-

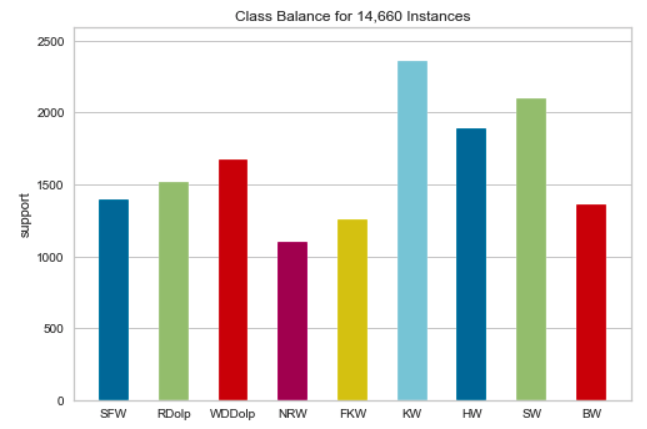
One hydrophone recording 24/7 at a very high sampling rate, can generate up to 24 terabytes a year. "Big Data"
-
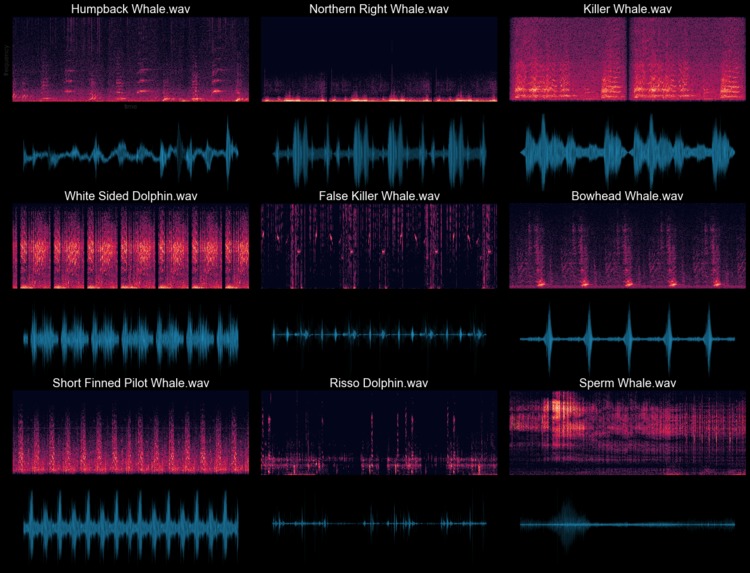
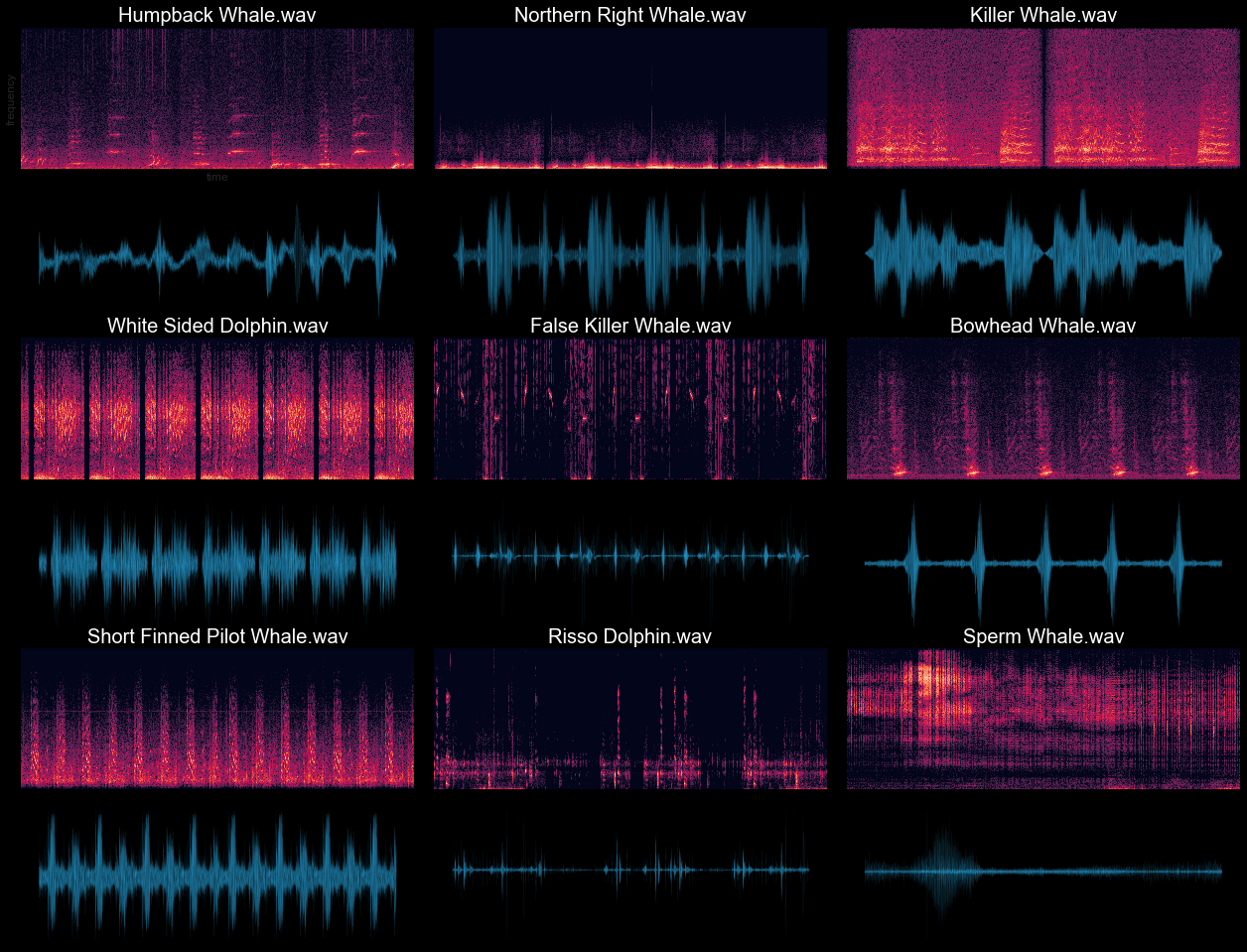
Exploratory Audio Data analysis after Dolby IO Enhancement
-
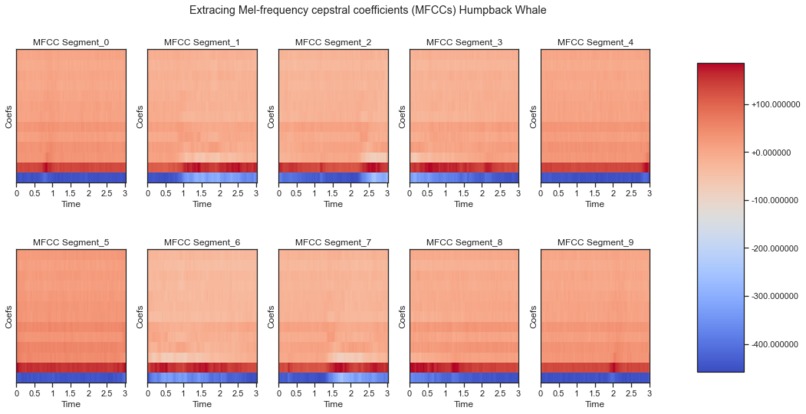
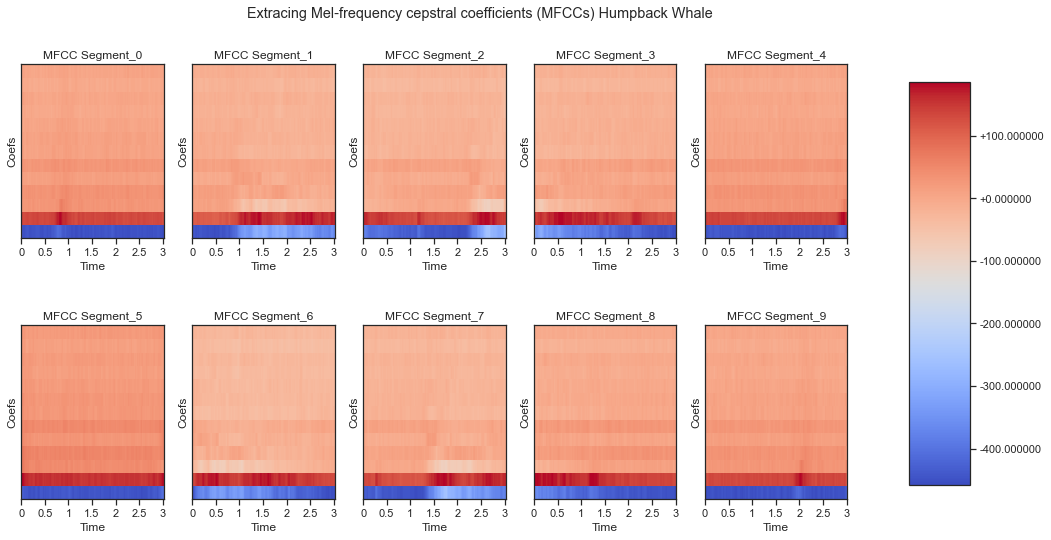
An example of Extracting the MFCCs "Used for speech Recognition" of a Humpback whale.
-
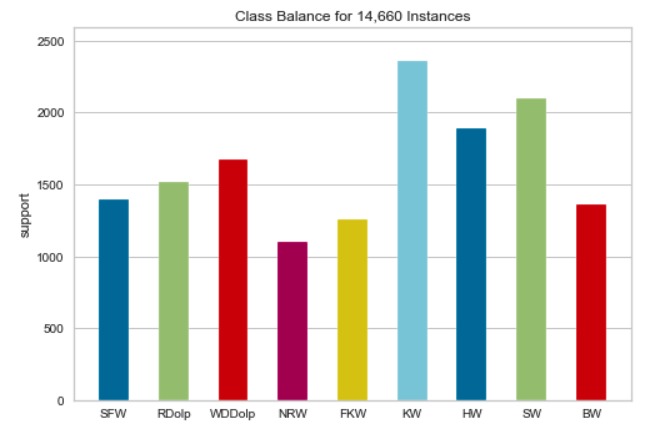
Over 10,000 MFCCs extracted after Dolby IO enhancement.
-
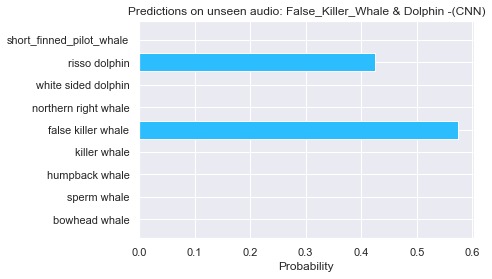
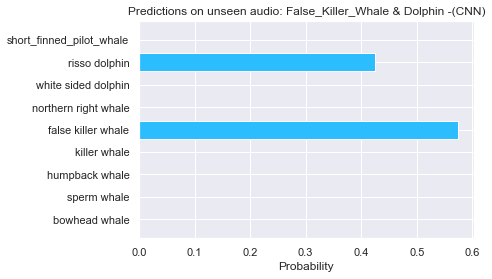
Running inferences with the trained CNN model. It was able to detect the two marine animals in one audio file!!!

Inspiration
"Because water is denser than air, sound travels very efficiently underwater. Sounds from some species of marine life and human activity can be heard many miles away and, in some cases, across oceans.
Passive acoustic instruments record these sounds in the ocean. There are some hydrophones that generate up to 24 terabytes a year! "e.g. Big Data"
This data provides valuable information that helps government agencies and industries understand and reduce the impacts of noise on ocean life.
By listening to sensitive underwater environments with passive acoustic monitoring tools, we can learn more about migration patterns, animal behavior, and communication." quoted from NOAA
What it does
The trained Convolution Neural Network model can be used to run inferences on unseen marine mammal audio in an effort to classify its species.
How we built it
- Web Scraped audio from Watkins Whale Database
- Dolby IO media processing *Tensorflow, Keras
- Python, Librosa, Essentia, Pydub, FFmpeg
Challenges we ran into
Web scraping and becoming familiar with Dolby IO API to process batches of audio "training data" of over 1000 audio files.
Accomplishments that we're proud of
Augmented audio files to synthesize more data: +/- 2dB, +/- 2 semitones and added random noise
The train CNN resulted in over 97% accuracy on the unseen test set.
What we learned
Audio preprocessing for ML, interacting with Dolby IO API, Training a model on MFCCs
What's next for Classifying Marine Mammals Vocals w/ Machine Learning
Implement Real-Time analysis using the audio library Essentia
- add more marine mammals
- introduce human-generated sounds like vessels, cargo ships, etc.


Log in or sign up for Devpost to join the conversation.