





Predicting Clash Royale Battle Outcomes from Deck Composition
Inspiration
Clash Royale is a deceptively deep game. On the surface, it's a mobile card battler — but underneath lies a rich combinatorial strategy space: 120 cards, infinite deck configurations, and real-time tactical decisions. As data science students, we asked a question that any competitive player obsesses over:
Does your deck actually matter — or is it just your skill and card levels?
This is harder to answer than it sounds. A player might win not because their deck is better, but because they're more experienced, or because their cards are higher level. We wanted to isolate the strategic signal of deck composition itself, stripped of those confounders. That challenge — equal parts data engineering and machine learning — is what drew us in.
What We Built
1. A Live Data Crawler
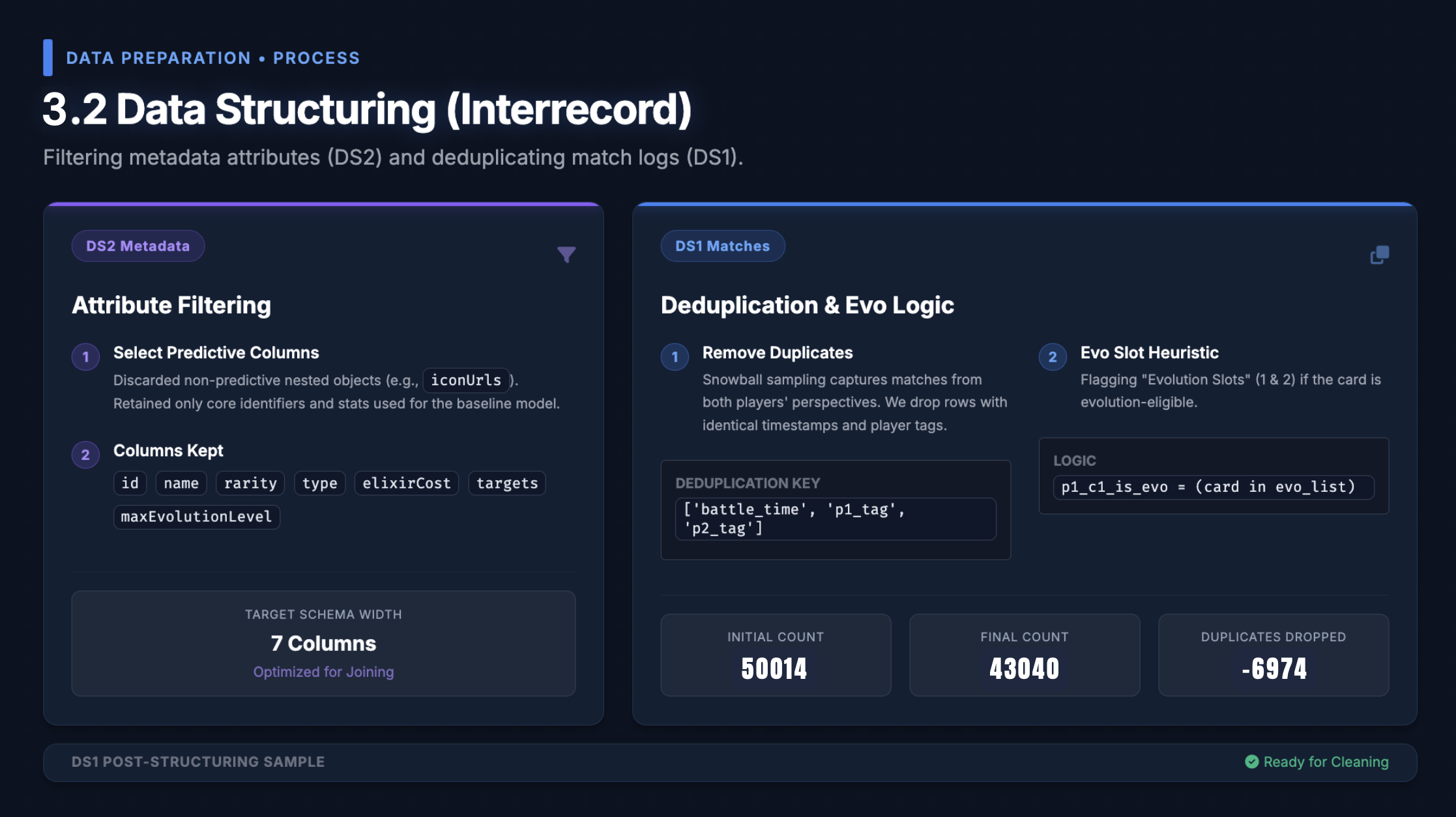
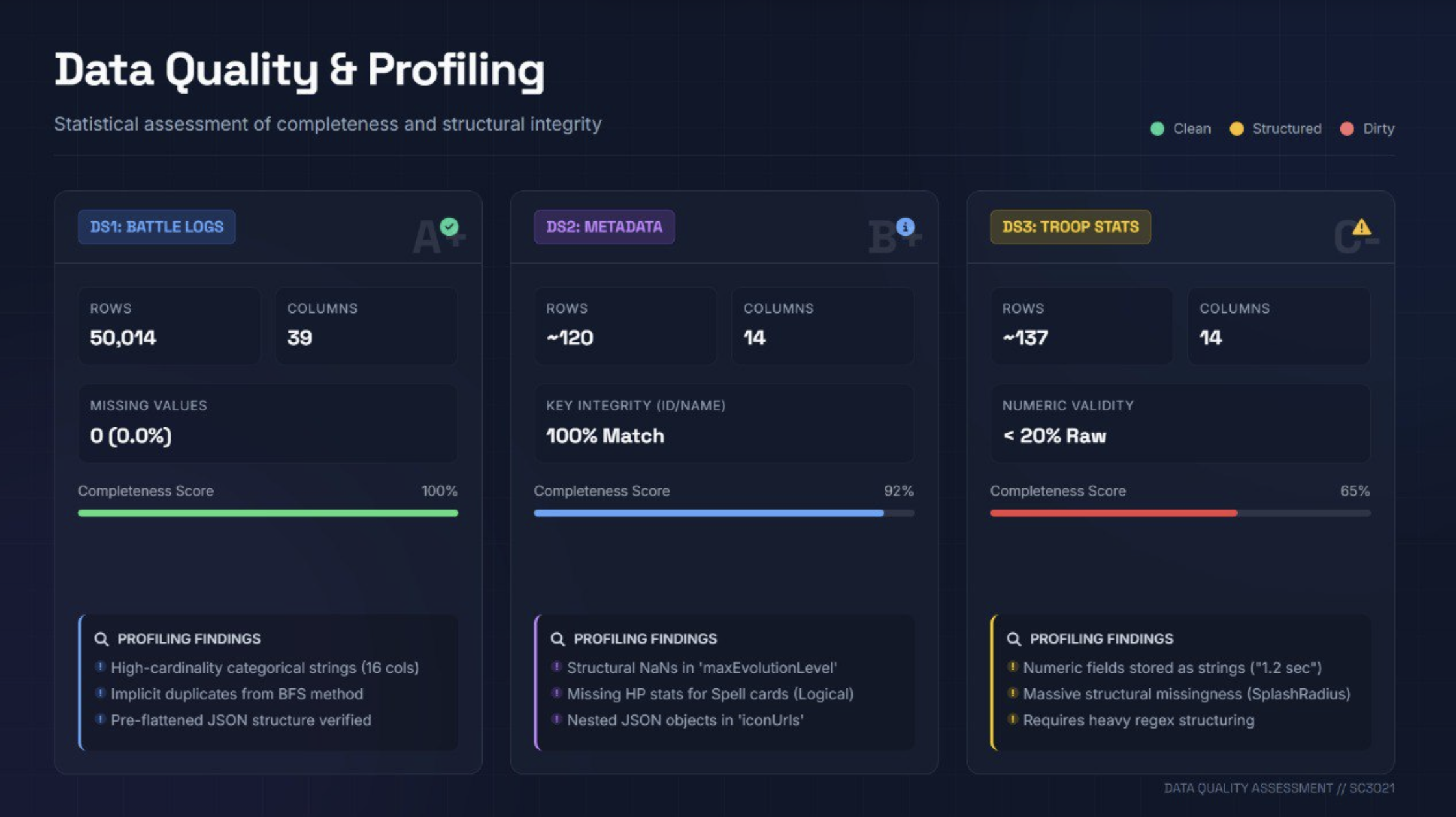
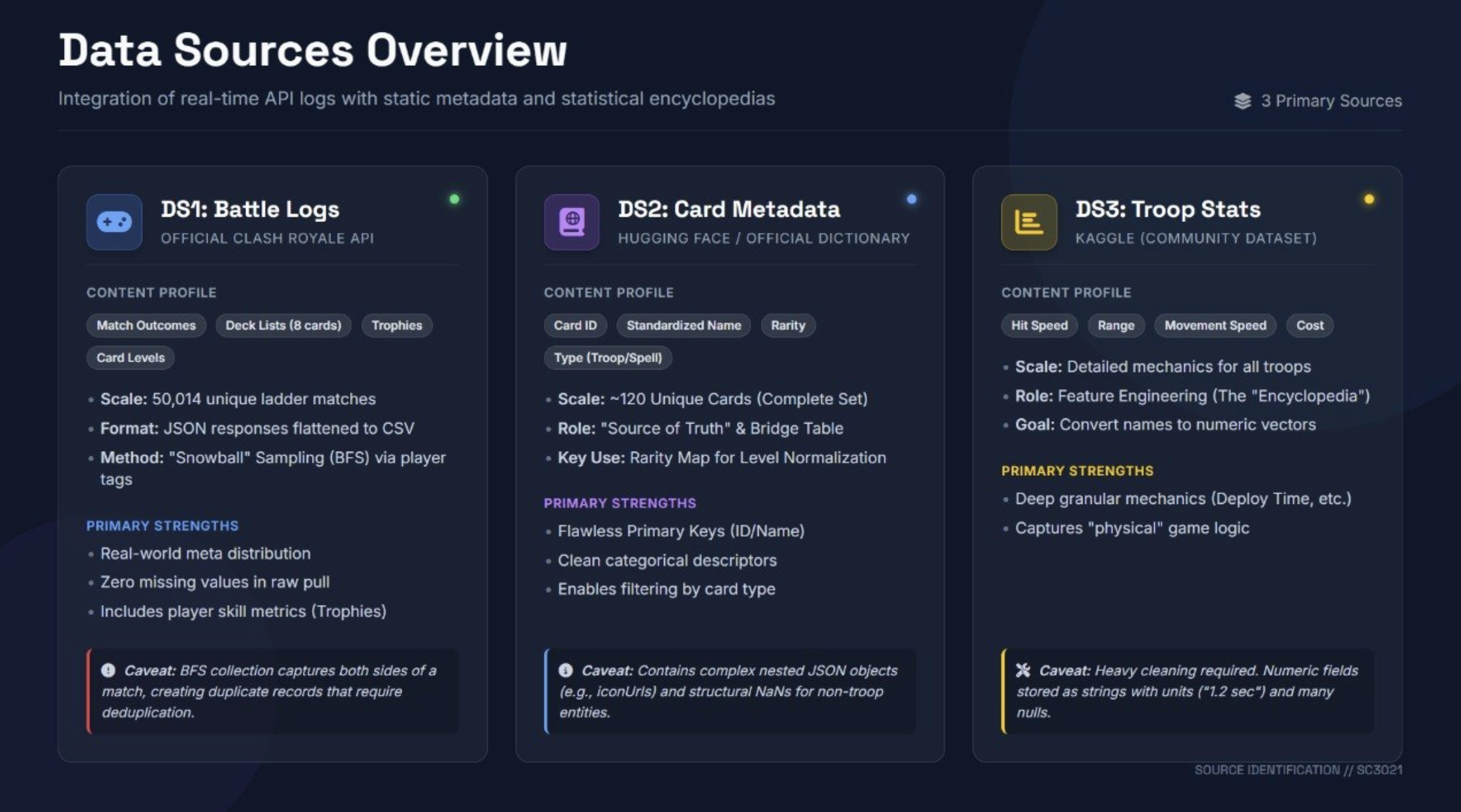
The Clash Royale API doesn't offer a global match feed — you can only query individual players. So we built a Snowball Spider: a Breadth-First Search crawler that starts from a seed list of players, extracts their battle logs, discovers their opponents' tags, and recursively queues them. The result: over 50,000 ladder matches collected entirely through chained API calls.
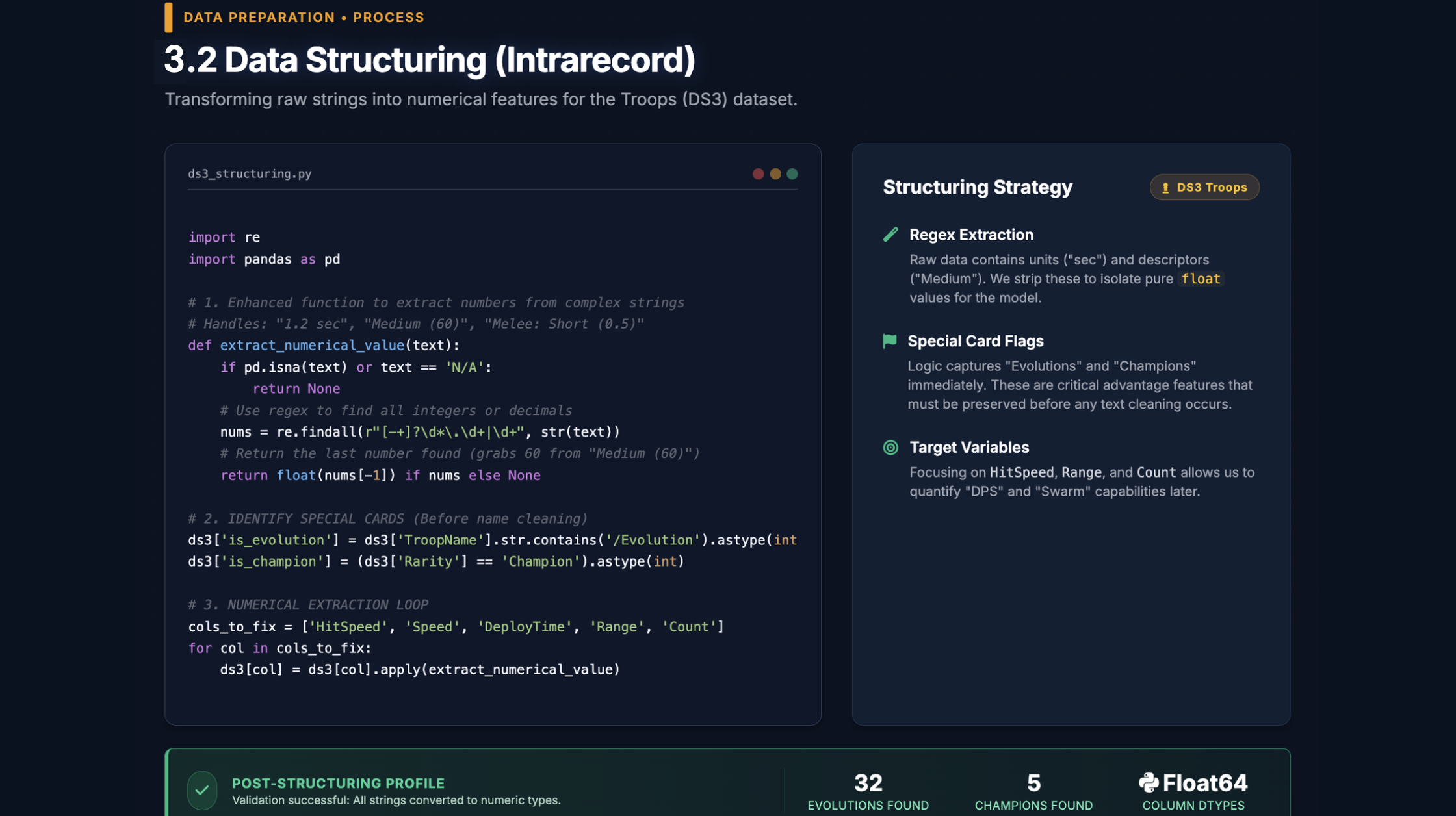
The crawler also included a rarity-aware level normalisation step. Because the API reports raw internal levels that differ by card rarity (a Level 1 Legendary ≠ a Level 1 Common), we mapped every card to its in-game "standard level" on extraction to ensure fair numerical comparisons downstream.
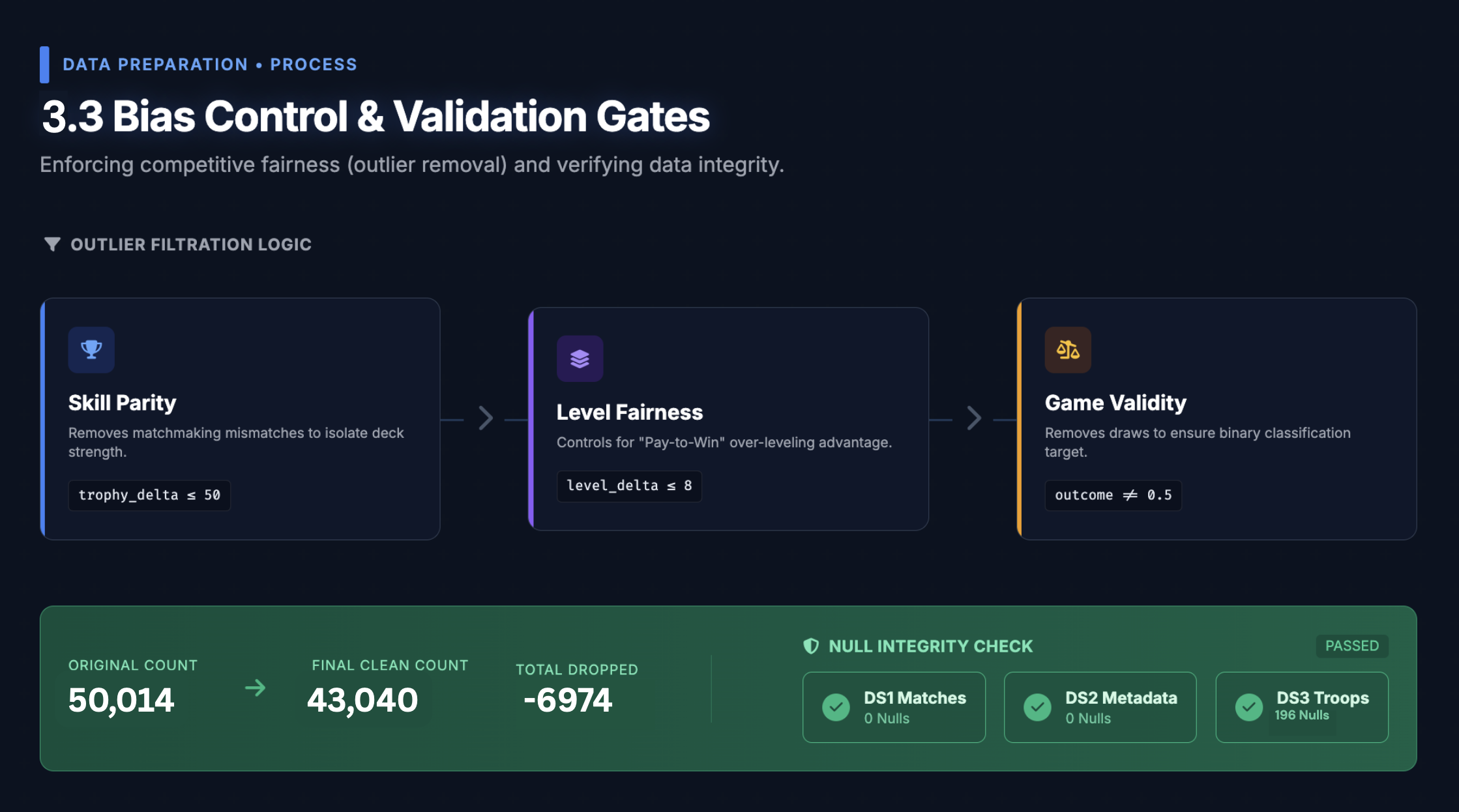
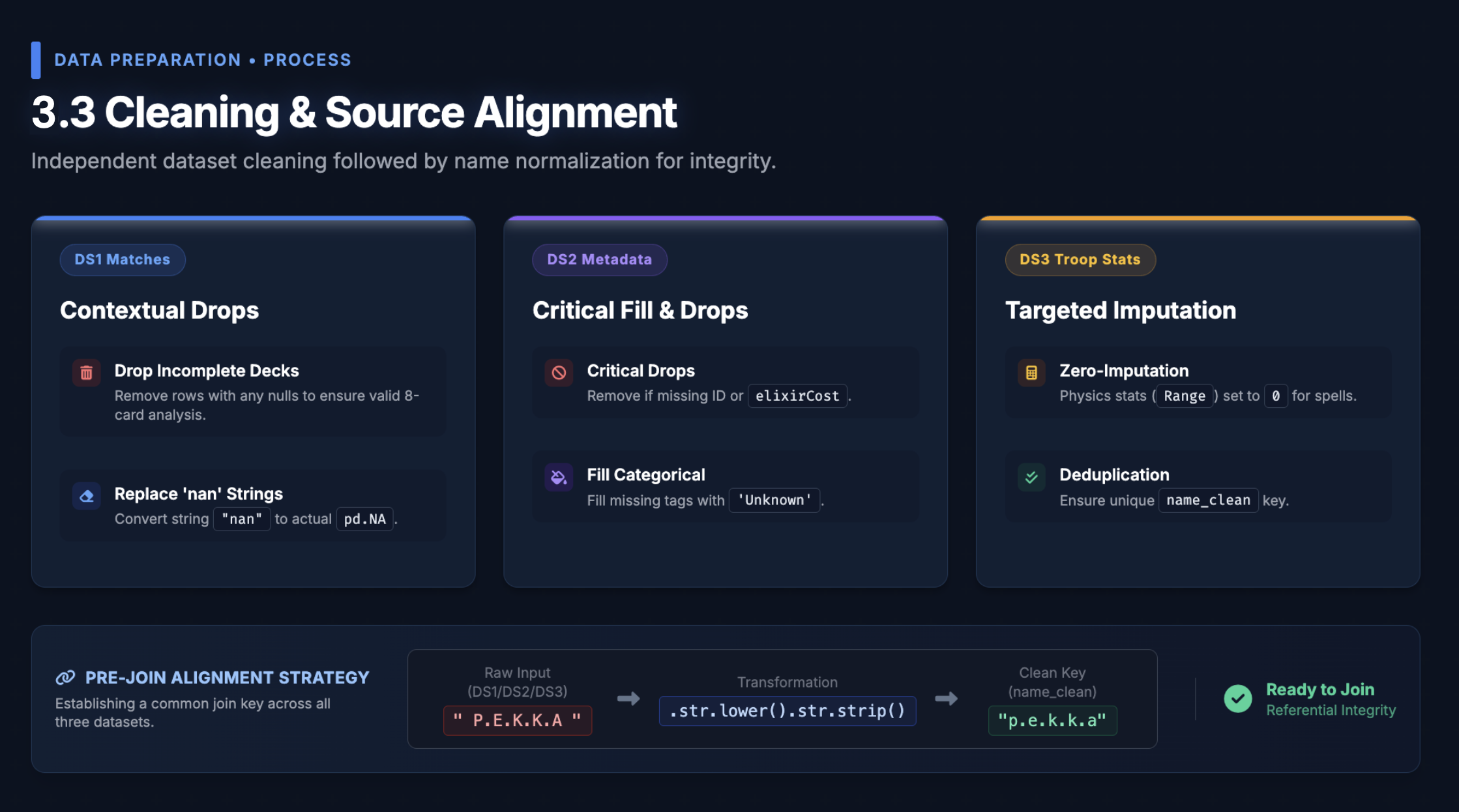
2. Confounding Control via Strict Filtering
A key insight from the start: raw battle data is noisy with non-deck factors. We applied two hard filters before modelling:
- Trophy parity: $|\Delta T| \leq 50$ — removing skill mismatches
- Level parity: Total card level delta $= 0$ — removing pay-to-win bias
This substantially reduced our dataset, but gave us a cleaner signal to work with — matches where deck composition was the dominant differentiator.
3. Multi-Source Feature Engineering
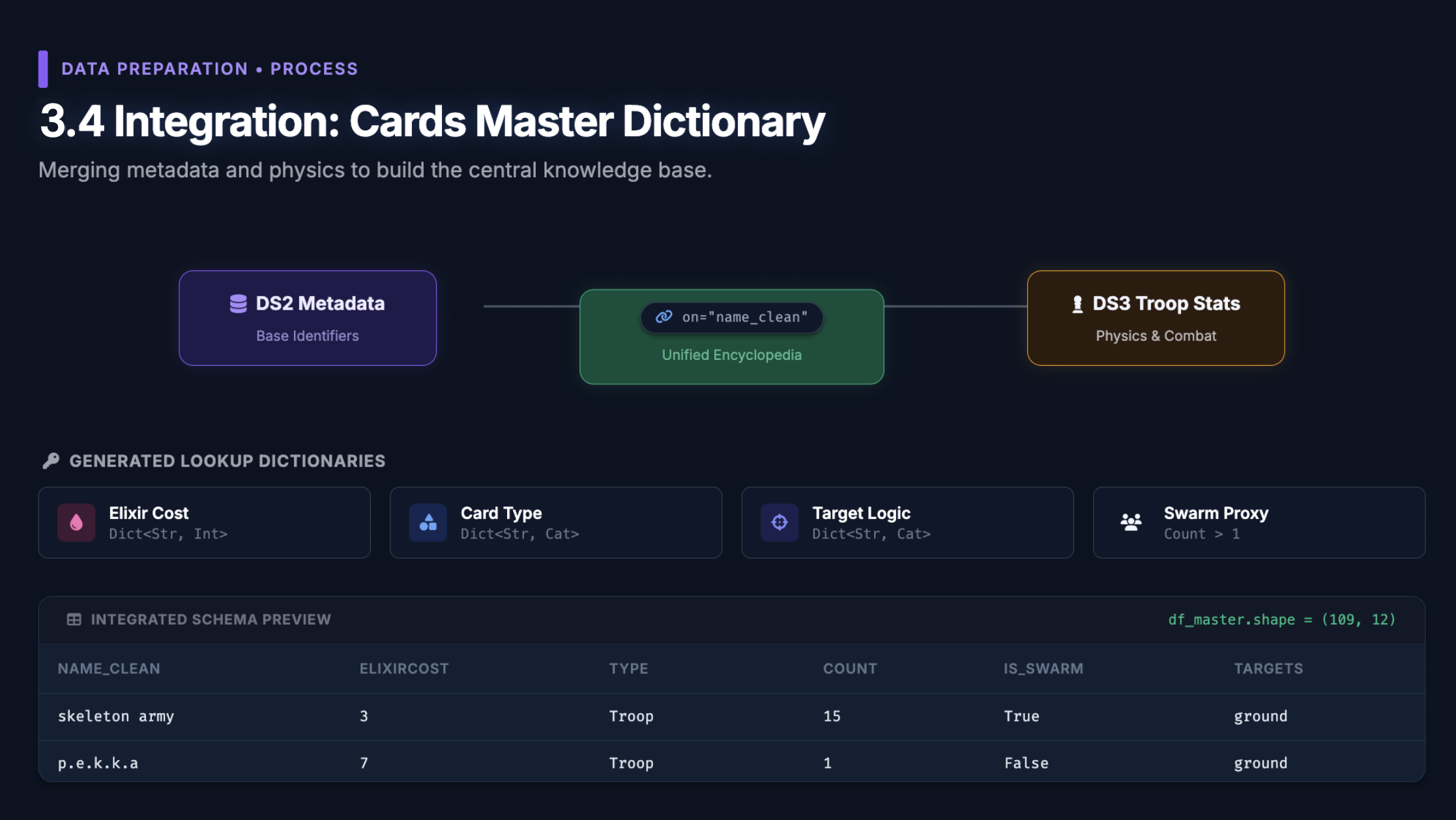
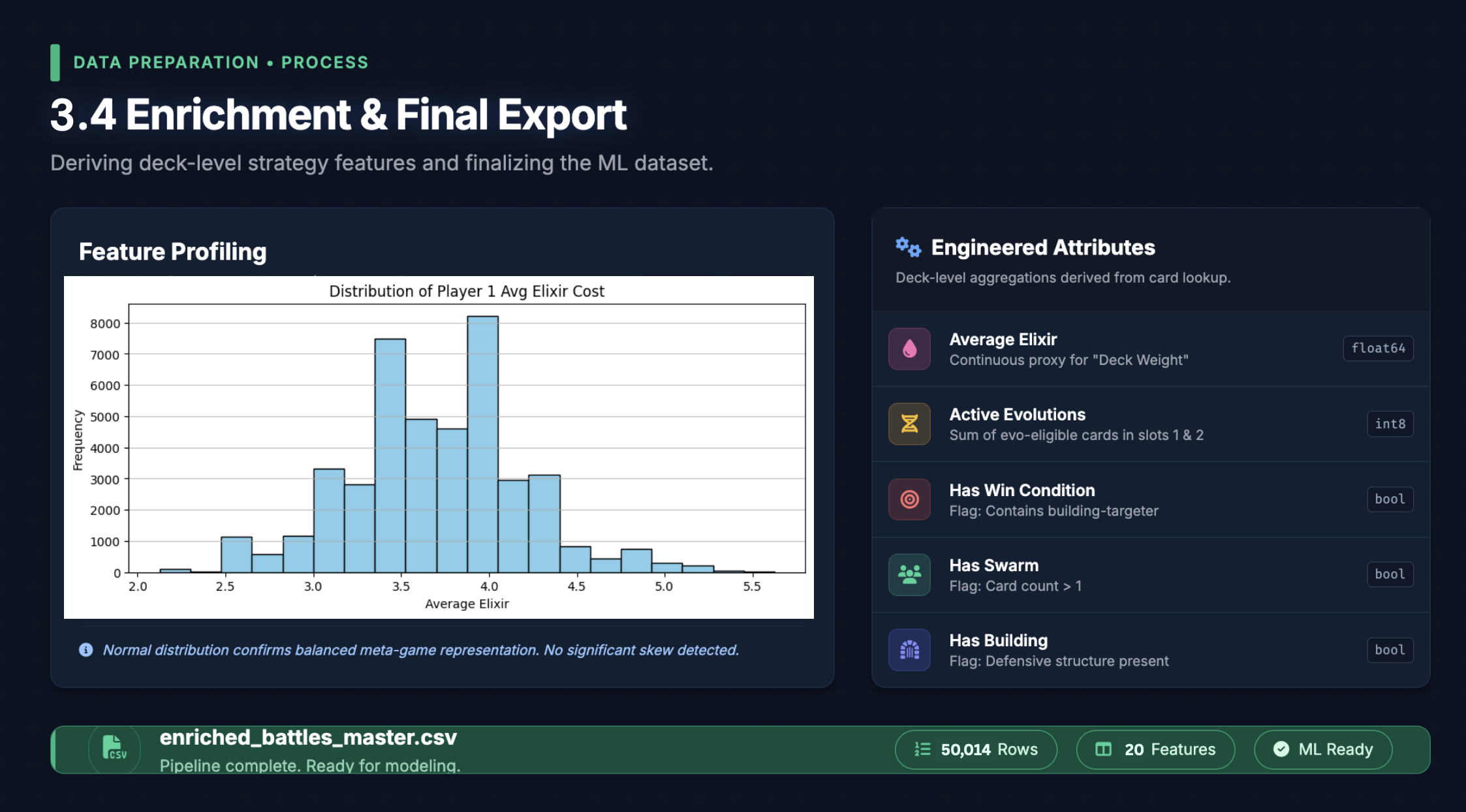
We enriched our filtered battle records with card metadata from Hugging Face and Kaggle to build a feature space that captured:
- One-hot card presence (~240 binary features for both players' decks)
- Deck archetype descriptors: splash count, air troop count, building count, swarm count, spell count, win condition count
- Elixir economy: average elixir cost per deck (cycle speed proxy)
- Matchup delta features: air vs. anti-air advantage, splash vs. swarm advantage, HP pool advantage, ranged unit advantage
- Evolution advantage: active evolution slots per player
- Synergy combo flags: co-occurrence-based combo patterns mined from historical deck data
4. Three-Model ML Shootout
We trained and tuned three classifiers on the engineered feature space:
| Model | Train Acc | Test Acc | ROC-AUC | Log Loss |
|---|---|---|---|---|
| XGBoost | 61.99% | 58.21% | 0.5952 | 0.6825 |
| Random Forest | 60.89% | 56.42% | 0.5920 | 0.6848 |
| MLP (Neural Network) | 64.47% | 54.31% | 0.5546 | 0.7115 |
We benchmarked against an Elo-style reference score:
$$E_A = \frac{1}{1 + 10^{(R_B - R_A)/400}}$$
A 50-trophy gap corresponds to a theoretical win probability of ~57.1%. Our XGBoost model exceeded this benchmark, confirming that deck composition carries real predictive signal — even after controlling for skill and levels.
The MLP, while capable of detecting patterns, suffered the largest overfitting gap (10.16%) and produced the weakest generalisation, suggesting that the structured nature of our feature space is better suited to tree-based learners than to the current neural network configuration.
Challenges We Faced
API Rate Limiting & IP Whitelisting
The Supercell API locks keys to specific IP addresses — problematic in a Colab
environment where the server IP changes every session. We built an automated
IP-fetch step into our workflow so the key could be updated at the start of
each session.
Deeply Nested JSON
Each battle response is a heavily nested dictionary — navigating
battle['team'][0]['cards'][0]['name'] across 50,000 records, with rarity
normalisation applied on the fly, required careful engineering to avoid
malformed rows and silent data corruption.
Confounding Factor Removal vs. Sample Size
Our strictest filter — requiring zero total card level delta — dramatically
reduced the final modelling set. Balancing statistical validity against sample
representativeness was a constant tension throughout the project.
Feature Leakage Risk
Some synergy combo features were mined from the full dataset before the
train/test split. In a production-grade pipeline, combo discovery should be
confined to training data only. We flag this as a methodological limitation
and treat reported metrics as informative rather than definitive.
The Honesty of a Moderate Result
Perhaps the most intellectually honest challenge: our best model only reached
~58% accuracy. Rather than overselling this, we built a proper benchmark
framework — the Elo reference score — that put 58% into context as genuinely
meaningful, while acknowledging that deck structure is only one piece of what
determines a Clash Royale outcome. In-battle execution, timing, and adaptation
still matter enormously. That's probably a feature of the game's design, not a
flaw in our analysis.
What We Learned
- How to design a graph-traversal data collection engine when no global dataset endpoint exists
- How to apply domain-informed confounding control (rather than just throwing raw data at a model)
- How to interpret moderate predictive performance honestly using theory-grounded benchmarks instead of chasing inflated accuracy numbers
- That XGBoost consistently outperforms MLP on structured tabular data with complex categorical features — a lesson reinforced repeatedly in the literature and now in our own results
- The ethical dimensions of large-scale player data harvesting from a public API, and the importance of hashing identifiers before any external data sharing
Built With
- evolution-data)-tools-&-platforms:-jupyter-notebook
- feature-engineering
- github-(dataset-hosting)
- google-colab-(execution-environment)-ml-models:-xgboost-classifier
- matplotlib
- mlp
- move-speed
- multi-layer-perceptron-(mlp)-techniques:-snowball-sampling-/-bfs-graph-traversal
- numpy
- one-hot-encoding
- pandas
- permutation-importance
- random-forest-classifier
- randomizedsearchcv-hyperparameter-tuning
- range
- requests-apis-&-data-sources:-supercell-official-clash-royale-api-(live-battle-logs-via-dynamic-ip-whitelisting)-hugging-face-datasets-?-clash-royale-cards-metadata-kaggle-?-clash-royale-troops-(combat-stats:-hit-speed
- roc-auc-evaluation
- scikit-learn
- seaborn
- statsmodels
- xgboost

Log in or sign up for Devpost to join the conversation.