
Inspiration
Growing up with tics, there were moments when I felt like my true identity and message weren't being broadcasted exactly as I intended. Clarity was born from that desire for choice; it is an accessibility layer that gives individuals with speech disfluencies and language barriers the power to decide how they wish to represent themselves in the digital world. We aren't changing the person; we are providing the tools to ensure their message is heard exactly how they intend to deliver it.
What it does
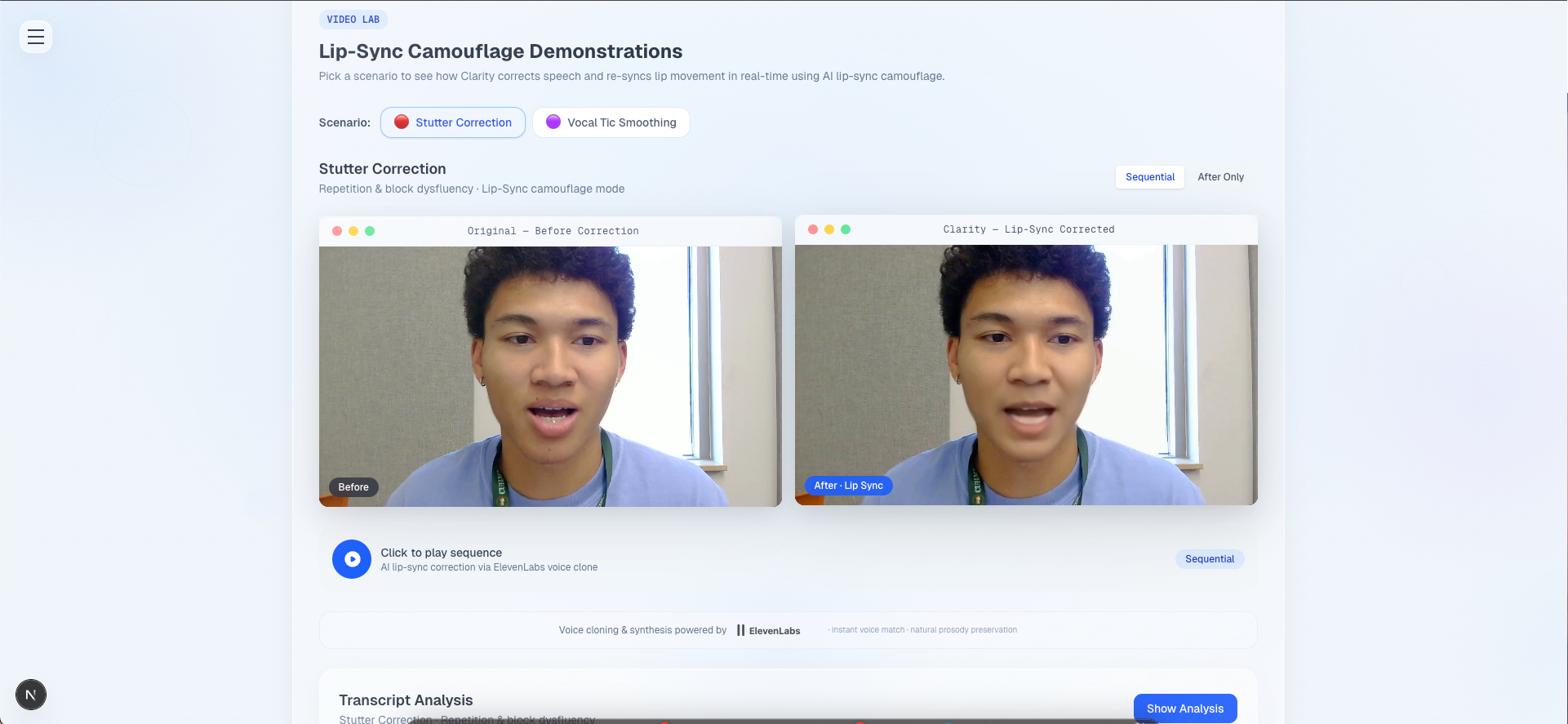
Clarity is a "Vocal OS" accessibility layer that empowers speakers by supporting speech disfluencies and bridging linguistic gaps within a seamless two-second neural mastering buffer. Our pipeline acts as an intelligent middleware for digital communication through three core stages:
Disfluency-Aware Transcription: We leverage ElevenLabs Scribe v2 for its industry-leading accuracy in transcribing speech disfluencies, ensuring that every nuance of the raw audio is captured as a "literal map" for processing.
Neural Healing: Using Gemini 2.5 Flash, the system performs "surgical" text restoration, removing stutters and vocal tics while automatically bridging linguistic gaps when a user "code-switches" or forgets a word in their target language.
Identity-Preserving Synthesis: The final message is re-broadcast using ElevenLabs Flash v2.5, which utilizes a high-fidelity voice clone to maintain the user's authentic emotional resonance and vocal fingerprint.
Challenges we ran into
Orchestrating a multimodal pipeline requires synchronizing audio transcription, linguistic healing, voice synthesis, and visual lip-syncing. This reinforced to us that parallelism and efficient asynchronous handling are critical for maintaining any low-latency experience.
Accomplishments that we're proud of
Successfully built a stable, one-shot pipeline that manages a ~2-second buffer to perform high-fidelity neural dubbing. Developed a "Clarity Filter" visualizer and "Correction Log" that live-demos the real-time transformation from raw disfluency to fluent speech. Implemented a linguistic "bridge" that handles on-the-fly code-switching, supporting users who navigate multiple languages in professional settings.
What we learned
We learned the importance of giving Gemini 2.5 Flash agency to distinguish between user intent and disfluencies; its ability to surgically "heal" transcripts while preserving the user's original tone was incredibly accurate. The high-fidelity cloning from ElevenLabs blew our minds, it captured vocal fingerprints and emotional resonance with a level of precision we didn't think was possible with such small data samples. We discovered that ElevenLabs Scribe v2 handled disfluencies and inexact speech significantly better than any previous STT model we had ever used, providing the perfect literal map foundation for our logic.
What's next for Clarity
Transitioning from a one-shot pipeline to a kernel-level audio driver to allow for universal, real-time integration into Zoom, Teams, and Slack. Refining the Camouflage Level settings to give users even more granular control over their vocal and visual portrayal during live calls.





Log in or sign up for Devpost to join the conversation.