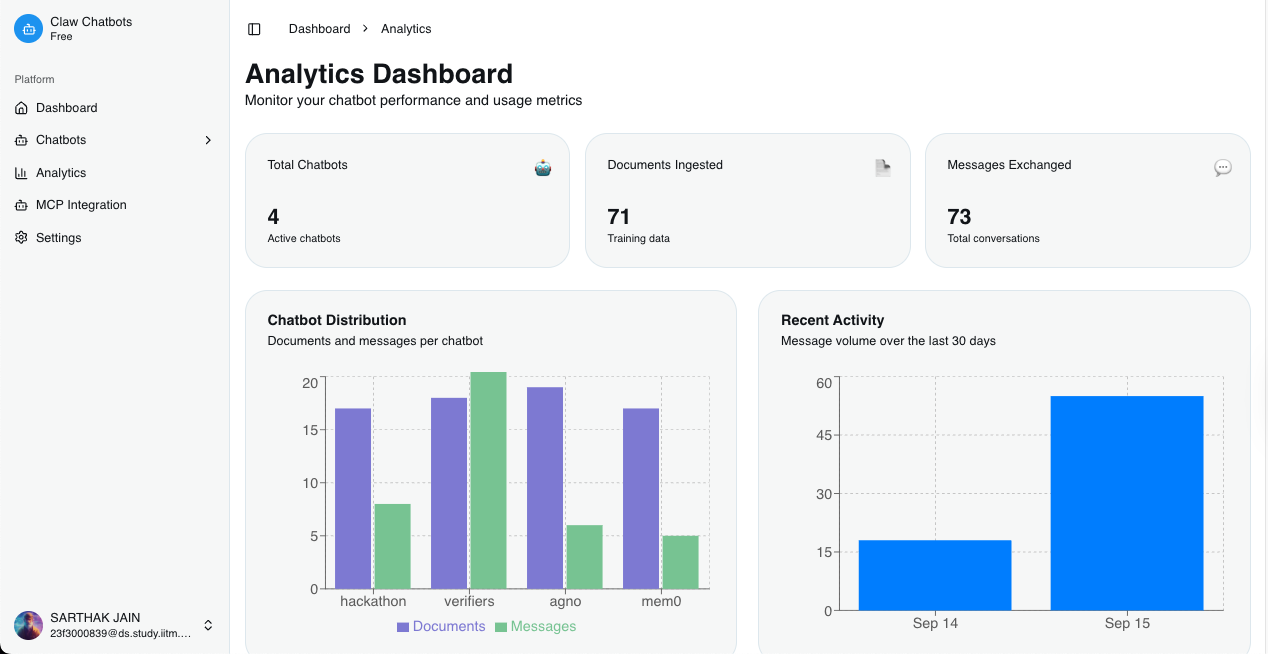
analytics for your chatbots
-
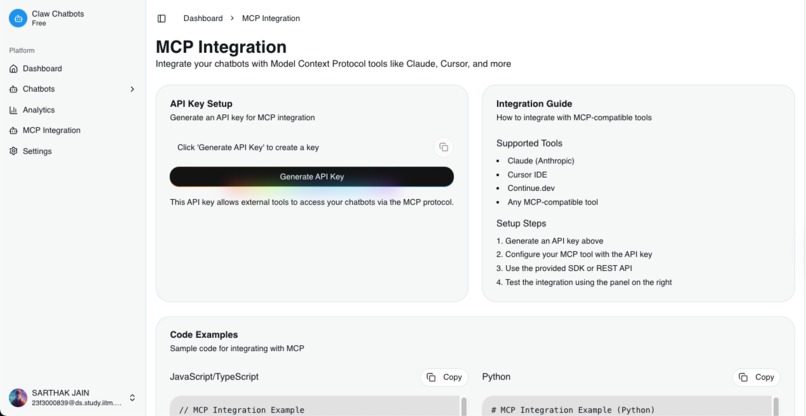
-
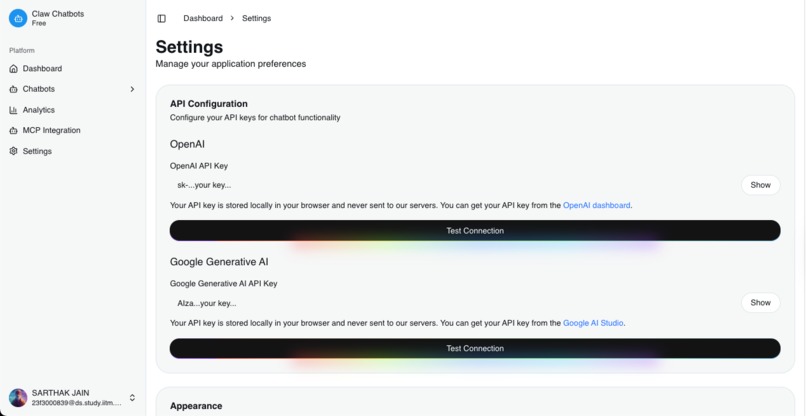
-
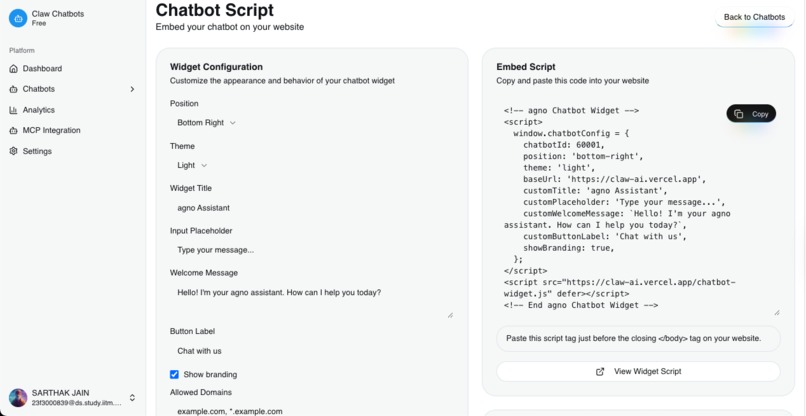
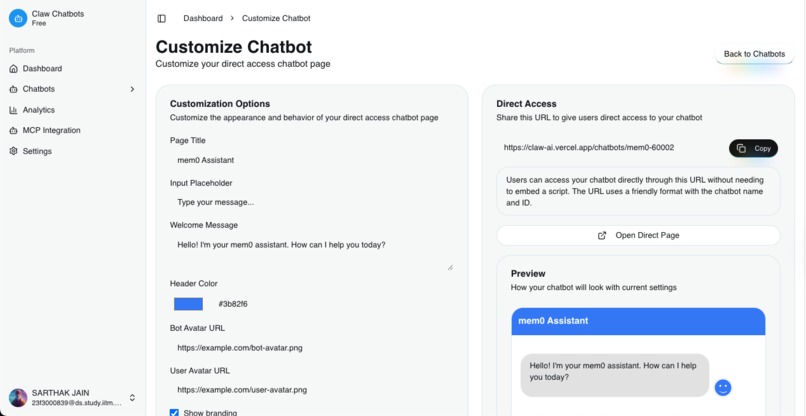
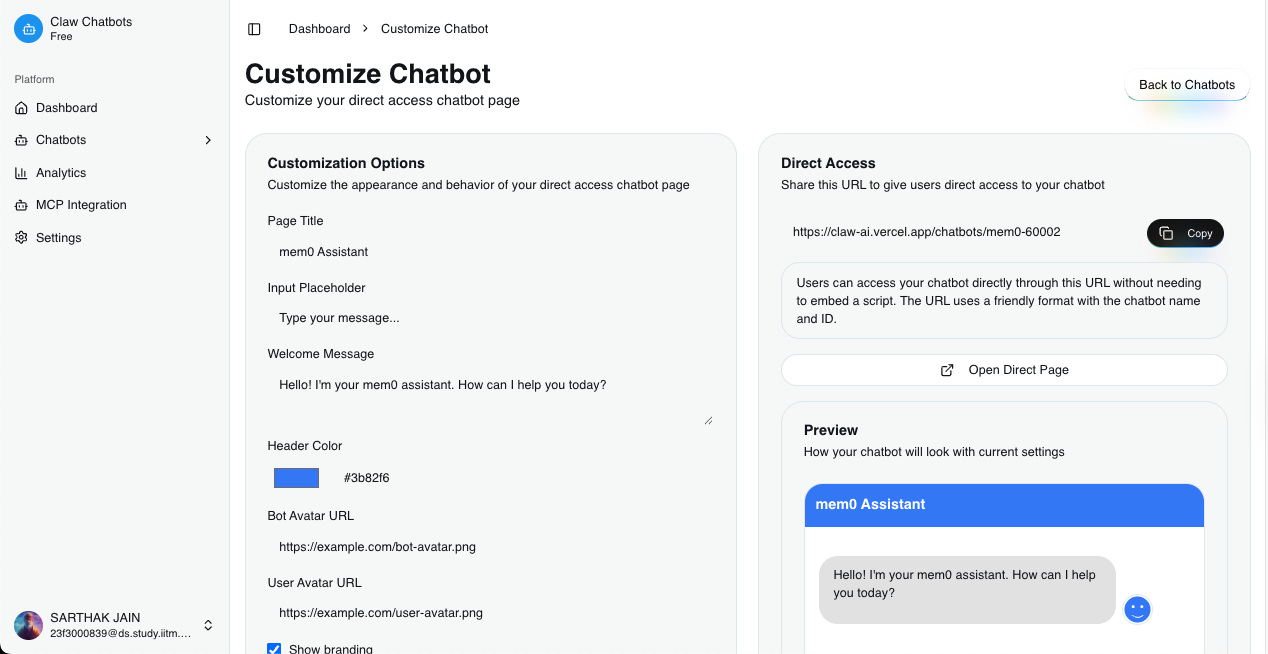
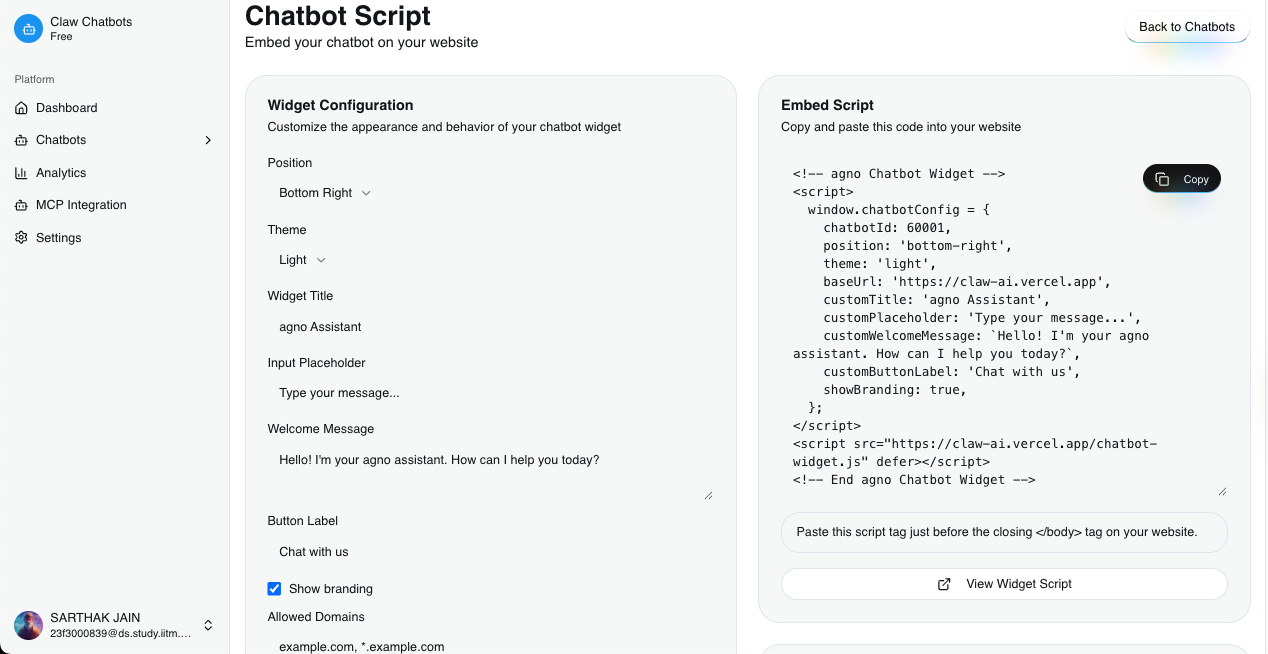
get script tag and use for ai assistant widget in your website
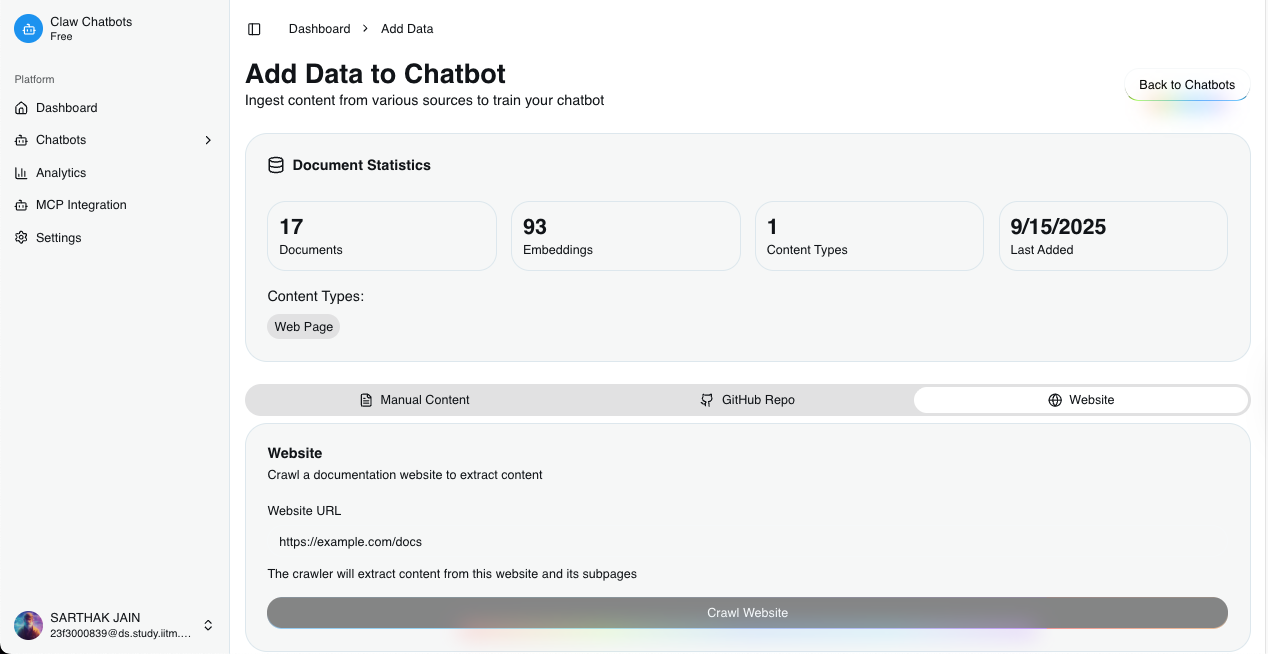
Claw - Elevator Pitch
Tagline: "Transform your documentation into intelligent chatbots with TiDB Vector Search"
Short Description: Create custom AI chatbots from any website or GitHub repository in minutes. Our platform leverages TiDB's powerful vector search capabilities to deliver accurate, context-aware responses by semantically understanding your content. Simply point to your documentation, and get a smart chatbot that actually knows your product - no coding required.
Key Benefits:
- Instant chatbot creation from existing content
- Semantic understanding using TiDB Vector Search
- No technical expertise needed
- Seamless integration with your website
- Scalable cloud-based solution
This solution solves the common problem of outdated or ineffective documentation by turning it into an interactive, intelligent assistant that can understand and respond to user queries with contextual accuracy.
ClawProject Story
Inspiration
Our journey with ClawProject began with a simple yet powerful idea: to democratize AI chatbot development by creating an intuitive, accessible platform that empowers developers and non-technical users alike to build sophisticated conversational agents. We were inspired by the growing demand for AI-powered customer service solutions and the complexity barriers that prevent many from leveraging this technology.
The inspiration also stemmed from observing how fragmented the chatbot development landscape was - with tools either being too technical for beginners or too limited for advanced users. We wanted to bridge this gap with a solution that offers both simplicity and extensibility.
Additionally, we were particularly excited about the potential of TiDB's Vector Search capabilities and wanted to leverage them to create a more intelligent chatbot platform that could understand context and provide more accurate responses.
What it does
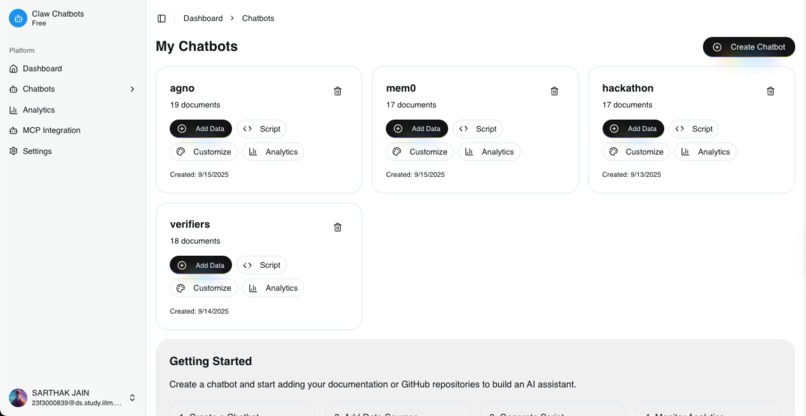
ClawProject is an AI chatbot maker platform that allows users to create, customize, and deploy intelligent chatbots with minimal coding effort. The platform features:
- Intuitive Chatbot Builder: Drag-and-drop interface for designing conversation flows
- Multi-Model Support: Integration with various AI models including OpenAI, Anthropic, and open-source alternatives
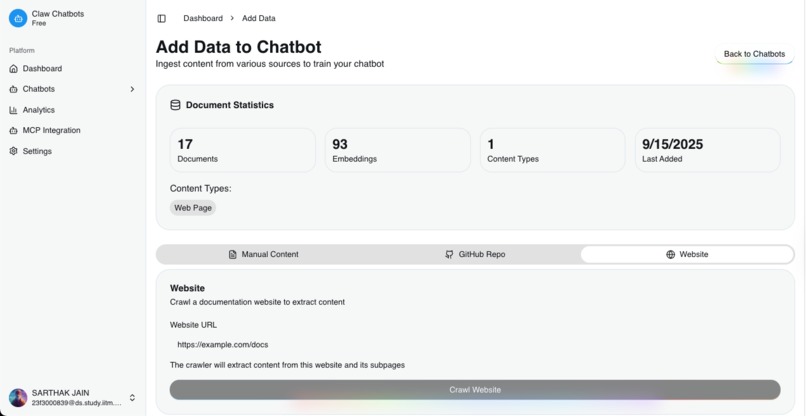
- Document Ingestion: Ability to train chatbots on custom documentation and knowledge bases
- Vector Search: Advanced similarity search capabilities for contextual responses using TiDB's native vector functions
- Team Collaboration: Multi-user environment for collaborative bot development
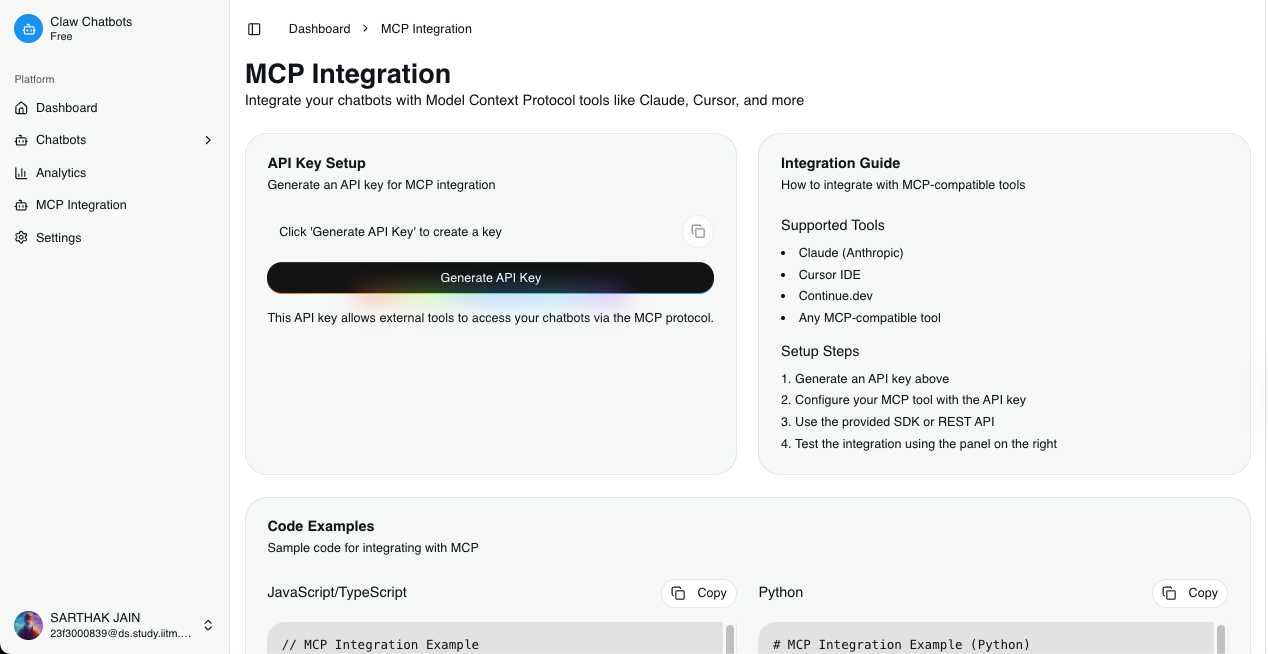
- Deployment Flexibility: Options to deploy bots on websites, messaging platforms, or as APIs
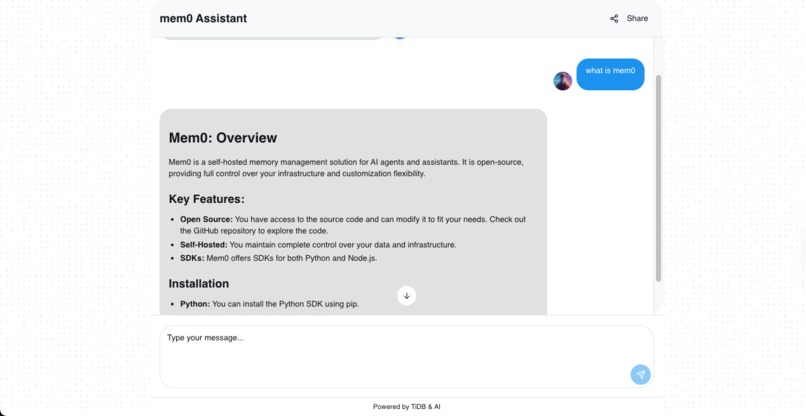
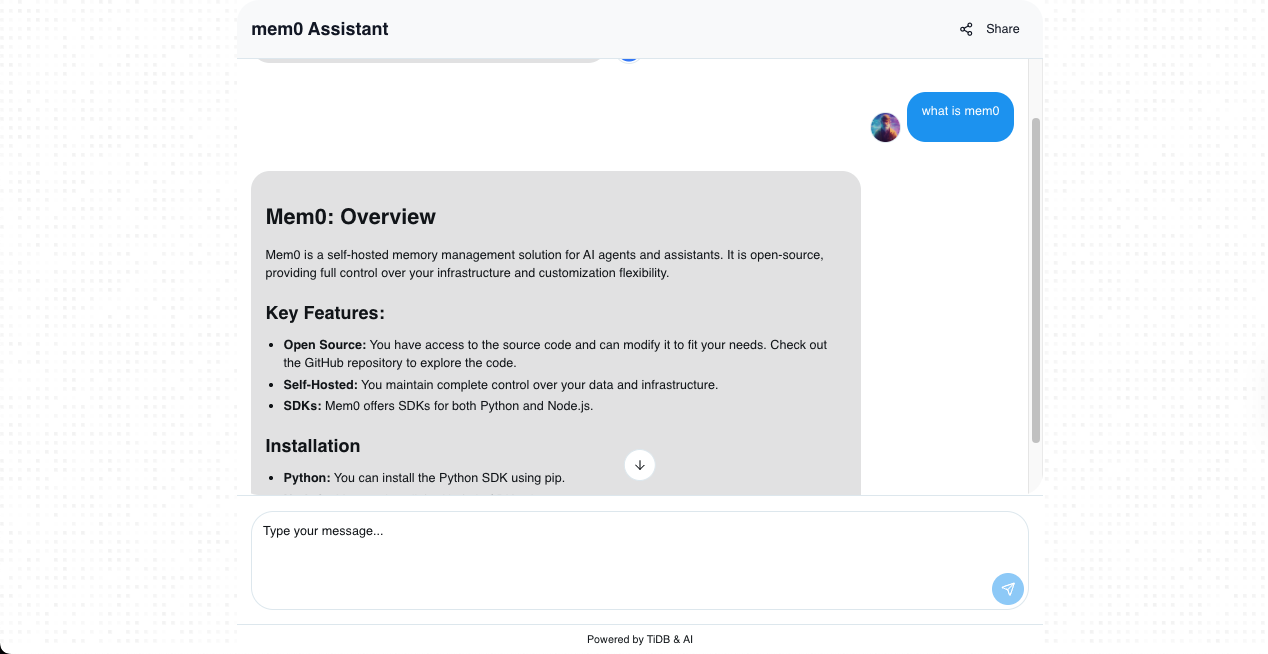
The system uses Retrieval-Augmented Generation (RAG) architecture to understand document content and provides contextually relevant responses during conversations, making it ideal for customer support, educational assistance, and knowledge management applications.
How we built it
Our technical architecture centers around a Next.js frontend with a TiDB Serverless backend for vector storage and retrieval:
- Frontend: Built with Next.js 14 using React Server Components for optimal performance
- Backend: TiDB Serverless for relational data storage and vector operations
- Vector Processing: Integration with OpenAI embeddings API for document vectorization
- Database Schema: Custom-designed tables for chatbots, documents, conversations, and vector embeddings
- Authentication: NextAuth.js for secure user management
- Deployment: Vercel for frontend hosting with TiDB Serverless for database needs
Key technical components include:
- Drizzle ORM for database interactions
- Tailwind CSS for responsive UI design
- Shadcn/ui components for consistent user interface elements
- Custom vector search implementation using TiDB's vector functions
TiDB Integration
We leveraged TiDB Serverless with its native Vector Search capabilities as our primary database. Our implementation includes:
- Vector Storage: Storing document embeddings as VECTOR type in TiDB tables
- Similarity Search: Using TiDB's VEC_COSINE_DISTANCE function for finding relevant documents
- HNSW Indexes: Implementing Hierarchical Navigable Small World indexes for efficient vector search
- Schema Design: Creating optimized table structures for chatbots, documents, and embeddings
Our database schema includes:
users: User account informationchatbots: Chatbot configurations and metadatadocuments: Source documents for each chatbotvectors: Vector embeddings with TiDB's VECTOR typechat_history: Conversation history for context retention
RAG Pipeline Implementation
Our Retrieval-Augmented Generation pipeline consists of several stages:
Document Ingestion:
- Web scraping and parsing of documentation sites
- Chunking algorithms to break documents into manageable pieces
- Metadata extraction and preservation
Embedding Generation:
- Using OpenAI's text-embedding-ada-002 model to create 1536-dimensional embeddings
- Batch processing for efficient API usage
- Error handling for rate limits and API failures
Vector Storage:
- Storing embeddings in TiDB with proper indexing
- Metadata association with each vector
- Efficient insertion strategies for large document sets
Retrieval Process:
- Converting user queries to embeddings
- Performing similarity search using TiDB's vector functions
- Ranking and filtering results based on relevance scores
Generation Phase:
- Crafting prompts with retrieved context
- Sending enriched prompts to LLMs
- Post-processing and formatting responses
AI Chat Prompts
Our prompt engineering focuses on creating effective conversations:
- Context-Aware Prompts: Including relevant document snippets retrieved through vector search
- Role Definition: Clear instructions about the chatbot's persona and purpose
- Formatting Guidelines: Consistent response formats for better user experience
- Fallback Handling: Graceful degradation when no relevant context is found
- Conversation Memory: Maintaining context across multiple message exchanges
Example prompt structure:
You are an AI assistant for [COMPANY/PROJECT NAME].
Your purpose is to help users with questions about the documentation.
Use the following retrieved context to answer the user's question:
[RETRIEVED CONTEXT]
If the context doesn't contain relevant information, say so honestly.
Answer the question based on the context provided above.
Be concise but helpful.
User Question: [USER QUESTION]
Challenges we ran into
Database Vector Operations
One of our biggest challenges was implementing reliable vector storage and search operations with TiDB. We encountered several issues:
- Initial SQL syntax errors when storing embeddings, particularly with CAST operations
- Compatibility issues with vector casting functions in TiDB
- Performance optimization for similarity searches with large datasets
- Handling large embedding arrays in SQL queries efficiently
- Debugging vector operation errors in TiDB Serverless environment
Document Ingestion Pipeline
Creating a robust document ingestion system proved complex:
- Parsing various document formats while preserving structure
- Efficiently chunking large documents for optimal embedding (balancing context vs. specificity)
- Managing memory usage during processing of large documents
- Ensuring consistent metadata handling across different document types
- Rate limiting issues with embedding API calls
RAG Implementation
Building an effective Retrieval-Augmented Generation system presented unique challenges:
- Finding the optimal balance between retrieved context and prompt length
- Dealing with irrelevant or low-quality retrieval results
- Optimizing similarity thresholds for different types of queries
- Handling cases where no relevant documents are found
- Maintaining conversation context across multiple exchanges
Model Integration
Integrating multiple AI models presented challenges:
- Standardizing interfaces across different model providers
- Managing rate limits and API quotas effectively
- Handling varying response formats and quality
- Implementing fallback mechanisms for model failures
- Cost optimization for embedding and completion operations
UI/UX Design
Balancing simplicity with functionality in the user interface:
- Creating an intuitive flow builder for non-technical users
- Ensuring responsive design across devices
- Managing complex state in conversation flows
- Providing meaningful analytics and insights
- Real-time preview of chatbot behavior
Accomplishments that we're proud of
Successful TiDB Vector Implementation: Despite initial database challenges, we successfully implemented a functional vector search system using TiDB's native capabilities that enables contextual chatbot responses.
Robust RAG Pipeline: Created an end-to-end Retrieval-Augmented Generation pipeline that effectively combines document retrieval with language model generation.
User-Friendly Interface: Created an intuitive interface that allows both technical and non-technical users to build sophisticated chatbots without extensive training.
Scalable Architecture: Designed a system architecture that can handle multiple chatbots, large document sets, and concurrent users while maintaining performance.
Multi-Model Support: Successfully integrated multiple AI providers, giving users flexibility in their model choices based on cost, performance, and capability requirements.
Document Intelligence: Built a robust system for ingesting and processing various document types, enabling chatbots to provide accurate, context-aware responses based on custom knowledge bases.
Optimized Vector Search: Implemented efficient similarity search using TiDB's HNSW indexes for fast retrieval of relevant documents.
What we learned
Technical Insights
- TiDB Vector Capabilities: Gained deep understanding of TiDB's vector search features and optimization techniques
- RAG Best Practices: Learned effective approaches for combining retrieval and generation in AI applications
- Database Optimization: Learned the importance of proper indexing and query optimization when working with vector databases
- Error Handling: Discovered the critical need for comprehensive error handling in AI applications where external services can fail unpredictably
- State Management: Gained deeper understanding of complex state management in React applications with real-time features
Product Development
- User-Centered Design: Realized the importance of building features based on user feedback rather than assumptions
- Iterative Development: Learned that releasing smaller, well-tested features frequently is more effective than large, complex releases
- Performance Monitoring: Understood the importance of monitoring application performance in production to identify bottlenecks
- Prompt Engineering: Developed expertise in crafting effective prompts for different scenarios and user intents
Team Collaboration
- Cross-Functional Communication: Improved our ability to communicate technical concepts to non-technical team members
- Task Prioritization: Learned to prioritize tasks based on user impact and technical dependencies
- Documentation: Recognized the value of maintaining good documentation for both users and future development
What's next for ClawProject Story
Short-term Goals
- Enhanced Analytics: Implement comprehensive usage analytics and chatbot performance metrics
- Advanced Flow Builder: Add more sophisticated conversation flow capabilities including conditional logic and integrations
- Mobile Experience: Optimize the platform for mobile device usage and management
- Template Library: Create a library of pre-built chatbot templates for common use cases
- Improved RAG: Optimize retrieval algorithms and implement hybrid search (keyword + semantic)
Long-term Vision
- Multimodal Support: Extend beyond text-based interactions to include image and voice capabilities
- Enterprise Features: Develop advanced features for enterprise customers including SSO, audit trails, and compliance features
- Marketplace: Create a marketplace for chatbot templates, integrations, and third-party extensions
- AI Model Training: Enable users to fine-tune models on their specific data for improved performance
- Global Expansion: Localize the platform for international markets and support multiple languages
Technical Improvements
- Advanced TiDB Optimization: Leverage more advanced TiDB features like partitioning for large-scale deployments
- Improved Vector Search: Optimize similarity search algorithms for faster, more accurate results using TiDB's latest vector capabilities
- Caching Strategy: Implement intelligent caching to reduce API costs and improve response times
- Real-time Collaboration: Add real-time collaborative features for team-based chatbot development
- Offline Capabilities: Develop offline functionality for chatbot management in low-connectivity environments
We're excited about the future of ClawProject and committed to making AI chatbot development accessible to everyone, from individual developers to large enterprises, while leveraging the full power of TiDB's vector search capabilities.
Built With
- ai-sdk
- gemini-embedding
- nextjs
- openai
- tidb
- typescript
- vercel

Log in or sign up for Devpost to join the conversation.