-
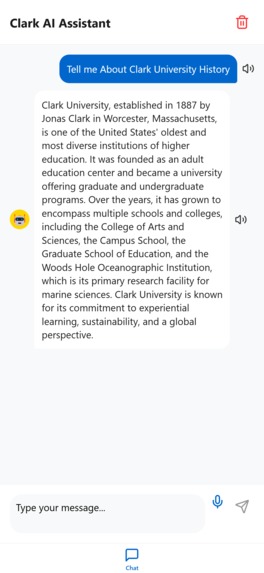
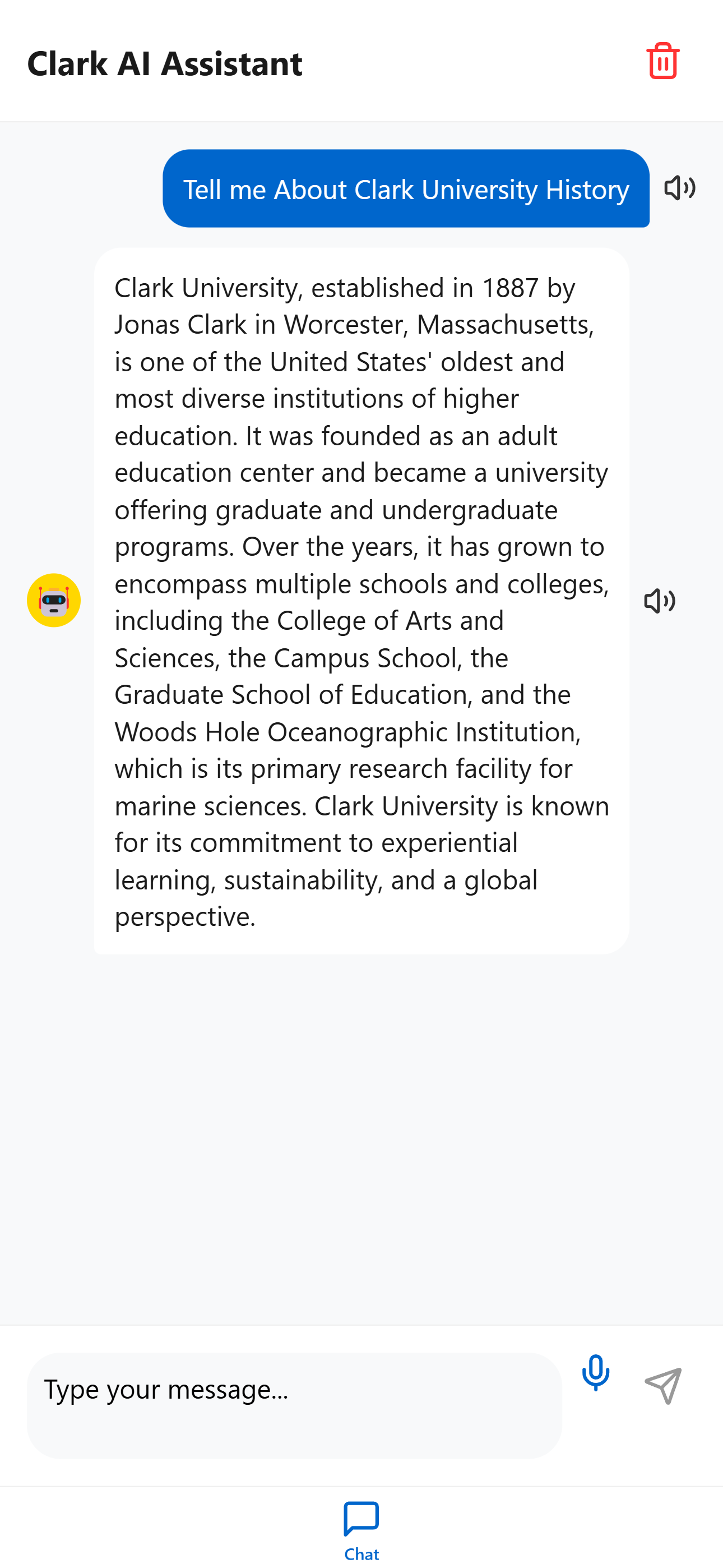
How our Assistance reply to Clark History
-
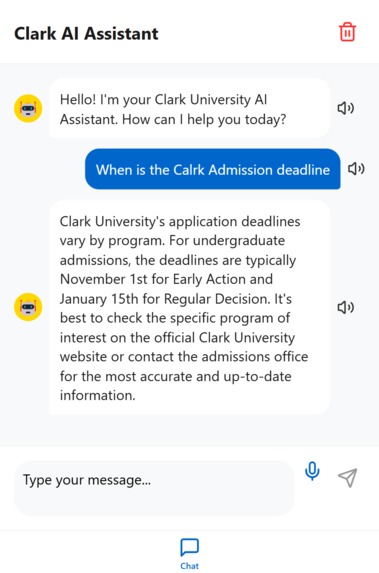
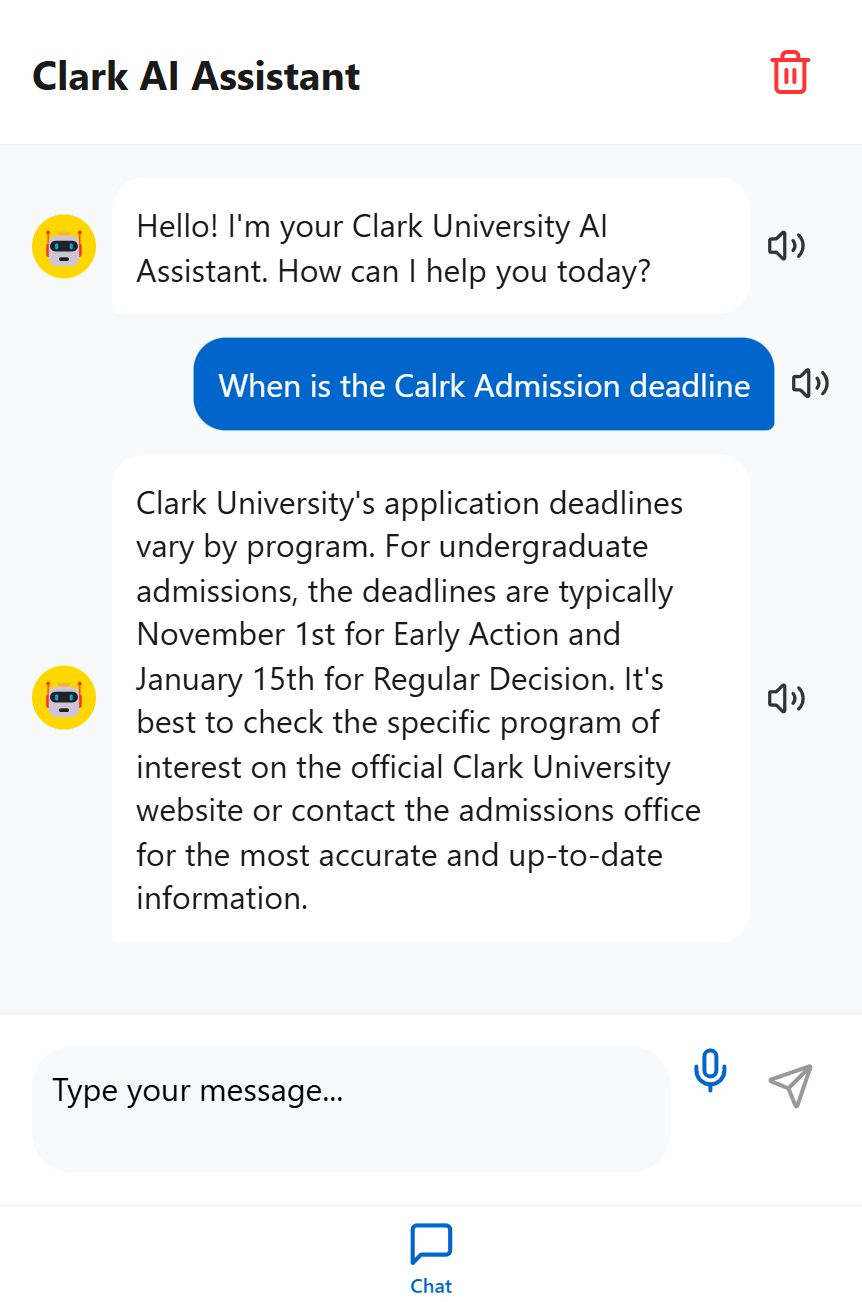
How our Assistance reply to deadline for admissions
Clark Compas Documentation
Inspiration
Clark Compas was inspired by the need to create an intelligent, user-friendly AI assistant that can provide fast and accurate responses to queries related to Clark University. The goal was to leverage modern AI models and web scraping technologies to offer personalized, relevant information to users based on Clark University’s public data.
What it does
Clark Compas is an AI-powered assistant that interacts with users and answers questions based on a vast corpus of university-related information. It uses:
- Web scraping: To gather data from Clark University’s website.
- FAISS Index: For efficient search and retrieval of relevant documents.
- Ollama: To generate AI-powered responses by using embeddings and natural language models.
Users can submit questions through an API endpoint, and the assistant will retrieve relevant data from the website and respond in a concise, accurate, and well-structured manner.
Key Features:
- Fast and accurate query responses based on Clark University’s information.
- Dynamic data retrieval using FAISS index for efficient search.
- AI-powered responses powered by Ollama’s chat and embeddings models.
How we built it
We built Clark Compas by combining a variety of modern tools and technologies, including:
- FastAPI: Used for creating the API backend to handle user requests and manage endpoints.
- FAISS (Facebook AI Similarity Search): A library for efficient similarity search and vector-based retrieval, which stores precomputed embeddings of Clark University data.
- Ollama: An AI model that handles the generation of embeddings and contextual responses based on the retrieved documents.
- Python: For implementing the logic, including web scraping and processing the AI model outputs.
The process involved:
- Scraping Clark University’s website for content that would be helpful for users.
- Generating embeddings for the scraped content using Ollama’s embedding model.
- Storing the embeddings in a FAISS index for efficient and fast retrieval of relevant documents.
- Handling user queries: Using FastAPI, the system processes user input, retrieves relevant documents from the FAISS index, and passes them to Ollama to generate a response.
Challenges we ran into
Throughout the development of Clark Compas, we faced a few challenges:
- Data Scraping: Scraping data from a live website can be unpredictable due to changes in the website’s structure. Ensuring that the data extraction logic remains consistent and adaptable to changes was a challenge.
- Embedding Accuracy: Ensuring that the embeddings generated by Ollama were sufficiently relevant for the types of queries users would submit took iterative testing and fine-tuning.
- FAISS Index Management: Building and managing a FAISS index, especially for larger datasets, required ensuring that the index was efficiently updated and queries were processed within an acceptable time frame.
Accomplishments that we're proud of
- Seamless AI-powered responses: We successfully implemented an AI system that can provide relevant answers in real-time based on dynamic data from Clark University.
- Efficient Document Retrieval: Our use of FAISS to store and quickly search embeddings has significantly improved the speed and accuracy of information retrieval.
- User-friendly API: The FastAPI-based system is simple, clean, and well-documented, allowing for easy integration and use by other applications.
What we learned
- Importance of data preprocessing: The effectiveness of our AI assistant was highly dependent on how well the data was preprocessed, particularly with embedding generation and indexing.
- Managing large-scale data: Working with FAISS has taught us a lot about efficient search and vector management, especially when handling large sets of text data.
- The power of AI in customer service: We learned how AI can be used to automate and enhance the process of providing fast and accurate information to users.
What's next for Clark Compas
While Clark Compas is already functional, there are several enhancements and future directions we are excited about:
- Expand Data Sources: Currently, the assistant pulls data only from Clark University’s website. We aim to expand this to include other data sources such as academic papers, event calendars, and more.
- Refine AI Model: We plan to enhance the AI’s natural language understanding and response generation to be even more precise and context-aware.
- Improve User Interaction: We are exploring the possibility of adding conversational capabilities, allowing users to ask follow-up questions and have a more interactive experience.
- Deploy on a Larger Scale: We plan to scale the application to handle a higher volume of users, ensuring it remains responsive and performant.
Built With
- ai
- fastapi
- ollama
- python
- react-native
Log in or sign up for Devpost to join the conversation.