

🎬 Trailer
🗺️ Website
GitHub
Inspiration
We were inspired by two adjacent issues.
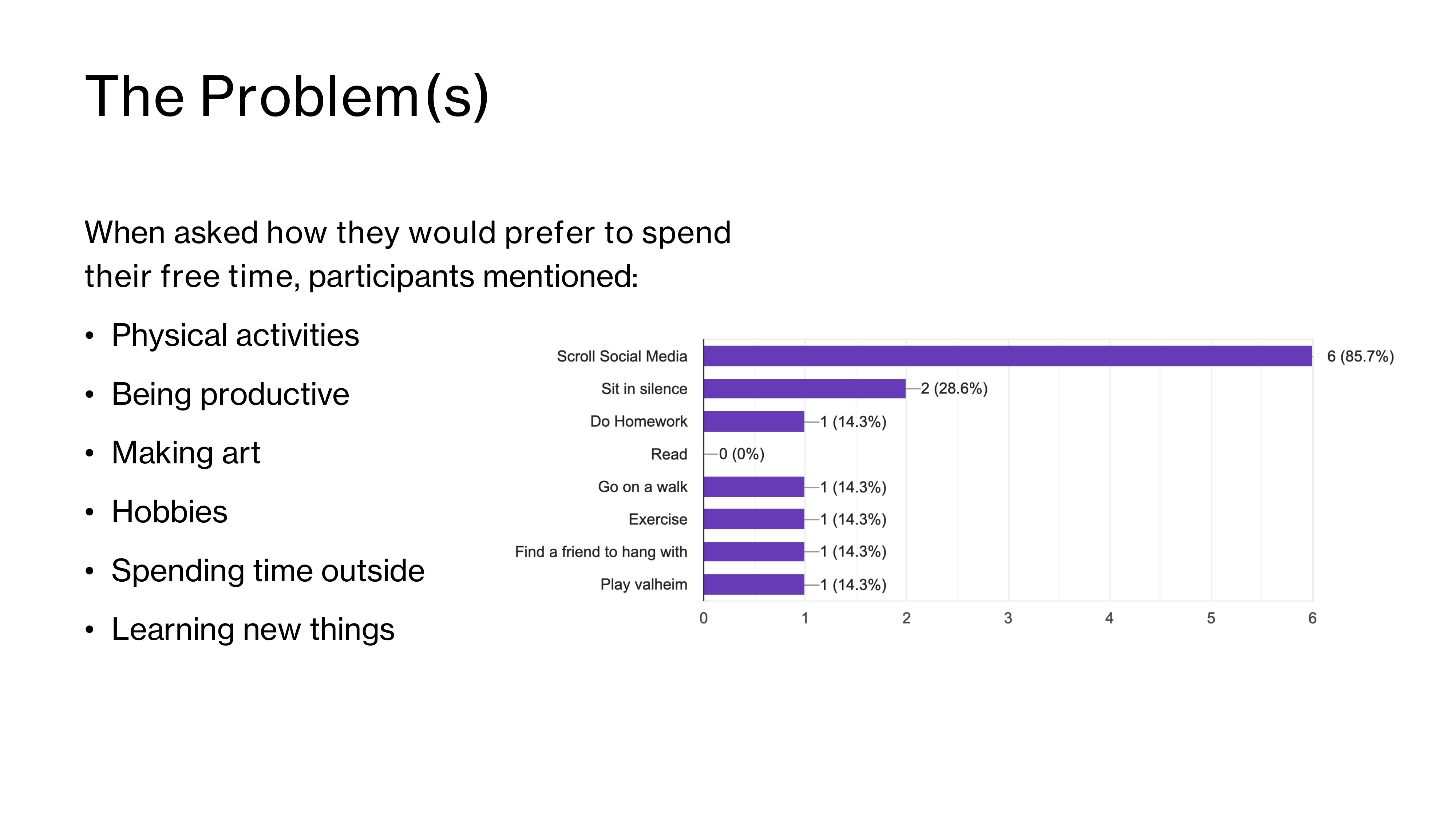
Social media is becoming the default to fill free time, especially among students.
Simultaneously, campus events are under attended and poorly advertised. The existing methods of finding events at Clark are tedious, overwhelming, and cant compete with the immediacy social media provides. We wanted to create a platform which makes finding an event to go to or an activity to do around clark as easy and as immediate as finding a video on social media.
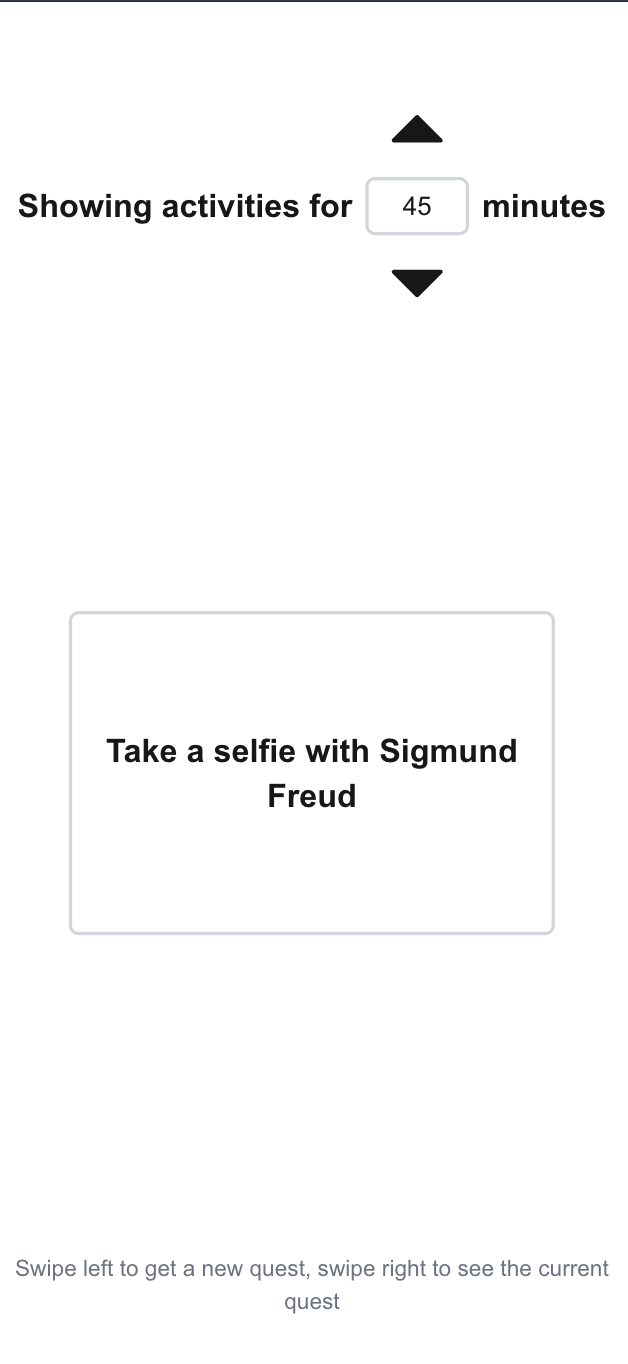
What it does
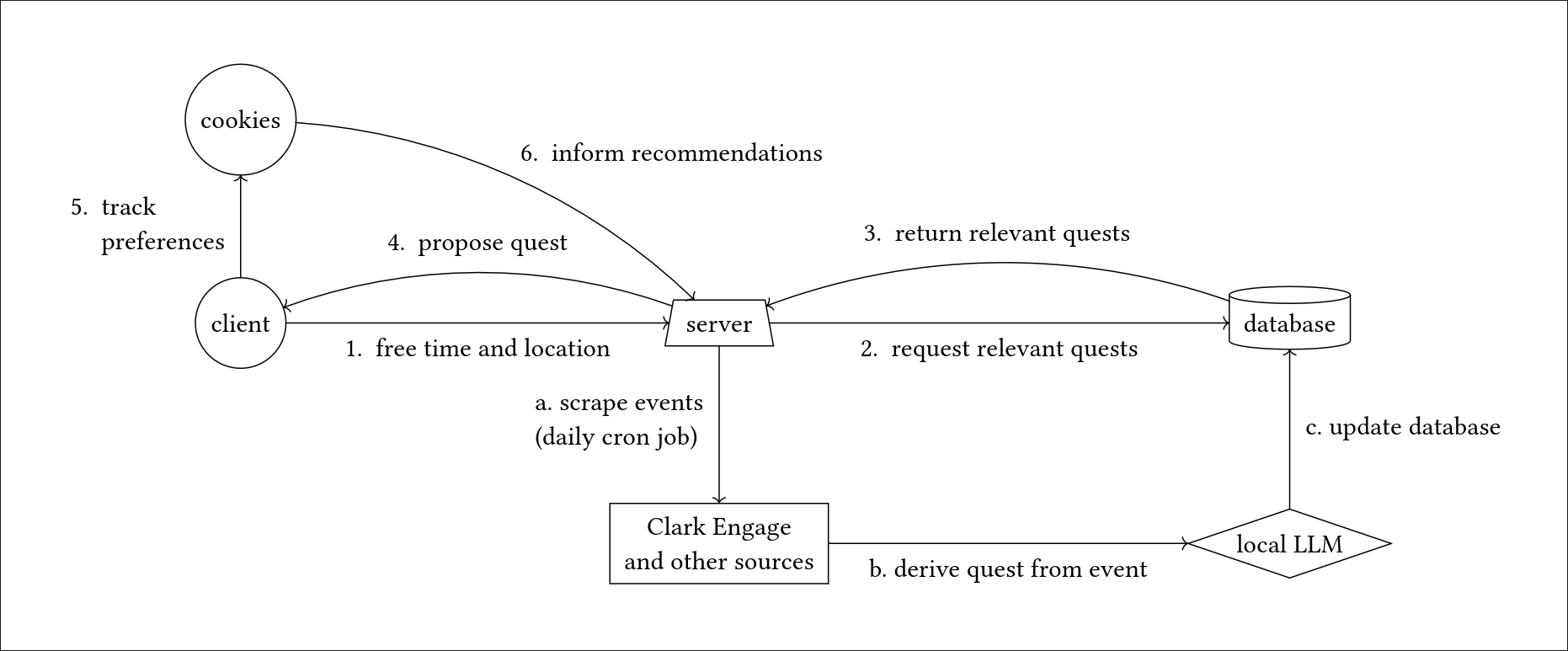
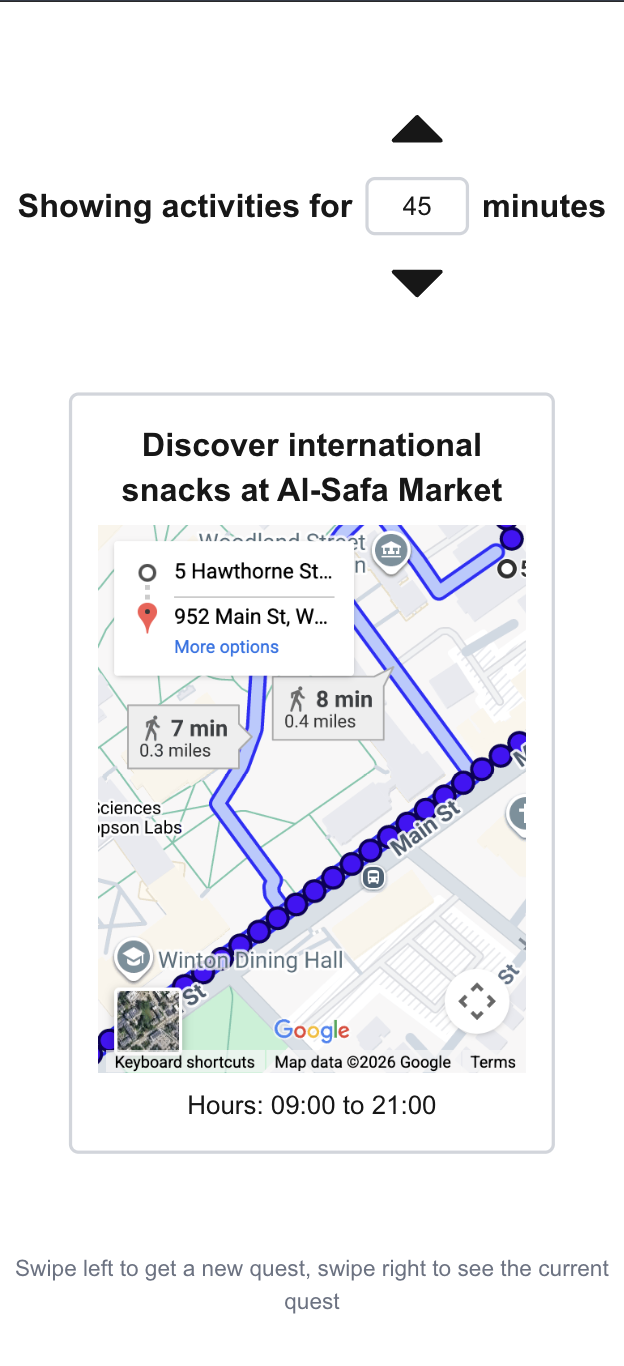
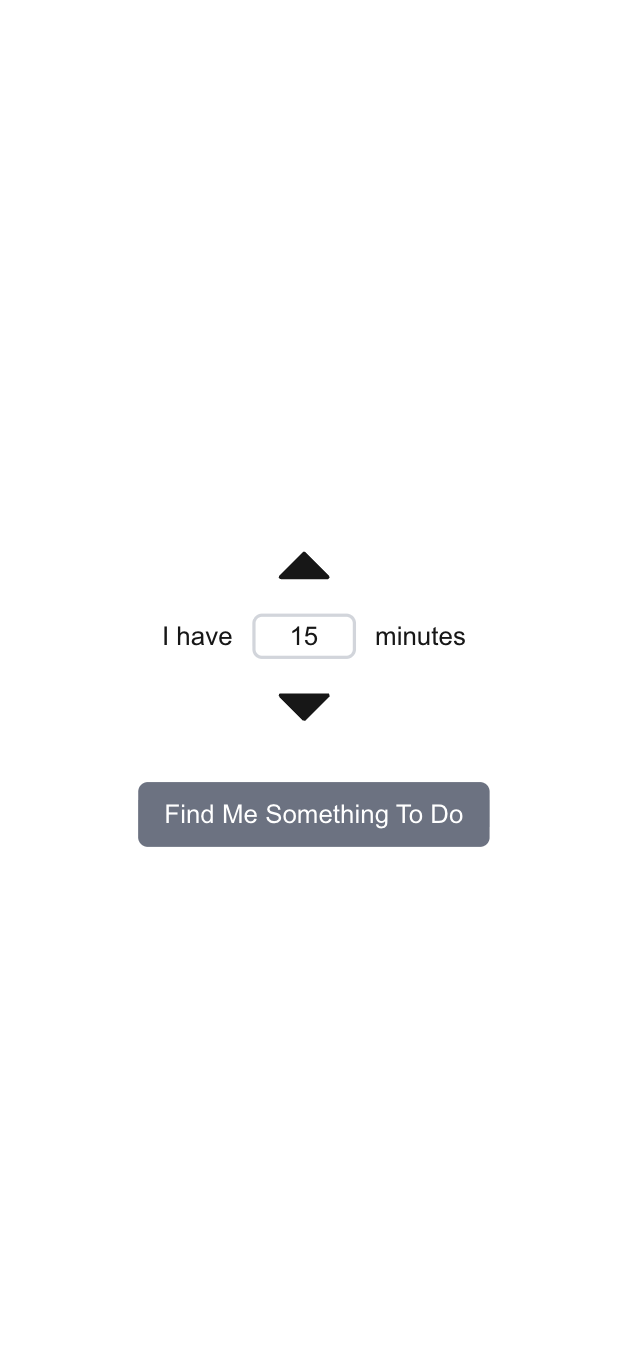
Clark Quests provides a set of recommended events and activities that a user can complete immediately in a specified amount of time. Users can swipe left and right to navigate through their recommendations. Events and activities are scraped from Clark Engage, the Worcester City Website, and permanent attractions and businesses in the Main South neighborhood.
We use local LLMs to process activities into meaningful "quests" and use a recommendation algorithm to tailor our user's feeds.
To keep the system as non-intrusive and frictionless as possible we designed minimally and streamlined. This is to get users off our app and out doing events and activities as quickly as possible.
How we built it
We used:
- FastAPI for backend and to run a cron job
- nextJS for he front end
- LM Studio for running LLM models locally (qwen3 for quest processing, nomic-bert for embeddings)
- SQLite as a database
- BeautifulSoup4 for web scraping
- FeedParser
- uvicorn
- docker
Challenges we ran into
Web Scraping:
- different RSS Feeds have different formats, so the parsing was largely unique for each site.
- inconsistency of data quality from scraped sites
- availability of data on scraped sites
Database consistency and collaboration across many versions
LLM costs: we want the tool to be usable in real life, so we want to keep costs down. Embedding models and LLM calls for data processing are intensive. This was an issue at first, but we solved it by setting up and using LM Studio to run models locally
Accomplishments that we're proud of
- local LLMs
- minimalistic frontend
- accurate and thorough web scraping
- correct, efficient, and beautiful database querying
- custom recommendation tool that performs well on sparse data using concepts from DS225
What we learned
We learned about:
- local LLMs for processing and embedding
- web scraping
- database efficiency
- balancing different types of data in recommendations
What's next for Clark Quests
Next we want to generalize the system to pull data in from more sources for other locations. We want to support users posting events and activities to further support community engagement without relying too heavily on school clubs and city-sponsored activities.
Built With
- beautiful-soup
- fastapi
- javascript
- lm-studio
- next.js
- nomic-bert
- python
- qwen
- railway
- sqlite
- tailwind
- typescript
- uvicorn
- vercel

Log in or sign up for Devpost to join the conversation.