-

Vietnamese – English Classroom Copilot
-
Vietnamese – English Classroom Copilot
-
Session management
Inspiration
In Vietnamese university classrooms, lecturers code-switch constantly: Vietnamese explanations peppered with English technical terms (gradient descent, learning rate, recursion…). Students struggle to capture everything in real time, and generic AI tools are not built around live lecture audio in Southeast Asian languages.
We wanted a speech-first, classroom-first system: the microphone drives the experience, VALSEA provides the speech intelligence layer, and the output is structured learning material — not a free-form chatbot.
What it does
Core loop (must-have)
- Live capture — User clicks Start listening; browser captures mono audio, resamples to 16 kHz PCM16, base64-encodes chunks, and streams them over WebSocket to our gateway.
- Live transcript — Gateway proxies audio to VALSEA Realtime ASR (
wss://api.valsea.ai/v1/realtime); partial and final events are normalized, deduplicated, and streamed back to the UI in real time. - VALSEA enrichment pipeline — On Generate notes, the gateway calls four VALSEA text APIs in parallel (with per-call safe fallback):
- Annotations (
/v1/annotations) → semantic tags + annotated text - Clarifications (
/v1/clarifications) → simplified Vietnamese explanation - Translations (
/v1/translations) → full English translation (source: auto → target: english) - Formatting (
/v1/formatting) → structured lecture notes (meeting minutes with semantic tags)
- Annotations (
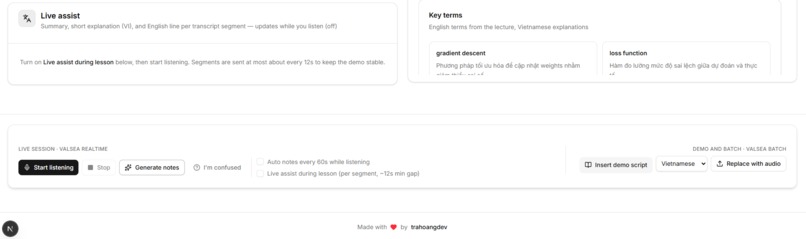
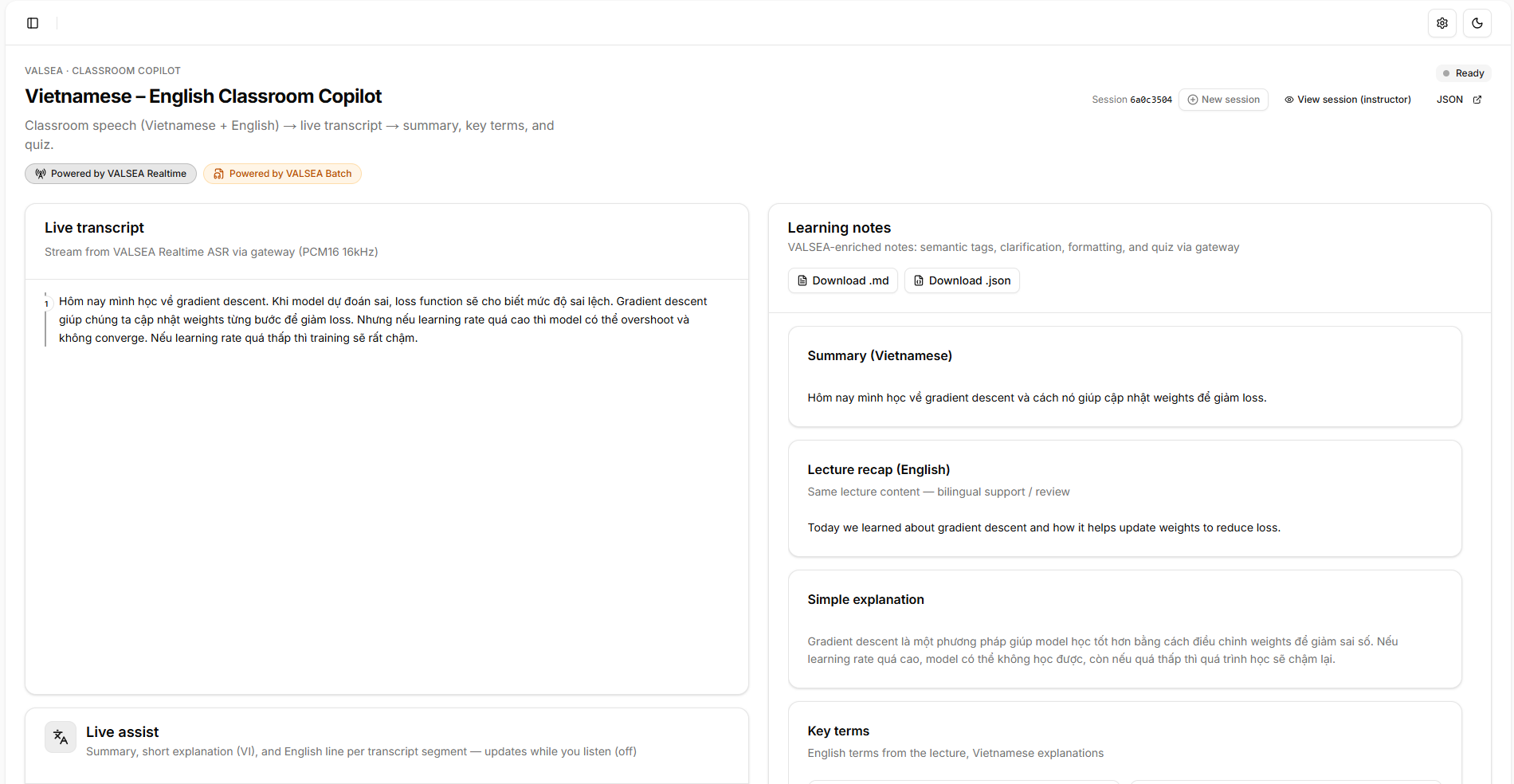
- Structured notes — A server-side LLM receives the transcript plus all VALSEA evidence and produces: Vietnamese summary, key terms with definitions, simple explanation, English recap, quiz questions (always in Vietnamese), and "confusing points."
- UI rendering — Notes appear in the right panel. VALSEA artifacts are also shown directly: semantic tag badges, formatted notes, and English translation from VALSEA — so judges can see both the LLM output and the raw VALSEA intelligence.
Additional features (implemented)
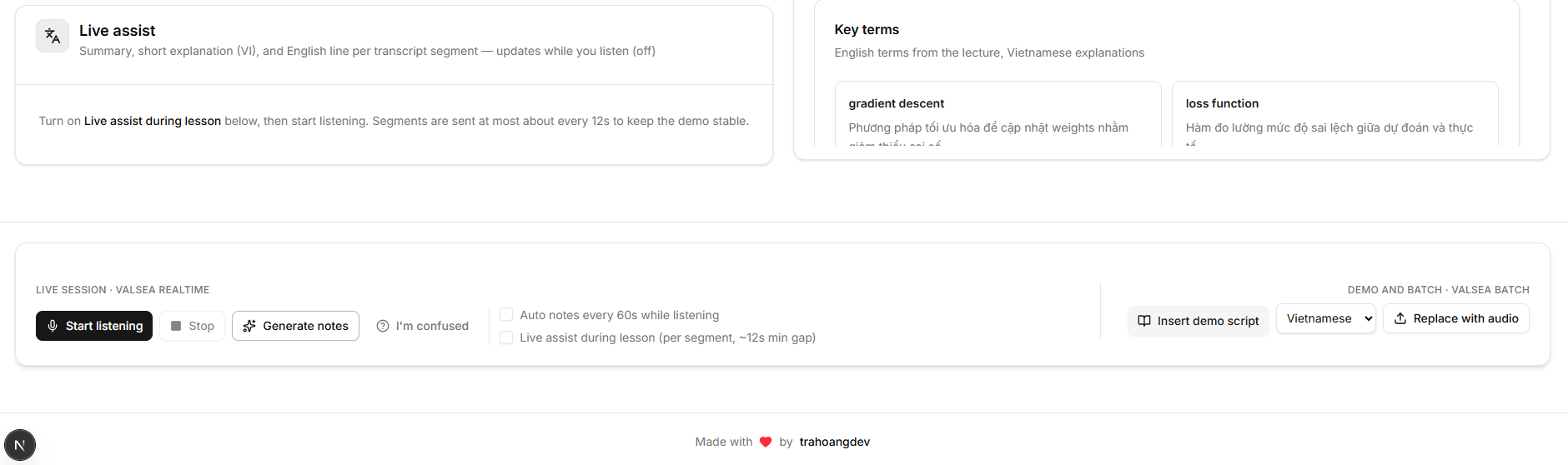
- Batch upload fallback — VALSEA
/v1/audio/transcriptionswithverbose_json,enable_correction,enable_tags. Works when realtime is unavailable. - Demo script injection — Seeded Vietnamese–English text so the full loop is demo-safe even without a microphone.
- Per-segment live assist — While listening, every finalized transcript chunk is sent to the LLM for a quick micro-summary + Vietnamese explanation + English line. Rate-limited (~12s min gap) for cost control. Displayed in a dedicated Live Assist feed.
- Auto-generate notes — Optional checkbox: auto-triggers Generate every 60s while listening (if transcript grew).
- "I'm confused" button — Students send confusion signals (with optional note) via WS or HTTP; signals are persisted per session.
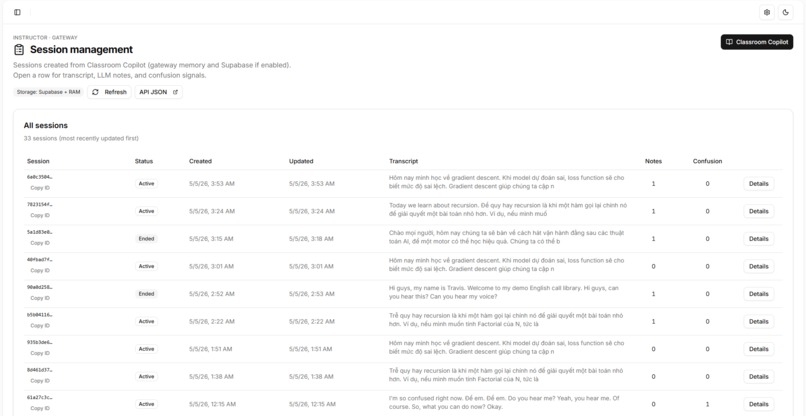
- Session management —
/sessionpage lists all sessions (Supabase or in-memory);/session/[id]shows full detail (transcript, learning outputs, confusion events). New session without page reload. - Export — Download structured notes as .md or .json including VALSEA learning context (semantic tags, formatted notes, translation).
- VALSEA reconnect — Exponential backoff (2s base, max 30s), generation tracking, max 5 retries before graceful error.
- Transcript processor — Merges short fragments, deduplicates repeated partials, flushes on word threshold (≥40) or time (25s), preserves English technical terms.
- Hybrid persistence — In-memory store + optional Supabase (sessions, transcript_chunks, learning_outputs, confusion_events).
Hackathon track
Real-Time Classroom Assist — live explanations, summaries, translations during lessons.
VALSEA endpoints used: 6
| # | Endpoint | Purpose |
|---|---|---|
| 1 | wss://api.valsea.ai/v1/realtime |
Live transcript (Vietnamese ASR with correction) |
| 2 | POST /v1/audio/transcriptions |
Batch fallback (verbose_json, correction, tags) |
| 3 | POST /v1/annotations |
Semantic tags + annotated text for key terms |
| 4 | POST /v1/clarifications |
Simplified Vietnamese for students |
| 5 | POST /v1/translations |
Full English translation |
| 6 | POST /v1/formatting |
Structured lecture notes (meeting minutes) |
How we built it
Architecture
Browser (Next.js)
↓ PCM16 base64 chunks over WebSocket
Gateway (Fastify + Node.js)
↓ audio.append / audio.commit / session.stop
VALSEA Realtime ASR
↓ transcript_partial / transcript_final
Transcript Processor (dedup, merge, chunk)
↓ finalized text
VALSEA Text APIs (annotations + clarifications + translations + formatting) [parallel, safe fallback]
↓ enriched evidence
LLM (OpenAI-compatible, configurable model)
↓ structured JSON
Frontend Learning Panel + Export
Tech stack
- Frontend: Next.js 16 (App Router), TypeScript, TailwindCSS, shadcn/ui, Lucide icons. Audio capture via
ScriptProcessorNode→ downsample → PCM16 → base64. - Gateway: Fastify with
@fastify/websocket,@fastify/cors,@fastify/multipart. Routes:/health,/api/sessions,/api/session/:id,/api/generate-notes,/api/transcribe,/api/confusion,/api/demo-transcript,/ws. - VALSEA integration: Dedicated clients (
valseaRealtimeClient.ts,valseaBatchClient.ts,valseaTextClient.ts) withsafeCall()wrapper — any single API failure is logged but doesn't break the pipeline. All 4 text APIs run in parallel viaPromise.all. - Intelligence:
intelligence.tscalls any OpenAI-compatible endpoint (configurable viaLLM_BASE_URL+LLM_MODEL, defaultgpt-4o-mini). Produces structured JSON with schema coercion. Separate prompt for live chunk assist. - Persistence:
HybridSessionStore— in-memoryMemorySessionStore+ optionalSupabasePersistence. Supabase migrations for sessions, transcript_chunks, learning_outputs, confusion_events. - Deployment: Frontend on Vercel (
client/), gateway on Render (server/, root directory).
Security
VALSEA_API_KEY,LLM_API_KEY,SUPABASE_SERVICE_ROLE_KEY— server-only (Render env vars).- Frontend uses only
NEXT_PUBLIC_GATEWAY_URLandNEXT_PUBLIC_WS_URL. - No secrets in browser bundle. No
.envcommitted.
Challenges we ran into
- VALSEA realtime stability — Network blips disconnect the WebSocket. We implemented reconnect with exponential backoff (2s → 4s → 8s → 16s → 30s), generation tracking to discard stale connections, and max 5 retries before graceful error with Vietnamese user message.
- Browser audio format — VALSEA expects mono PCM16 ~16 kHz base64. Browsers output Float32 at 44.1/48 kHz. We downsample, convert, and encode in-browser before streaming.
- Partial vs final transcript merging — VALSEA sends many partials before a final. Our
TranscriptProcessordeduplicates repeated partials, accumulates finals into chunks (flush at ≥40 words or 25s), and prevents tiny fragments from reaching the LLM. - Orchestrating 4 VALSEA text APIs — All calls run in parallel with individual
safeCall()wrappers. If annotations fail but translations succeed, the pipeline still enriches. Theenabledflag reflects "at least one API returned useful data." - LLM cost control — Live assist is rate-limited (12s min gap, one in-flight at a time). Full notes generation runs once per explicit click or 60s auto-trigger. VALSEA evidence injection means the LLM needs fewer tokens to produce accurate output.
- Split hosting — Vercel (HTTPS) ↔ Render (WSS). Required correct
NEXT_PUBLIC_WS_URLwithwss://scheme and CORS configuration on both sides.
Accomplishments that we're proud of
- Working end-to-end loop: speech → live transcript → VALSEA enrichment (4 APIs) → LLM → structured notes — not a UI mock.
- Deep VALSEA integration (6 endpoints) — the app is not "transcribe + chatbot." VALSEA drives semantic understanding at every layer: speech recognition, annotation, clarification, translation, and formatting.
- VALSEA artifacts visible in UI — Judges can see semantic tag badges, VALSEA formatted notes, and VALSEA English translation directly, proving the integration is real and adds value beyond the LLM.
- Demo resilience — Three input paths (live mic, audio upload, demo script) ensure the full story lands in any environment.
- Production-grade gateway — Reconnect logic, session lifecycle, transcript processor, hybrid persistence, rate-limited live assist, confusion events — not throwaway hackathon code.
- Per-segment live assist — Real-time micro-explanations as the lecture progresses, not just post-hoc notes.
What we learned
- Fallbacks are essential — Batch upload + demo script saved the demo when realtime had hiccups.
- Explicit WebSocket contracts — A small typed message contract between frontend and backend prevented entire classes of bugs.
- Never expose API keys — Environment split (Vercel vs Render) is worth the setup overhead.
- VALSEA text APIs significantly improve LLM output — The LLM produces more accurate, grounded notes when it receives annotated, clarified, and translated evidence. The quality difference is visible.
- Safe parallel calls — Running multiple enrichment APIs in parallel with individual fallback gives both speed and resilience.
What's next for Classroom Copilot
- VALSEA Sentiment (
/v1/sentiment) — automatic confusion/struggle detection from speech tone, surfacing "where students are lost" to lecturers without requiring manual button clicks. - Teacher dashboard — Aggregate confusion signals, difficult terms, and session analytics across all students.
- Multi-student mode — Multiple listeners in one class session; teacher sees aggregated view.
- LMS integration — Export structured notes directly to Moodle/Canvas.
- Improved chunking — Use VALSEA sentence boundaries for more natural transcript splits.
Built With
- fastify
- next.js
- node.js
- react
- render
- shadcn/ui
- supabase
- tailwind-css
- typescript
- valsea
- vercel
- websocket

Log in or sign up for Devpost to join the conversation.