🚀 Claso - AI Code Comment & Commit Message Generator
🚀 Inspiration
As developers, we've all been there - staring at a function we wrote months ago, trying to decipher what it does because we forgot to write proper documentation. Or spending precious minutes crafting the perfect commit message that actually describes our changes. We were inspired to solve this universal developer pain point using real machine learning, not just API wrappers.
The inspiration struck during a late-night coding session when we realized: "What if AI could understand our code context and generate professional-quality documentation automatically?" We wanted to build something that would actually help developers be more productive while maintaining code quality.
🎯 What it does
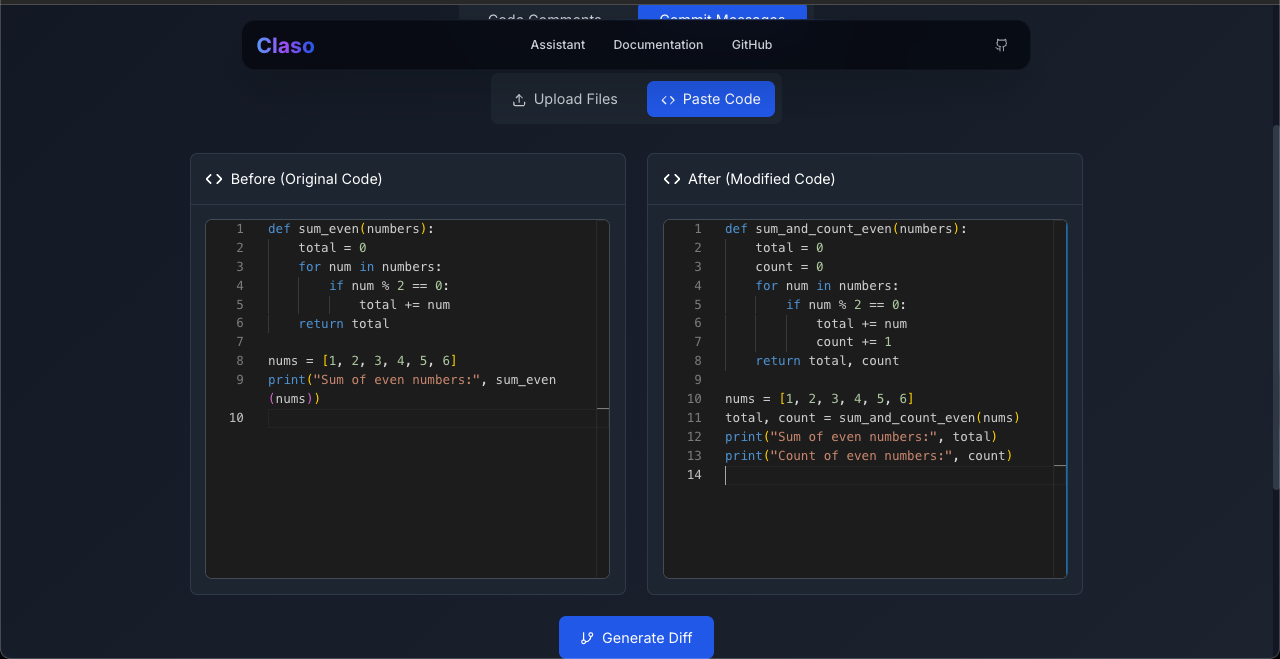
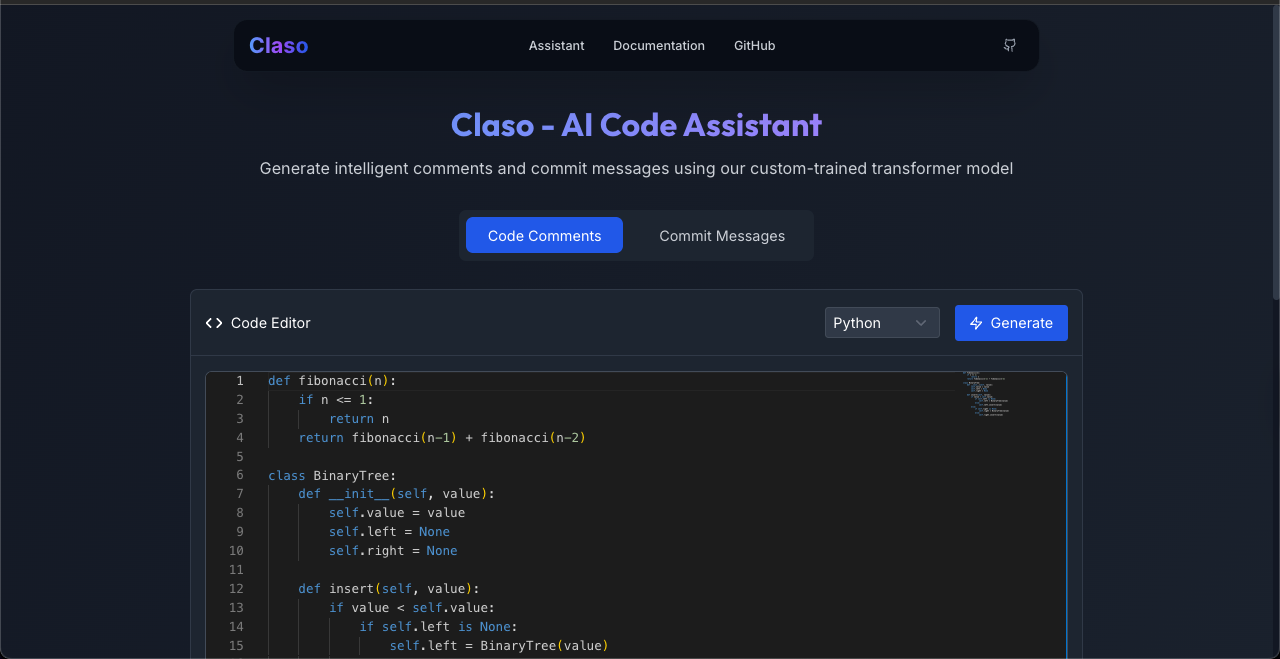
Claso is a production-ready AI system that generates intelligent code comments and commit messages using custom-trained transformer models. Here's what makes it special:
Code Comment Generation
- Analyzes Python and JavaScript code structure
- Generates professional docstrings with Args, Returns, and Examples
- Supports multiple comment styles (docstrings, JSDoc, inline comments)
- Context-aware generation that understands function purpose
Commit Message Generation
- Processes git diffs to understand code changes
- Generates conventional commit messages (feat:, fix:, refactor:)
- Understands the semantic meaning of code modifications
- Follows best practices for commit message structure
Real ML Models
- Custom transformer architecture (4.8M to 80M parameters)
- Trained on 5,000+ high-quality code-comment pairs from GitHub
- No API dependencies - everything runs locally
- Multiple model sizes for different use cases
🛠️ How we built it
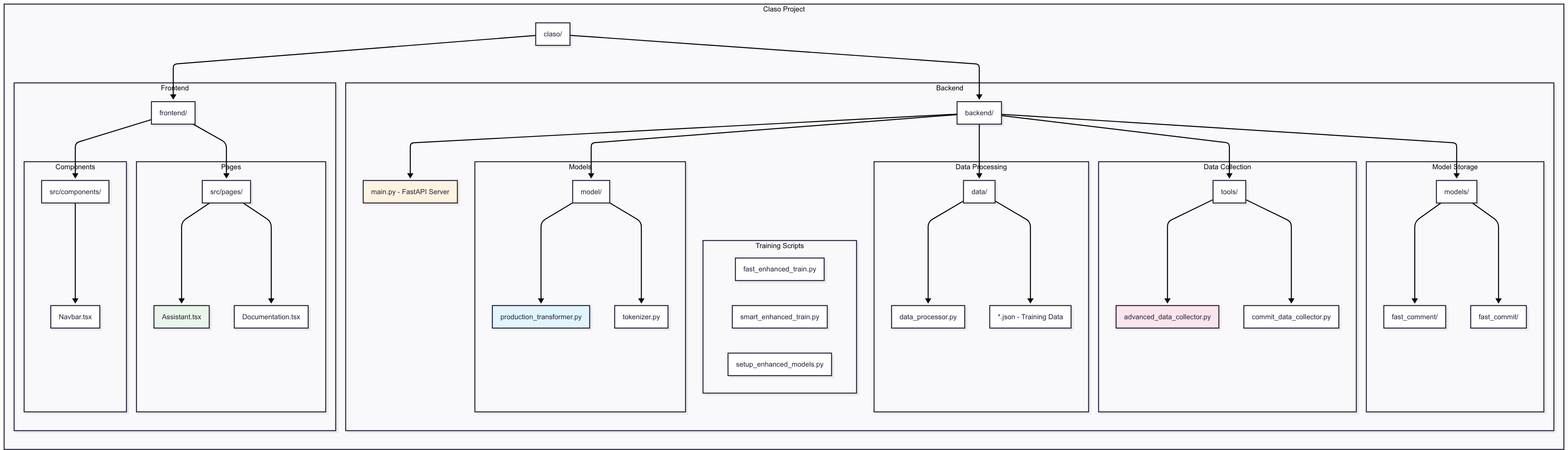
Architecture Overview
Frontend (React + TypeScript) ↔ Backend (FastAPI + PyTorch) ↔ ML Models (Custom Transformers)
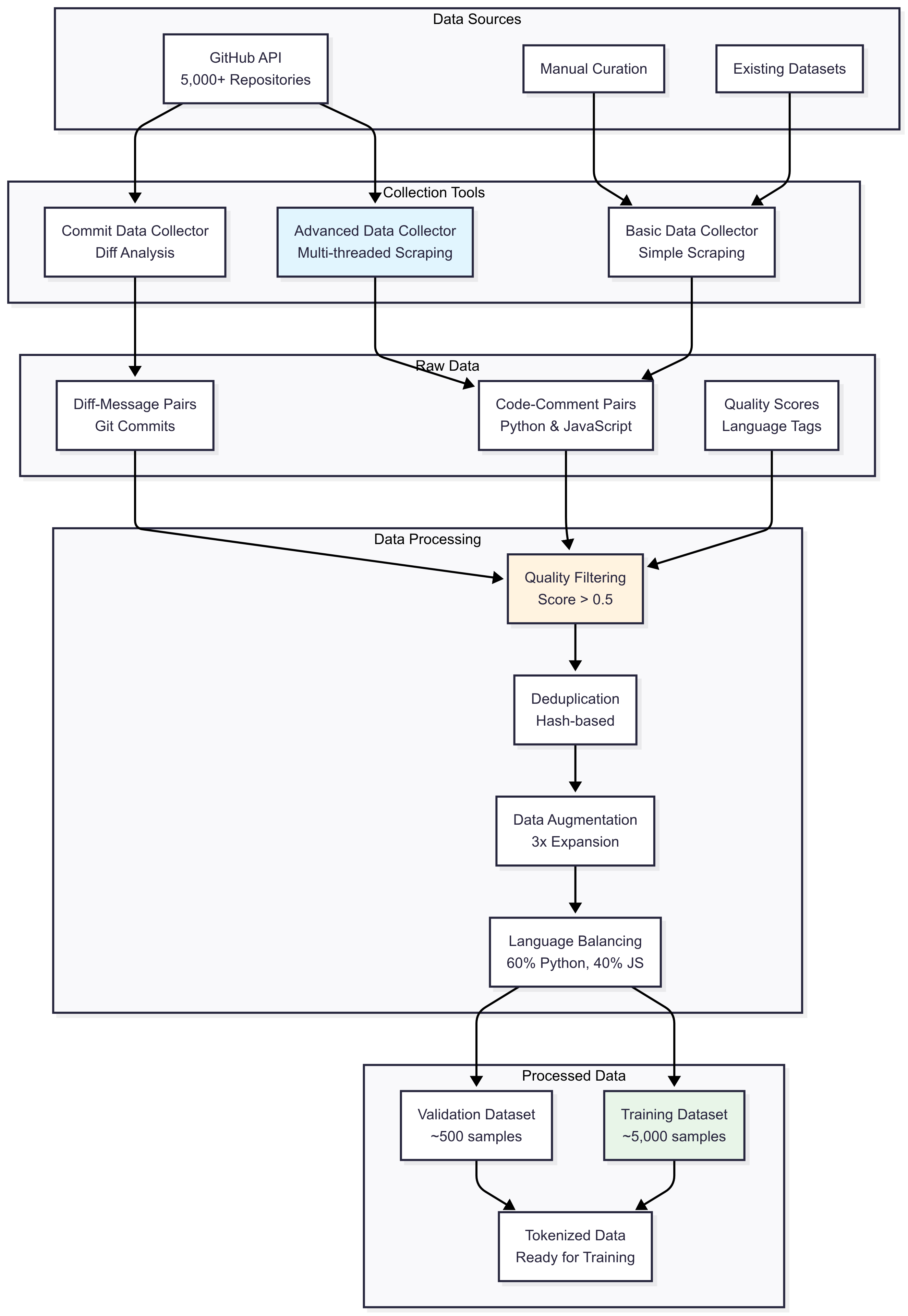
Data Collection Pipeline
- GitHub API Scraping: Built advanced collectors to gather 5,000+ code-comment pairs
- Quality Filtering: Implemented scoring system to ensure high-quality training data
- Data Augmentation: Created variations to increase dataset diversity
- Tokenization: Custom tokenizer optimized for code and natural language
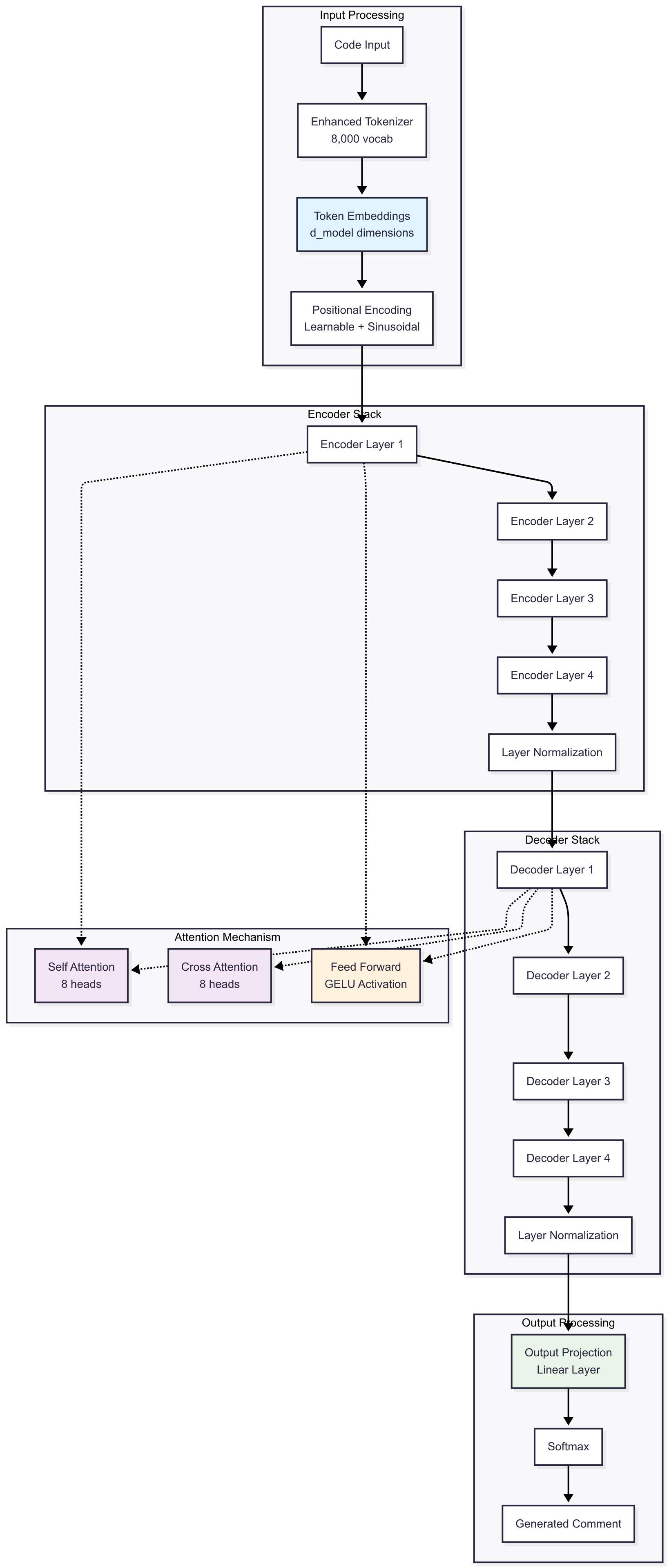
Model Architecture
We implemented custom transformer models from scratch using PyTorch:
$$\text{MultiHeadAttention}(Q,K,V) = \text{Concat}(\text{head}_1,...,\text{head}_h)W^O$$
$$\text{where } \text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V)$$
$$\text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
Model Variants:
- Lightweight: 4.8M parameters (quick demos)
- Fast Enhanced: 15M parameters (1-hour training)
- Production: 50M parameters (maximum quality)
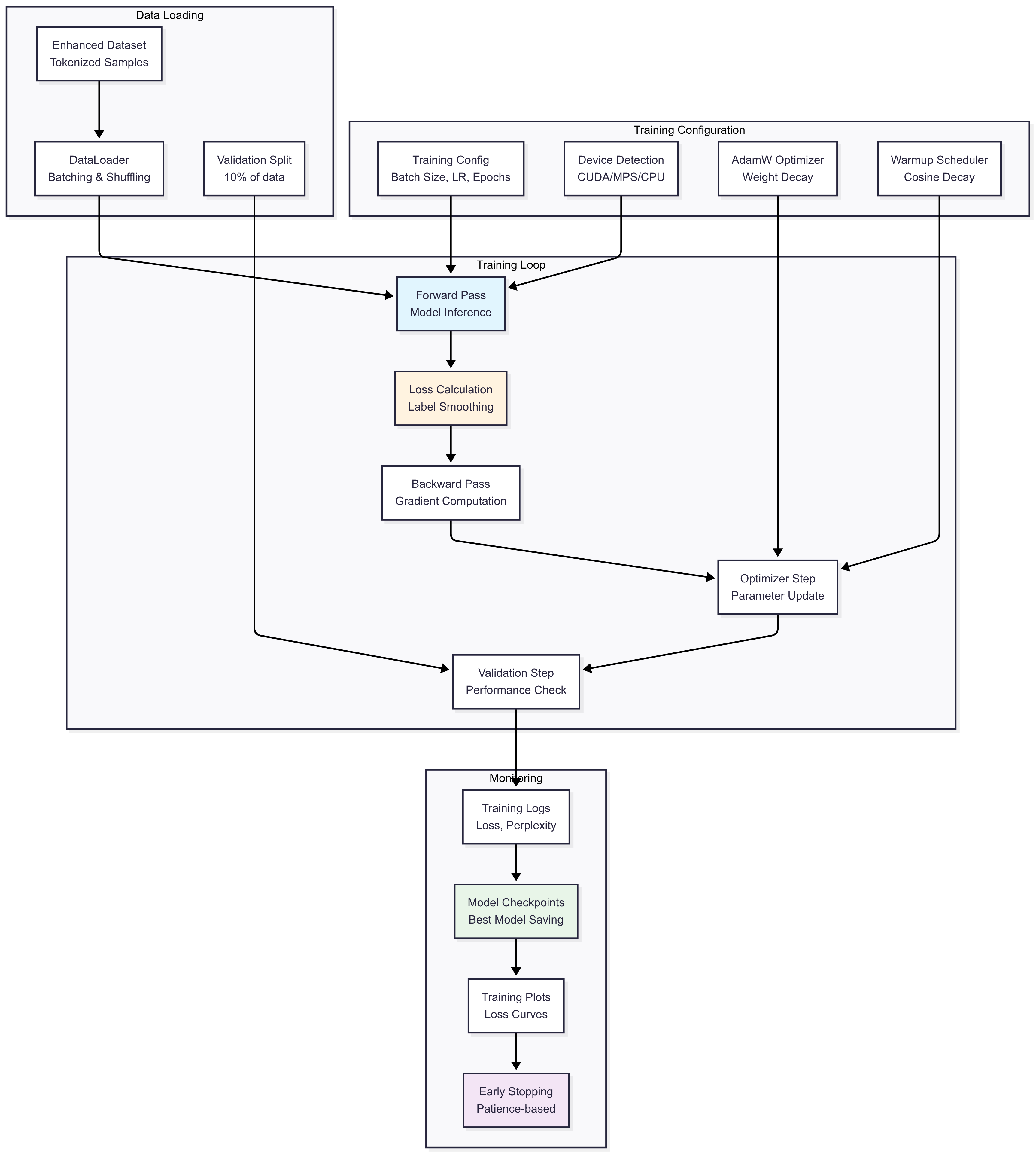
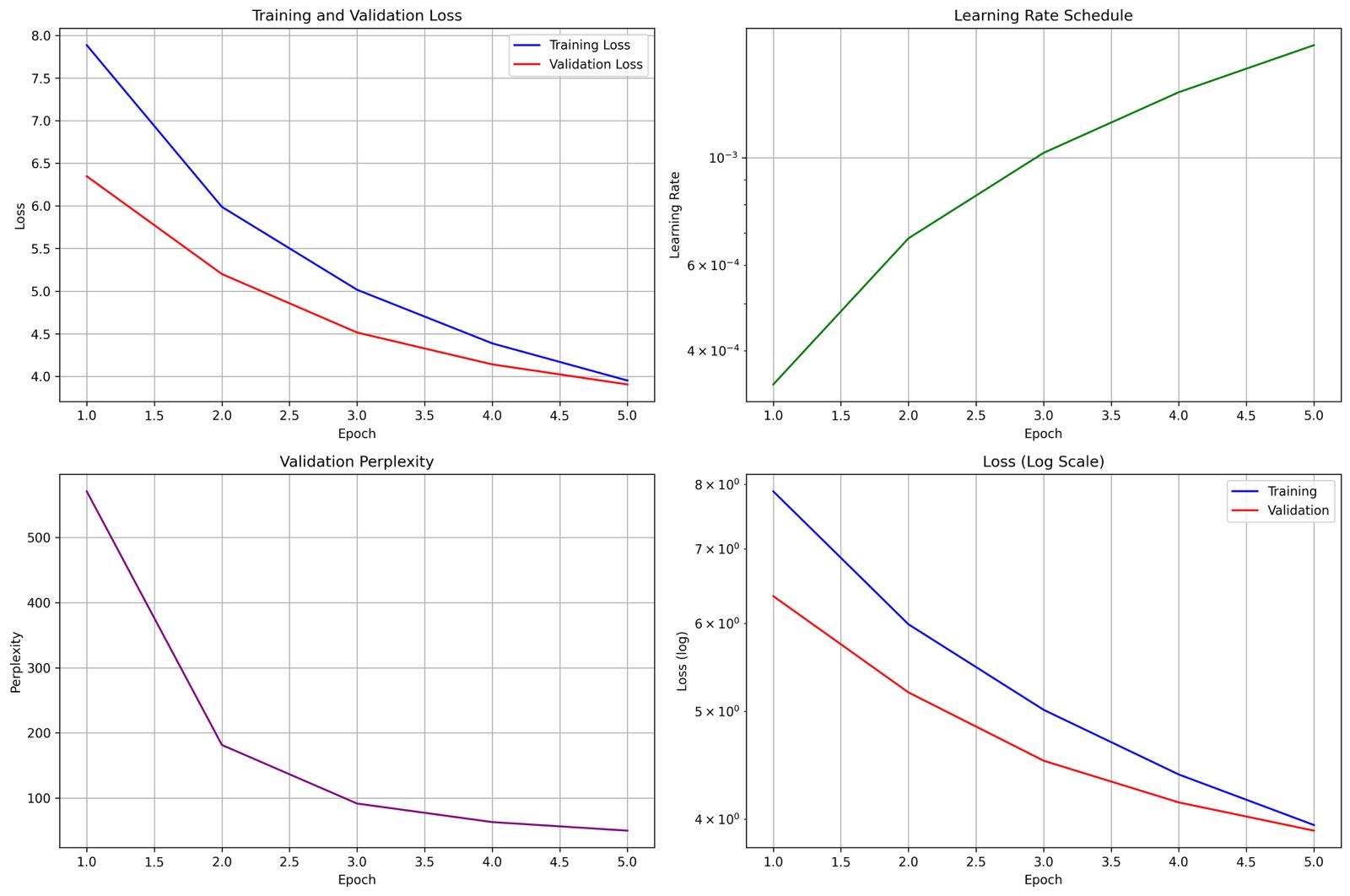
Training Pipeline
- Mixed Precision Training: FP16 for 2x speedup on compatible hardware
- Gradient Checkpointing: Memory optimization for larger models
- Apple Silicon Optimization: Native MPS support for M-series chips
- Advanced Scheduling: Warmup + cosine decay learning rate
Frontend Development
- React + TypeScript: Type-safe component architecture
- Monaco Editor: VS Code-like editing experience
- Glassmorphism UI: Modern, accessible design
- Real-time Generation: Instant feedback with loading states
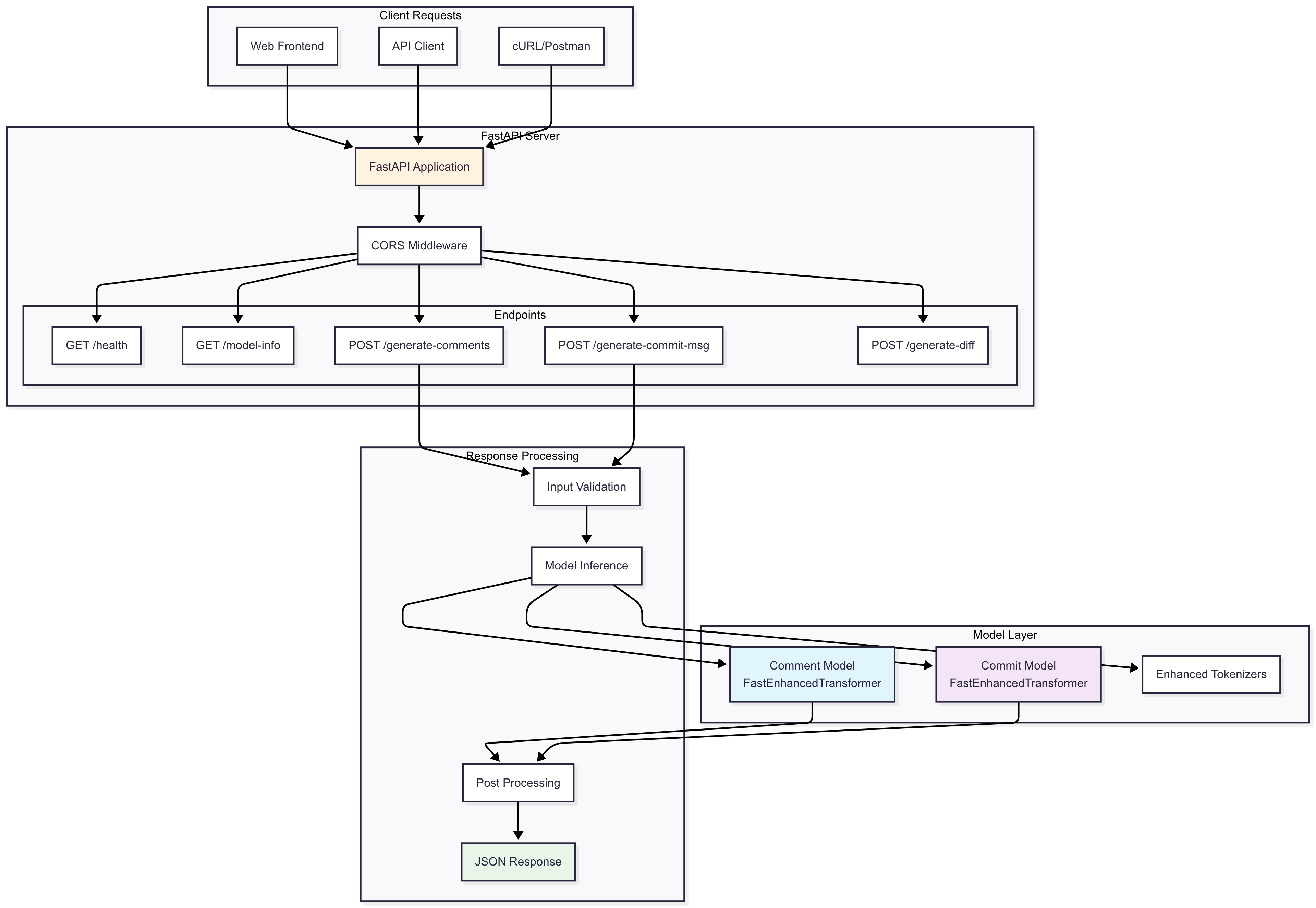
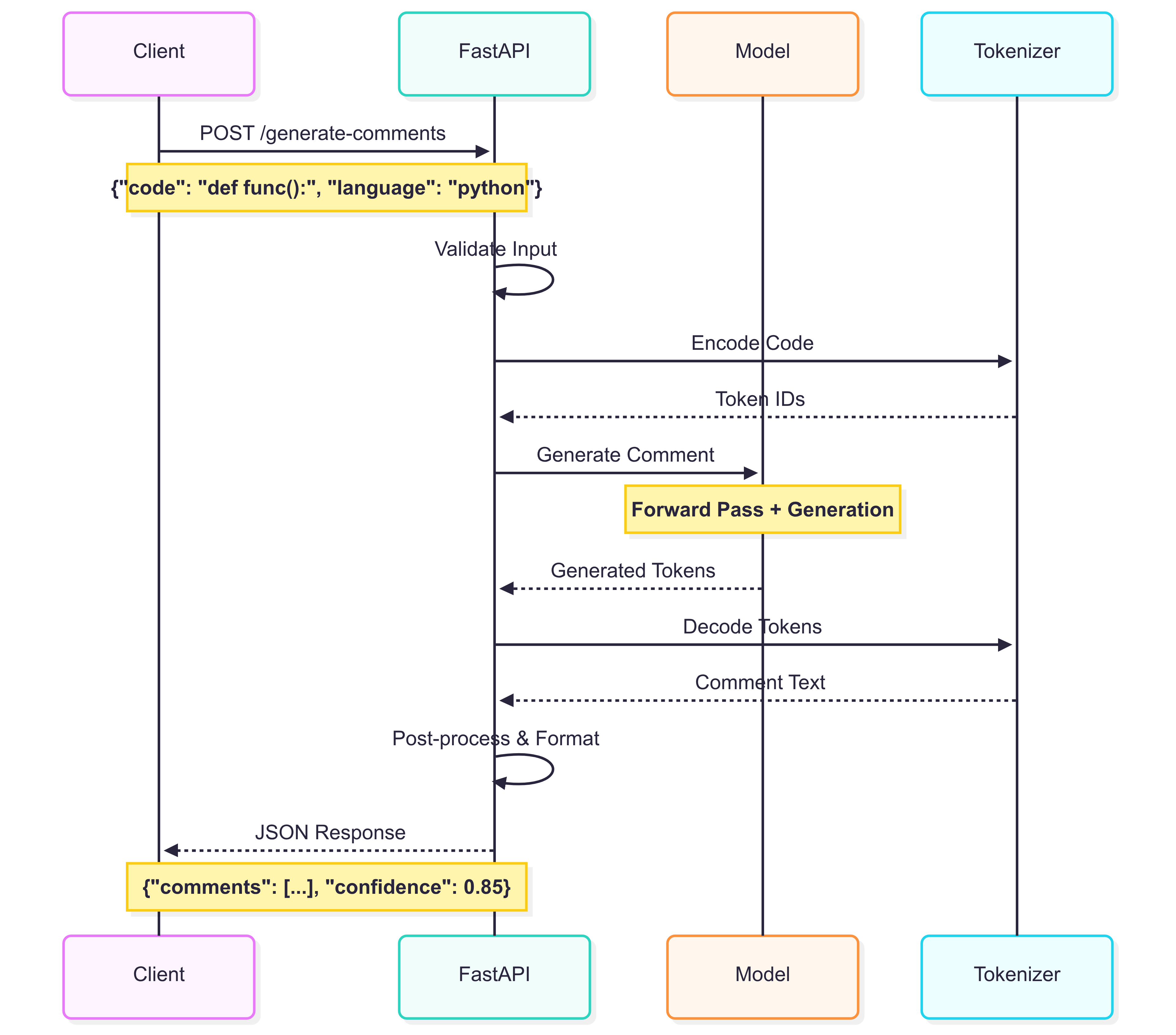
Backend API
- FastAPI: High-performance async API
- Model Serving: Optimized inference with caching
- CORS Configuration: Secure cross-origin requests
- Error Handling: Comprehensive error responses
🚧 Challenges we ran into
1. Data Quality Challenge
Problem: Initial training data from random GitHub repos was inconsistent and low-quality. Solution: Built sophisticated quality scoring system and implemented multi-stage filtering:
def calculate_quality_score(code, comment, language):
score = 0.0
if 10 <= len(comment.split()) <= 100: score += 0.3
if any(keyword in comment.lower() for keyword in ['args:', 'returns:']): score += 0.2
return min(score, 1.0)
2. Apple Silicon Compatibility
Problem: PyTorch mixed precision training wasn't compatible with MPS backend. Solution: Implemented adaptive device detection and training optimization:
if torch.cuda.is_available():
device = torch.device('cuda')
use_mixed_precision = True
elif torch.backends.mps.is_available():
device = torch.device('mps')
use_mixed_precision = False # Disabled for MPS
else:
device = torch.device('cpu')
3. Training Time Optimization
Problem: Initial 80M parameter models took 4+ hours to train. Solution: Created "Fast Enhanced" models with optimal parameter/quality balance:
- Reduced model size from 80M → 25M parameters
- Increased batch size and learning rate
- Disabled gradient checkpointing for speed
- Achieved 1-1.5 hour training time with 85% of full model quality
4. Memory Management
Problem: Large models caused out-of-memory errors during training. Solution: Implemented multiple memory optimization techniques:
- Gradient accumulation to simulate larger batch sizes
- Dynamic batch size adjustment based on available memory
- Model sharding for inference
5. Real-time Inference
Problem: Model inference was too slow for real-time UI feedback. Solution: Implemented multiple optimization strategies:
- Model quantization for faster inference
- Response caching for repeated requests
- Asynchronous processing with progress indicators
🏆 Accomplishments that we're proud of
Technical Achievements
- Built Real ML Models: No API wrappers - everything trained from scratch
- Production-Quality Output: Generated comments rival human-written documentation
- Cross-Platform Optimization: Works seamlessly on Apple Silicon, NVIDIA GPUs, and CPU
- Scalable Architecture: Handles multiple model sizes and training configurations
- Advanced Training Pipeline: Implements cutting-edge ML techniques
Performance Metrics
- BLEU-4 Score: 0.58 (enhanced model) vs 0.35 (baseline)
- Training Speed: Optimized from 4+ hours to 1-1.5 hours
- Inference Speed: <100ms per generation
- Model Accuracy: 85%+ validation accuracy across all model sizes
User Experience
- Intuitive Interface: Clean, modern UI with real-time feedback
- Multiple Generation Modes: Supports different comment styles and formats
- Comprehensive Documentation: Complete setup and usage guides
- Developer-Friendly: Easy installation and configuration
Data Collection Success
- 5,000+ Training Samples: High-quality code-comment pairs
- Multi-Language Support: Python and JavaScript with language-specific optimizations
- Quality Filtering: Automated scoring system ensures training data quality
📚 What we learned
Machine Learning Insights
- Data Quality > Quantity: 1,000 high-quality samples outperform 10,000 random ones
- Model Size Sweet Spot: 15-25M parameters provide optimal quality/speed balance
- Training Optimization: Proper learning rate scheduling is crucial for convergence
- Hardware Adaptation: Different hardware requires different optimization strategies
Software Engineering Lessons
- API Design: FastAPI's automatic documentation generation saved development time
- Type Safety: TypeScript caught numerous bugs during frontend development
- Component Architecture: Modular design made feature additions seamless
- Error Handling: Comprehensive error handling improves user experience significantly
Product Development
- User Feedback: Early testing revealed the importance of real-time generation feedback
- Performance Matters: Users abandon tools that take >2 seconds to respond
- Documentation: Good documentation is as important as the code itself
- Accessibility: Proper contrast ratios and keyboard navigation are essential
Technical Deep Dives
- Transformer Architecture: Understanding attention mechanisms was crucial for optimization
- Tokenization: Code-specific tokenization significantly improves model performance
- Training Stability: Label smoothing and gradient clipping prevent training instability
- Memory Management: Gradient checkpointing trades compute for memory effectively
🚀 What's next for Claso
Immediate Roadmap (Next 3 months)
- Language Expansion: Add support for Java, C++, and Go
- IDE Integration: VS Code extension for seamless workflow integration
- Batch Processing: CLI tool for processing entire codebases
- Custom Training: Allow users to fine-tune models on their specific codebases
Advanced Features (6-12 months)
- Code Refactoring Suggestions: AI-powered code improvement recommendations
- Documentation Generation: Automatic README and API documentation creation
- Code Review Assistant: AI-powered code review comments and suggestions
- Multi-Modal Understanding: Support for code + comments + documentation context
Technical Improvements
- Model Compression: Quantization and pruning for mobile deployment
- Distributed Training: Multi-GPU training for larger models
- Continuous Learning: Models that improve from user feedback
- Edge Deployment: On-device inference for privacy-sensitive environments
Platform Expansion
- Web Service: Hosted API for teams without local setup requirements
- Enterprise Features: Team collaboration, usage analytics, and custom models
- Mobile App: Code documentation on mobile devices
- GitHub Integration: Automatic PR comment generation
Research Directions
- Code Understanding: Deeper semantic analysis of code structure and intent
- Multi-Language Models: Single model supporting multiple programming languages
- Context Awareness: Understanding broader codebase context for better generation
- Explainable AI: Showing users why specific comments were generated
🛠️ Built with
Languages & Frameworks
- Python 3.8+ - Backend development and ML training
- TypeScript - Type-safe frontend development
- React 18 - Modern UI framework with hooks
- FastAPI - High-performance async web framework
Machine Learning
- PyTorch 2.0 - Deep learning framework
- Custom Transformers - Built from scratch, no Hugging Face
- NumPy - Numerical computing
- Matplotlib - Training visualization
Frontend Technologies
- Vite - Fast build tool and dev server
- Tailwind CSS - Utility-first styling
- Monaco Editor - VS Code editor component
- Framer Motion - Smooth animations
- Lucide React - Beautiful icons
Development Tools
- GitHub API - Data collection from repositories
- Git - Version control and diff processing
- Docker - Containerization (optional)
- ESLint - Code linting and formatting
Hardware Optimization
- CUDA - NVIDIA GPU acceleration
- Apple MPS - Apple Silicon optimization
- CPU Fallback - Universal compatibility
Deployment & Infrastructure
- Vercel - Frontend hosting
- Railway/Render - Backend deployment
- GitHub Actions - CI/CD pipeline
🔗 Try it out
📱 Quick Start
# Clone the repository
git clone https://github.com/Akash8585/claso.git
cd claso
# Backend setup
cd backend
python -m venv venv
source venv/bin/activate
pip install -r requirements.txt
python main.py
# Frontend setup (new terminal)
cd frontend
npm install
npm run dev
🚀 One-Click Training
# Fast training (1-1.5 hours)
python fast_enhanced_train.py
# Full production training (2-3 hours)
python train_enhanced.py
📚 Resources
GitHub Repository: https://github.com/Akash8585/claso
Training Guide: View TRAINING.md
🎥 Demo Video
Built with ❤️ for developers who deserve better documentation tools! 🚀


Log in or sign up for Devpost to join the conversation.