-

classify
-
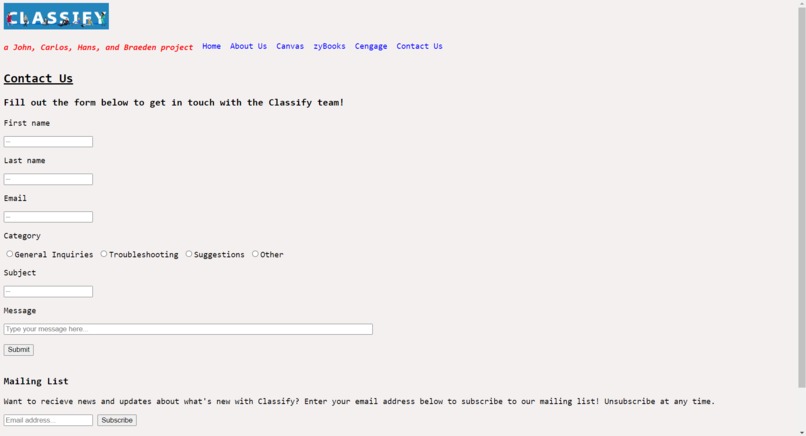
Contact Us tab
-
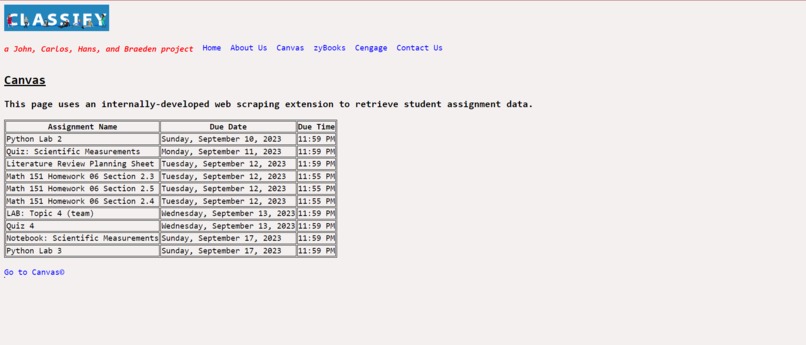
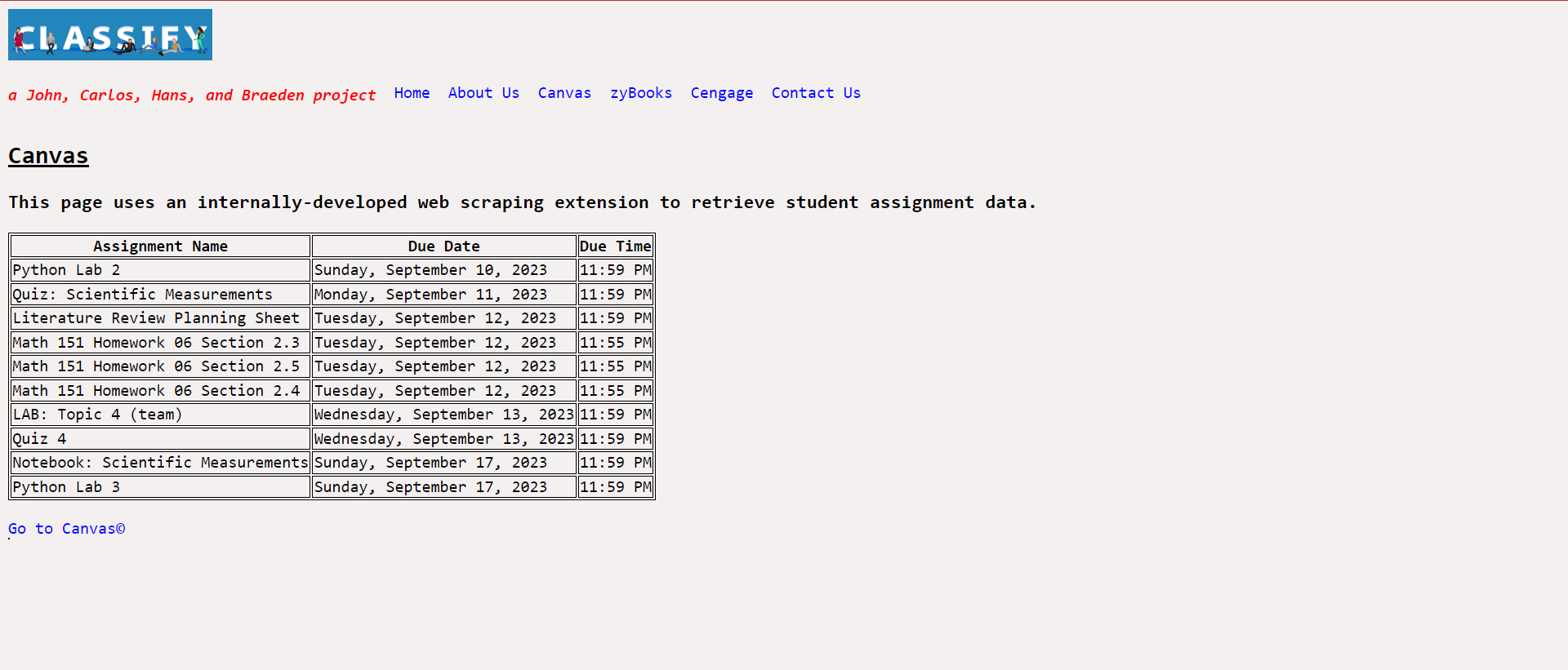
Canvas tab
-
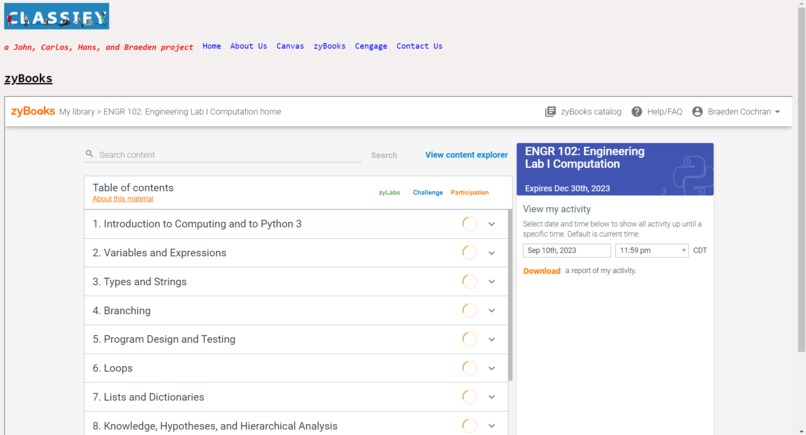
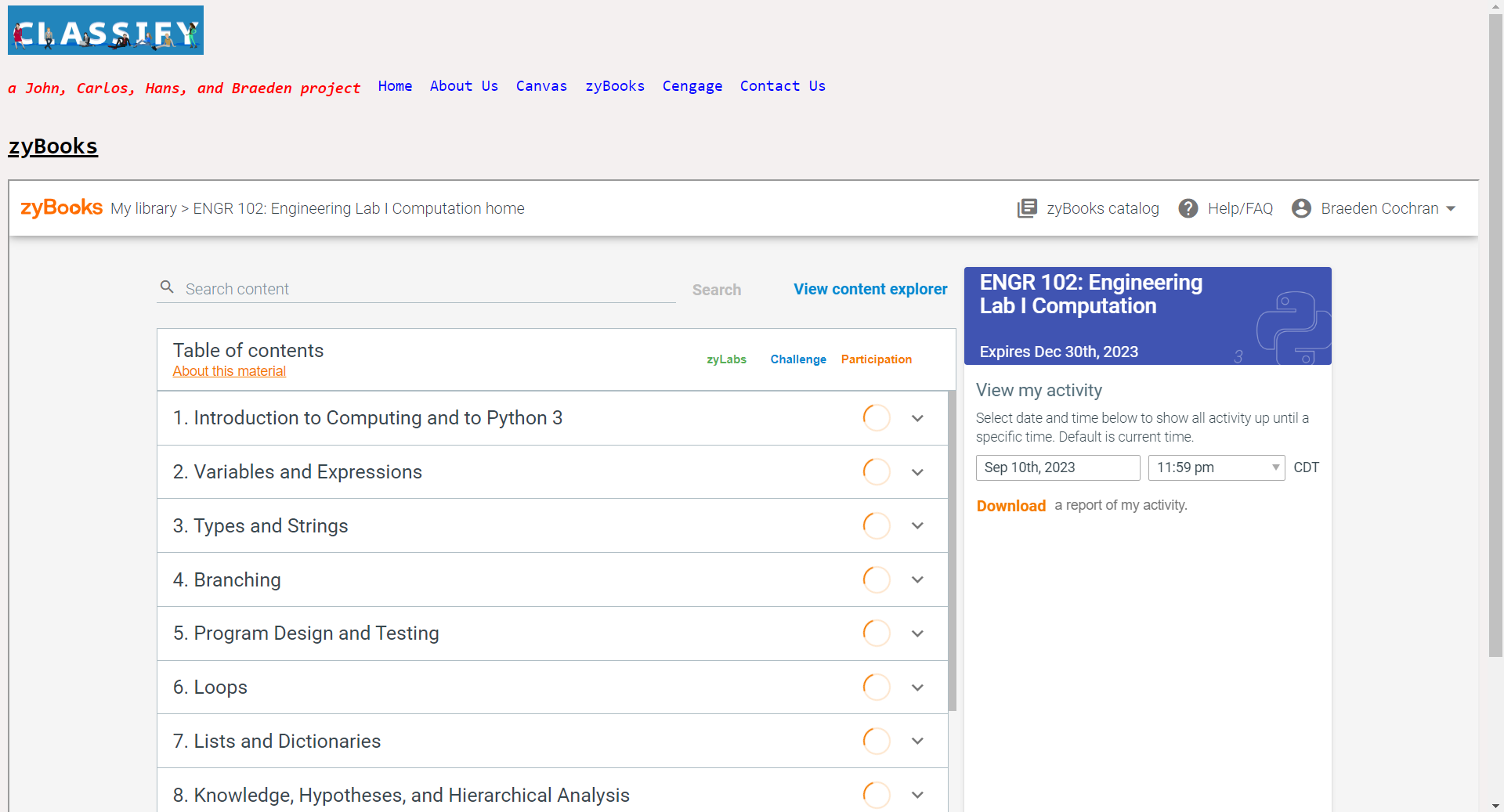
zyBooks tab
-

Home 2
-
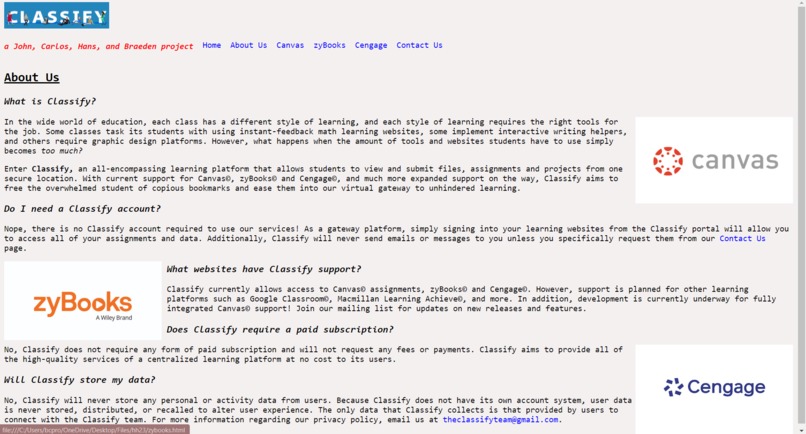
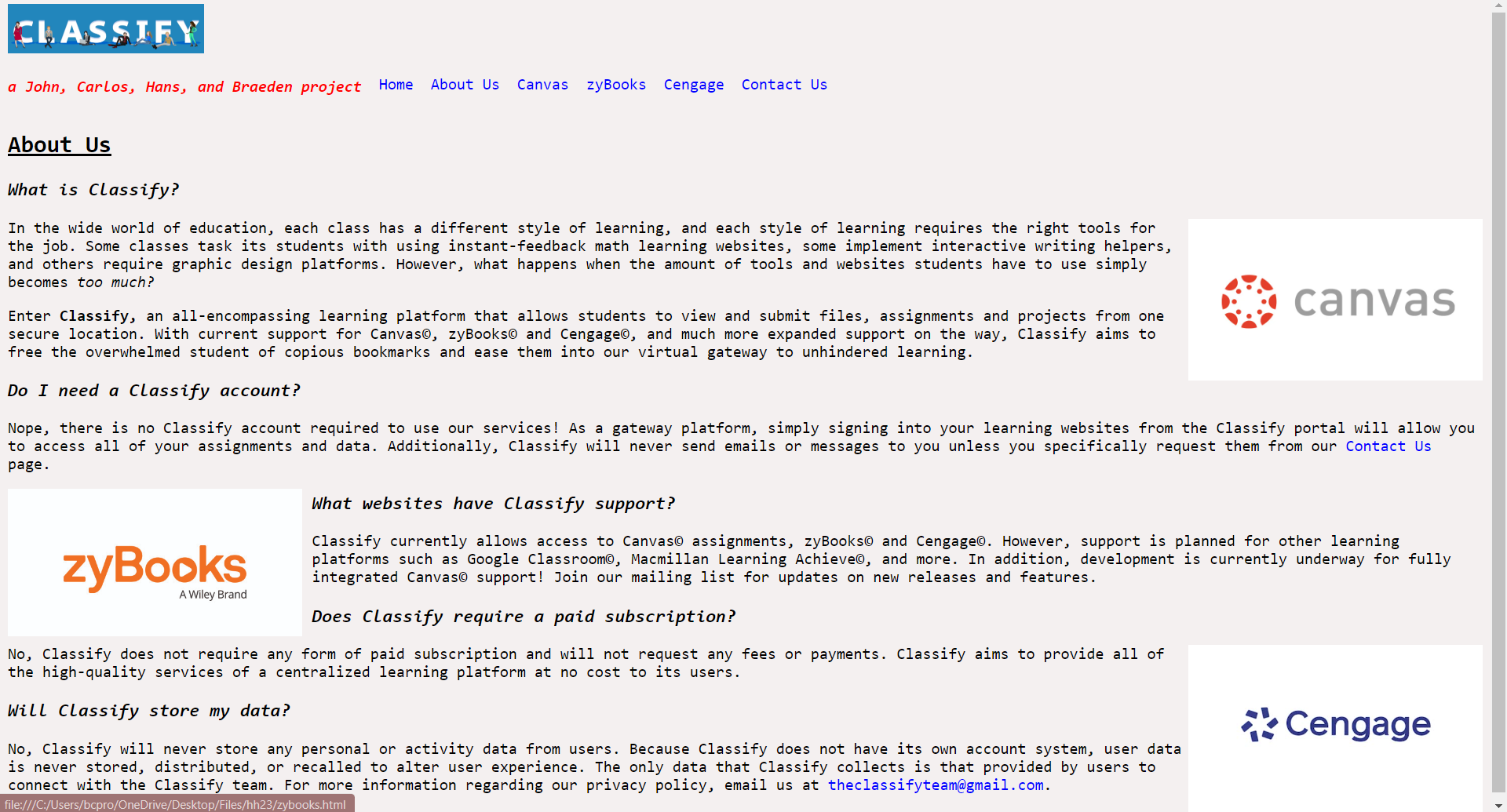
About Us tab
-
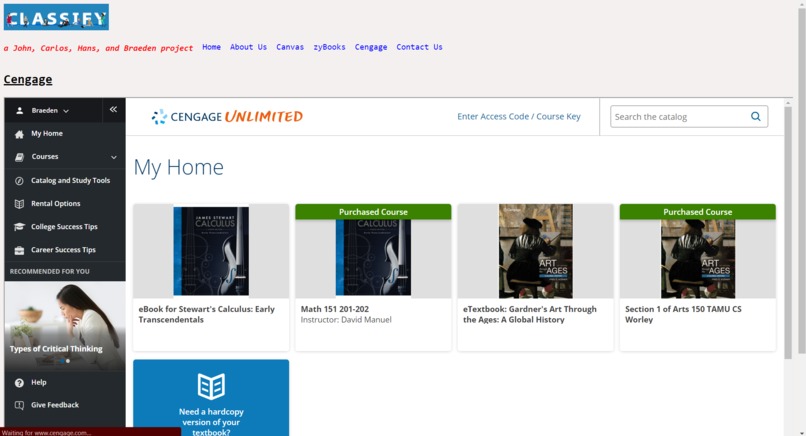
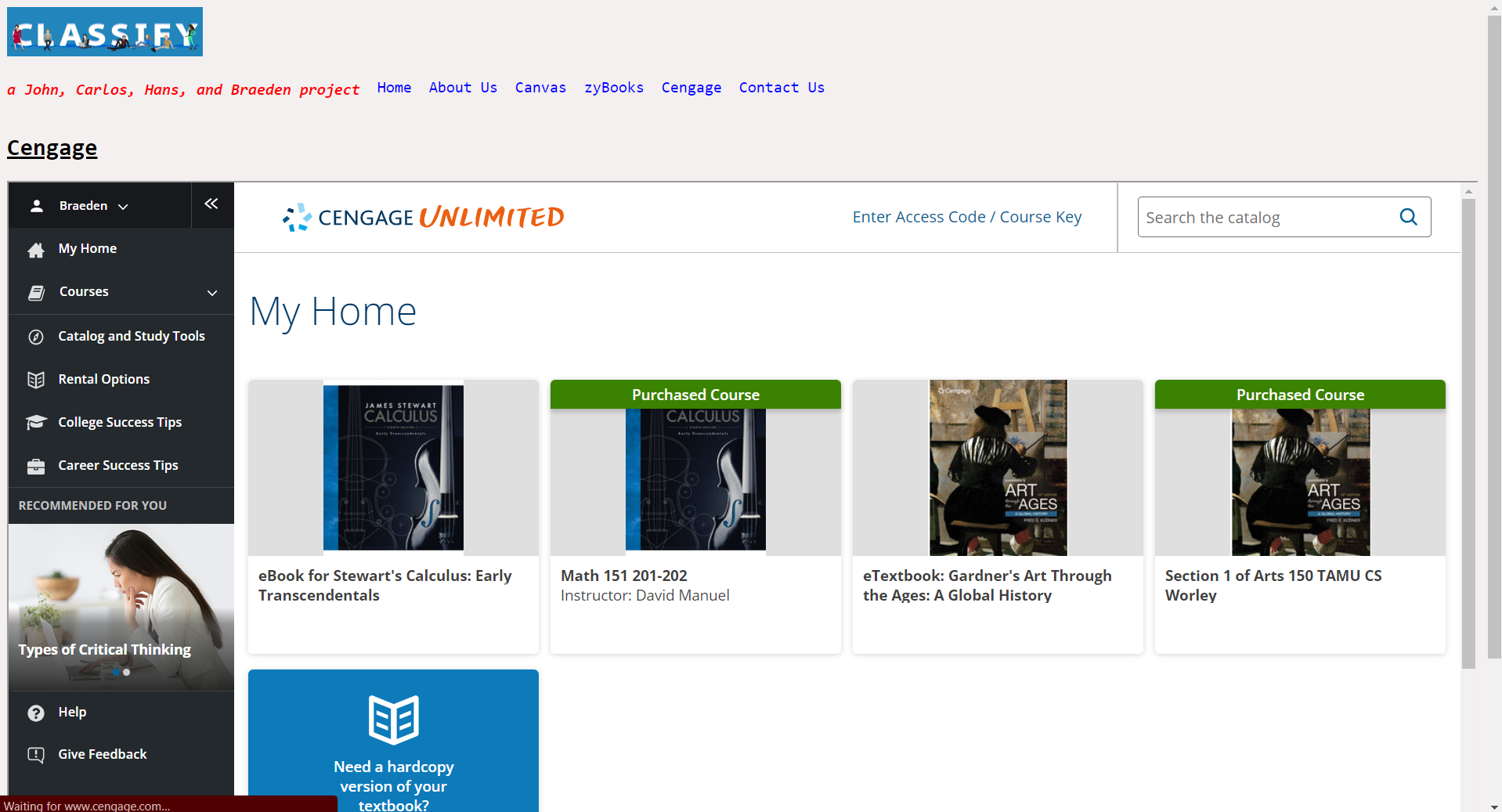
Cengage tab
-
Home


What we learned
We learned about how we can retrieve data from websites through web scraping in order to consolidate all of the relevant data across different websites into our project website.
Challenges we ran into
Initially, we would scrape the information by using an API key from canvas to fetch the information for the due dates onto the website. However, security checks as well as overall difficulty in finding the correct information made us pivot to web scraping through an HTML crawler. Originally this was better but security for programs like this is much more stringent and going through the TAMU identification service deemed this idea not viable either. In the end, we settled on making a Chrome extension which eventually worked but not without hours of debugging and help from multiple mentors.
How we built it
We began by building the website through frontend with a rudimentary website and followed this by attempting to build a backend code to collect data which then evolved into a chrome extension for canvas and iframes to display the rest of the websites.
What it does
Our website named Classify retrieves all possible homework assignments and due dates from various homework websites like Canvas and Cengage so that the student does not have the need to open additional tabs to do their class assignments. SImply, the student simply needs to complete one website for all of their homework.
What's next for Classify
We want to keep making enhancements to the Chrome extension for Classify so that it can work with websites other than Canvas, such as ZyBooks and Cengage.

Log in or sign up for Devpost to join the conversation.