-
-
clarity-home
-
clarity-home-1
-
clarity-record-1
-
clarity-record-2
-
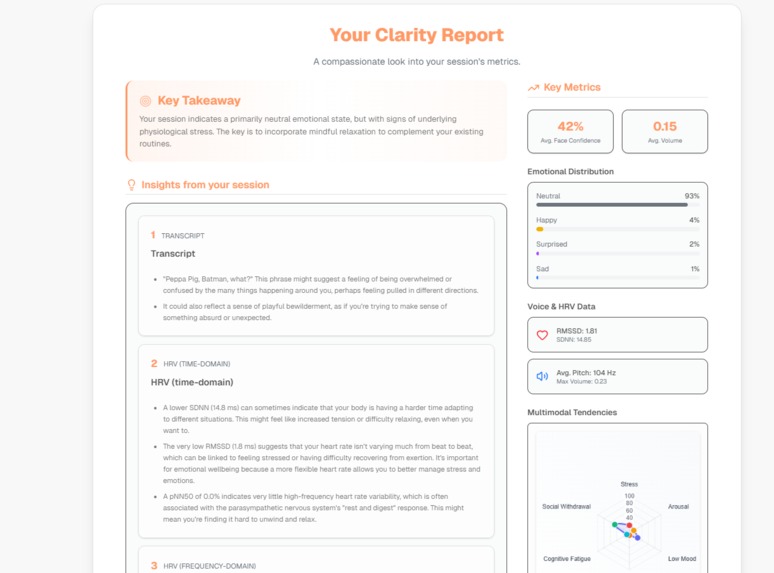
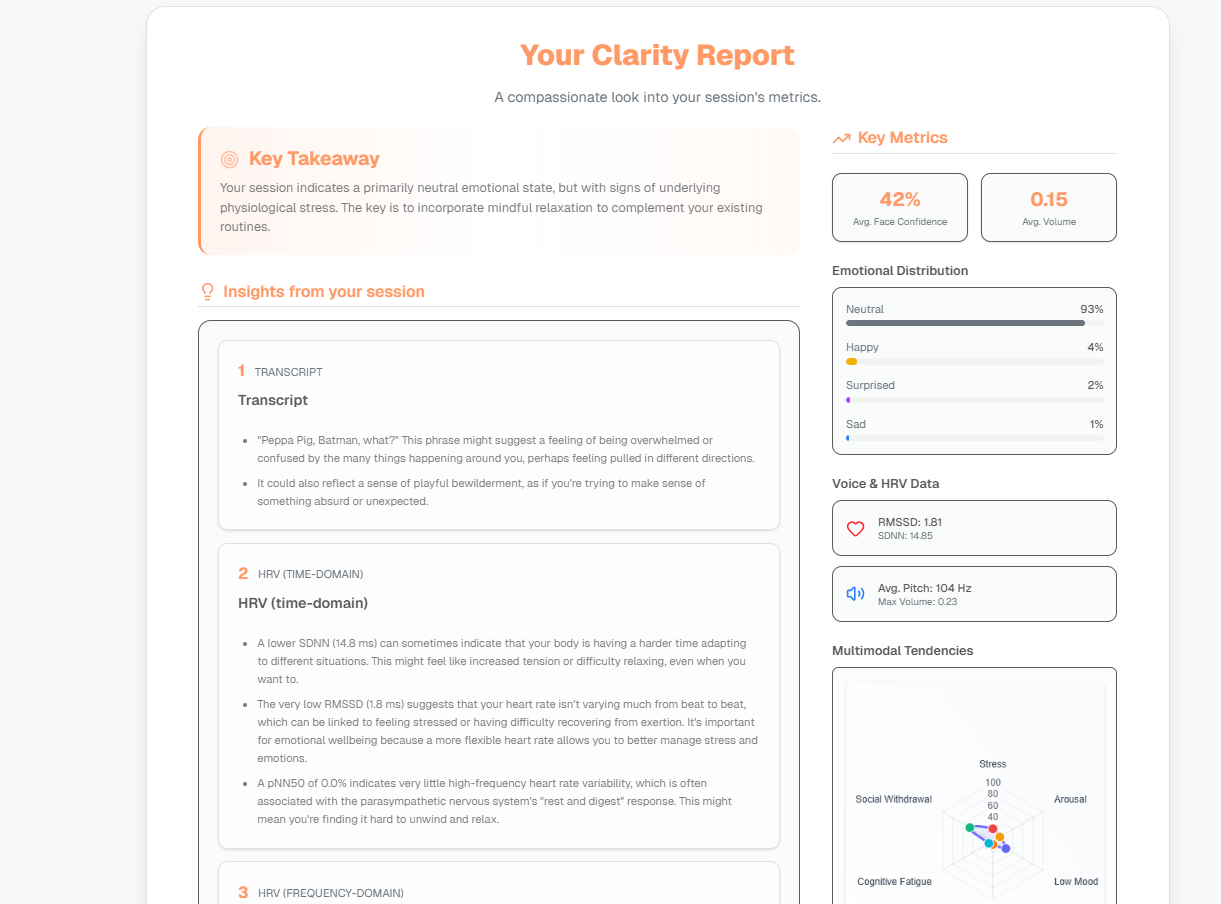
clarity-report-1
-
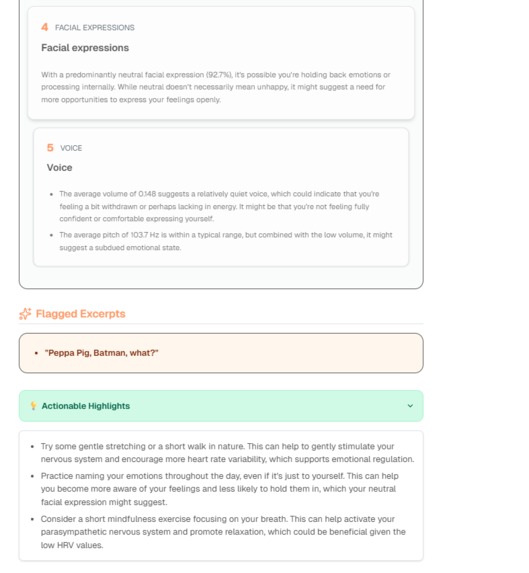
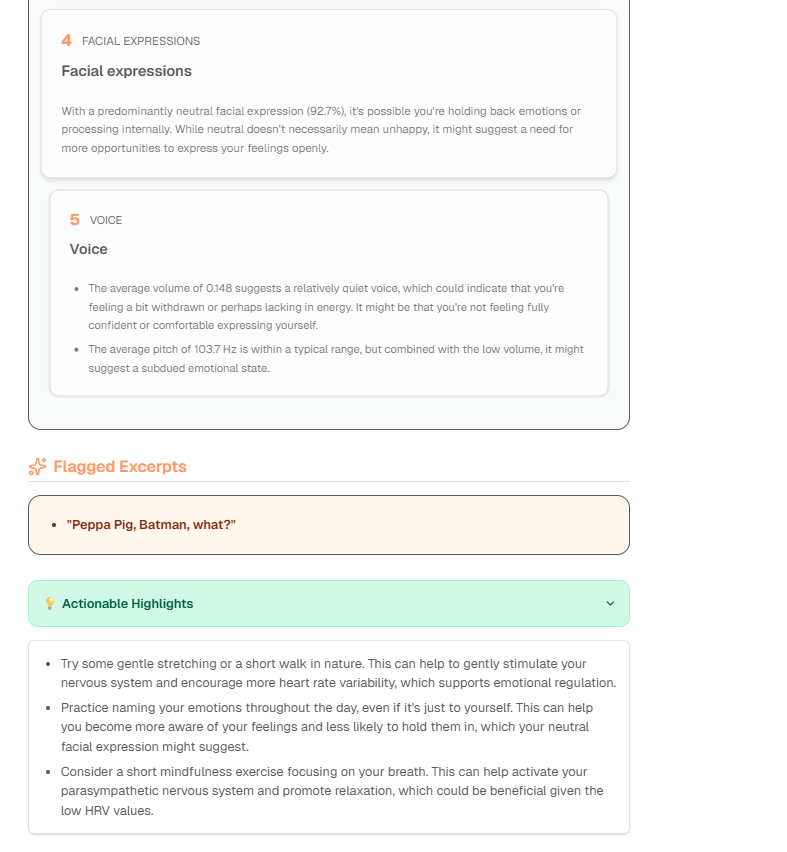
clarity-report-2
Inspiration
It started as a simple idea: make a private, low-friction first-aid for mental wellbeing that people can try at home; a non-clinical check-in that uses video, audio, and a wearable to surface signals and encourage help-seeking.
What it does
- Records a short video + audio session and optionally reads heart rate from a smart band.
- Extracts multimodal features (facial expressions, eye-openness/blinks, voice timbre & pitch, HR/HRV).
- Aligns those signals into a single timeline and computes robust metrics.
- Sends the summarized metrics + transcript to an LLM for an empathetic and structured report.
- Persists human-readable report + parsed machine data for audit and charting.
How we built it
Frontend
- face detection & expressions: face-api.js (TinyFaceDetector + faceLandmarks + expressions)Audio ----- features: Meyda for MFCC, RMS, spectral centroid, ZCR + a local autocorrelation pitch detector (guarded by RMS silence gate).
- Smart band: BLE characteristic listener for BPM.
- Streaming & alignment: alignStreams() builds 500ms timeline slots, dedupes timestamps and merges last-known values per slot.
- Client collects raw samples and sends a compact timeline JSON to backend (no raw media saved).
Backend
- Data cleaning & aggregation: VoiceCleaner accumulates short windows, EMA smoothing, median smoothing & robust MFCC stats, rejects noisy windows.
- HRV (time): compute RR from BPM → SDNN, RMSSD, pNN50 with filtering and outlier removal.
- HRV (freq): resample RR to uniform grid, detrend, FFT, integrate LF/HF bands (with duration/validity checks).
- Deterministic spider scoring: computeSpiderScores() — normalized heuristics produce axis scores (Stress, LowMood, SocialWithdrawal, Irritability, CognitiveFatigue, Arousal).
- LLM integration: send structured prompt + metrics to Gemini -> parse SESSION_REPORT: line.
Challenges we ran into
- Noisy audio (singing/background) produced MFCC/ZCR spikes → required aggregation + validity checks.
- Irregular HR sample timing and duplicate timestamps from BLE → needed dedupe and filtering before HRV.
- Short sessions make spectral HRV unreliable → enforced minimum duration & marked frequency results invalid when insufficient.
- LLM drift/hallucination for numeric outputs → implemented strict output format + server validation and fallback.
- Browser compatibility (SpeechRecognition, WebAudio, BLE) — graceful degradation required.
Accomplishments that we're proud of
- Fully integrated multimodal pipeline (face, voice, HR) working end-to-end in-browser.
- Robust server-side cleaning, HRV (time + freq) and aggregation that tolerates noisy real-world input.
- Safety-minded LLM usage: structured prompt, flagged-excerpts primary for risk, server validation and no raw media retention.
- Actionable UI: human-readable empathetic report + machine-friendly spider data for visualization.
- Auditability: raw AI reply + parsed JSON stored for reproducibility and judging.
What we learned
- More data/features ≠ more accuracy unless you clean and validate them. Good preprocessing is everything.
- Short recordings limit spectral HRV and make voice/MFCC stats fragile — require minimum durations or clear UX guidance.
- LLMs are great for empathetic language but poor at guaranteed numeric consistency; always validate and fall back to deterministic logic.
What's next for Clarity
- Tune thresholds and weighting with labeled pilot data; add small A/B tests to validate UX.
- Add clinician review interface & consented dataset option for supervised improvements.
- Improve real-time feedback (on-device indicators for “good audio / good face / good HR”) so users get better samples.
- Mobile browser & native app packaging for BLE and microphone reliability.
- More interpretability; show both raw and confidence-weighted scores, and provide exportable summaries for clinicians.
About this app
Clarity is a mental-wellbeing first-aid, not a diagnosis. It’s designed to help people do a quick, private check-in when they’re unsure about reaching out to a professional. The report gives supportive observations and suggested next steps, but it does not replace clinical assessment or treatment.
Important Notes
- Not medical advice. The report is informational only. If you’re concerned about your safety or wellbeing, please contact a qualified professional. If someone is in immediate danger, call your local emergency number or a crisis line
- Privacy-first: video/audio processing happens in your browser; only compact summary metrics and a transcript are sent to the server. We do not retain raw media in the demo. Data stored for the demo is used only to generate the report and for auditing. And the report data is stored at local storage.
- Demo performance: The public demo backend is hosted on a free Render plan. That may make report generation slower or cause occasional temporary delays.
Quick Tips
- Record in a quiet room with the microphone near your mouth.
- Keep the camera steady and well-lit so facial features are clear.
- Avoid singing or music during the sample if you want a clear speech-based analysis.
- Use a longer sample (≥60s) for more reliable HRV frequency results.


Log in or sign up for Devpost to join the conversation.