-
-
Front Page
-

How It Works #1
-
How It Works #2
-
Protection Policies #1
-
Protection Policies #2
-
Vault (Saved Documents)
-
Analyzing Documents
-
Security Policies
-
Analysis Results #1
-
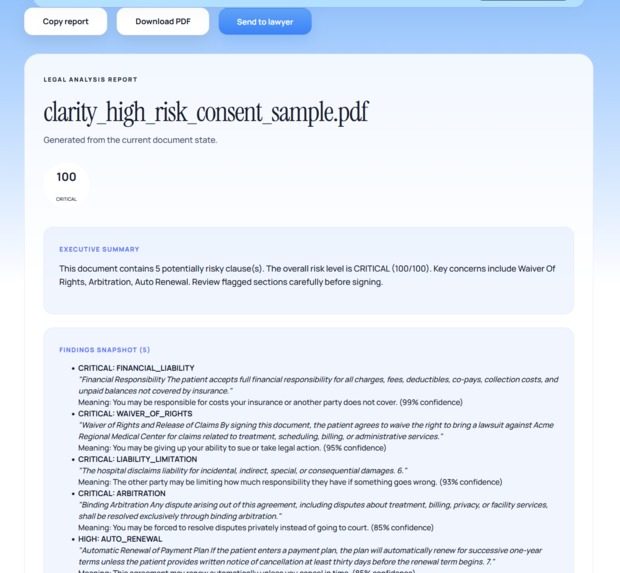
Analysis Results #2
-

Analysis Results Continued
-

Send Results



Inspiration
Every person on our team has signed something they didn't read. A gym waiver. A phone contract. A university consent form. We signed the BearHacks waiver today without reading it.
That's not carelessness - that's by design. Legal documents are deliberately written to be incomprehensible. The institutions that draft them have built their entire legal protection around one statistical certainty: you will not read what you sign. Hospitals, landlords, employers, and tech companies all depend on it.
That is the norm. We built Clarity to break it.
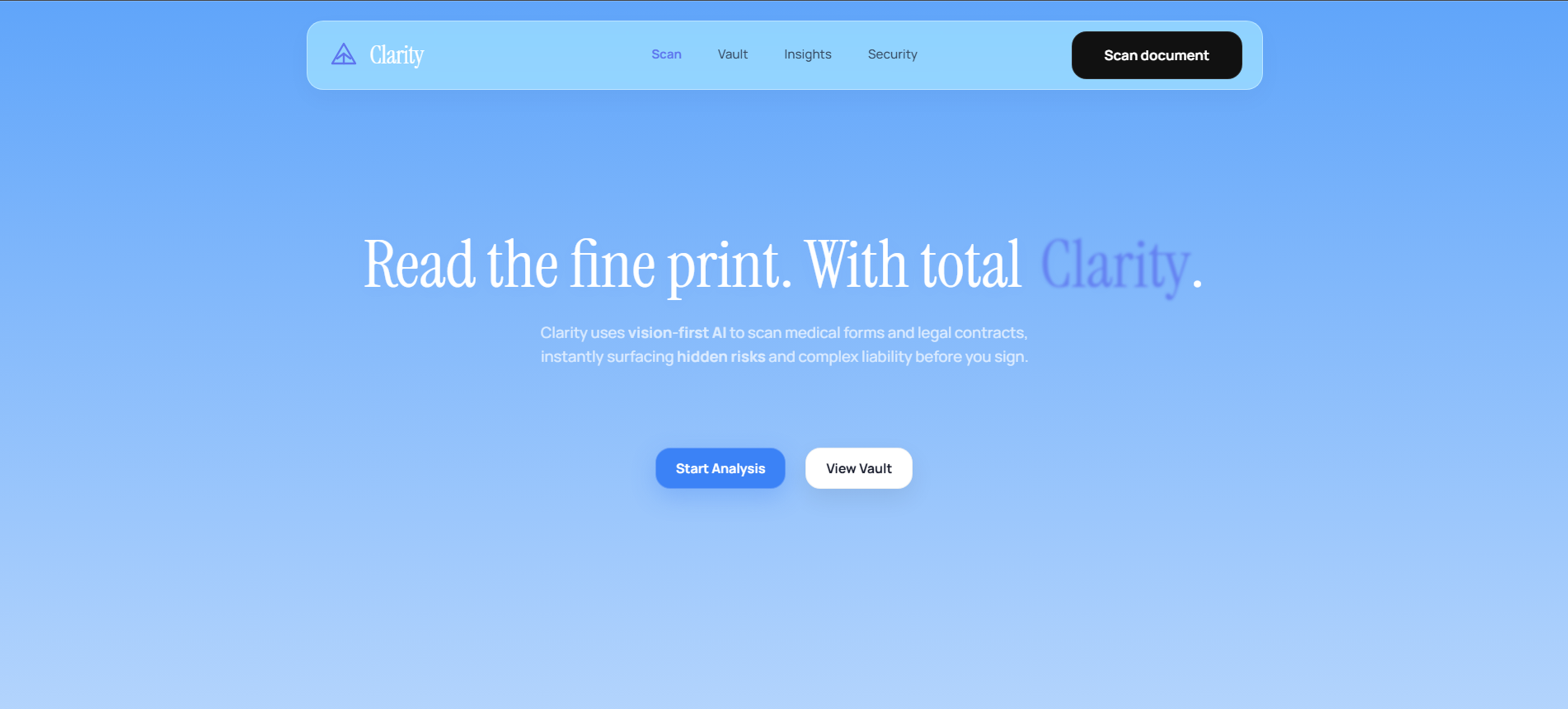
What It Does
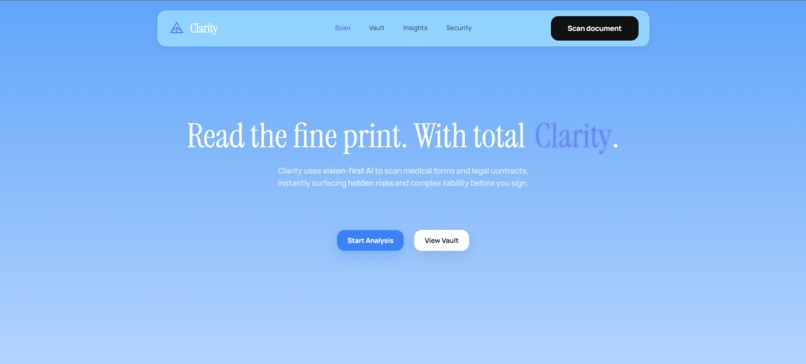
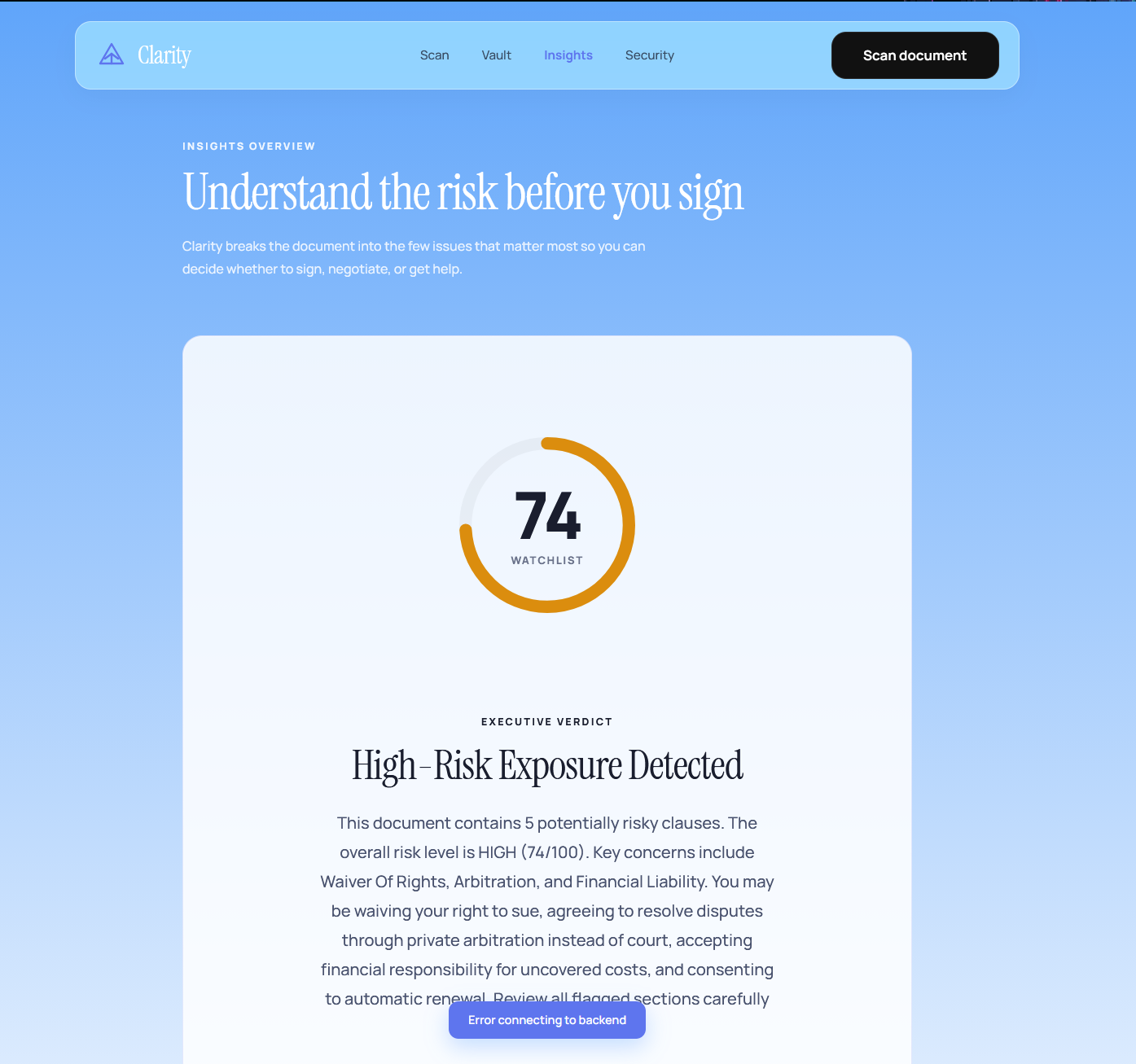
Clarity is an AI-powered document intelligence platform that tells you what you're agreeing to before you sign.
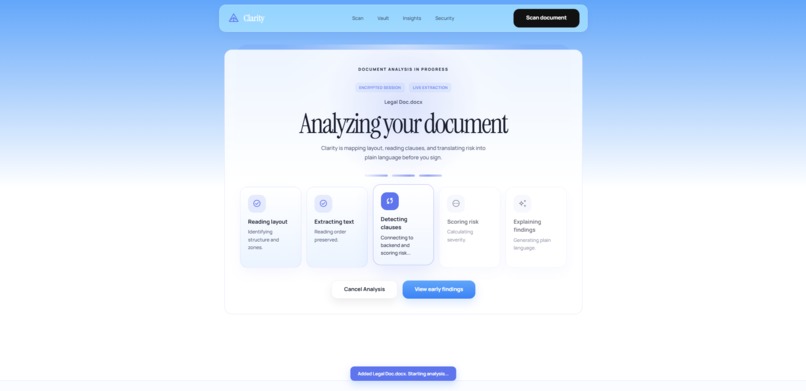
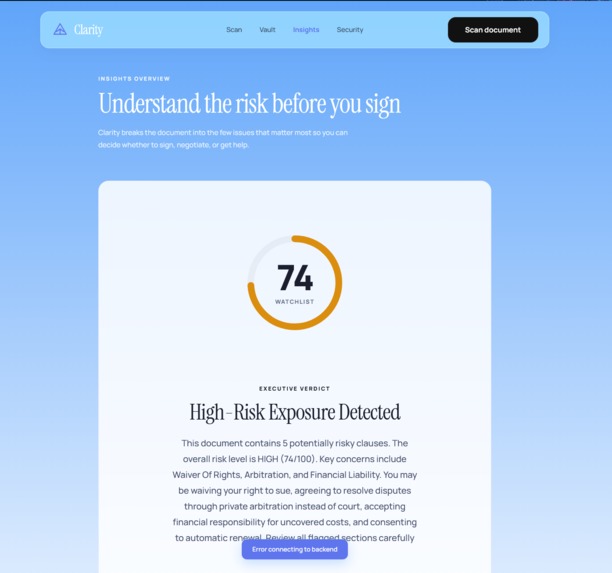
Photograph or upload any legal or medical document. In under five seconds, Clarity returns a plain-language risk score, flags your most dangerous clauses, and explains exactly what you are waiving in language anyone can understand.
Point your camera at a hospital consent form before surgery. Photograph your lease before you hand over the first and last month's rent. Upload your employment contract before you accept the offer. Clarity tells you what a lawyer would, instantly, for free.
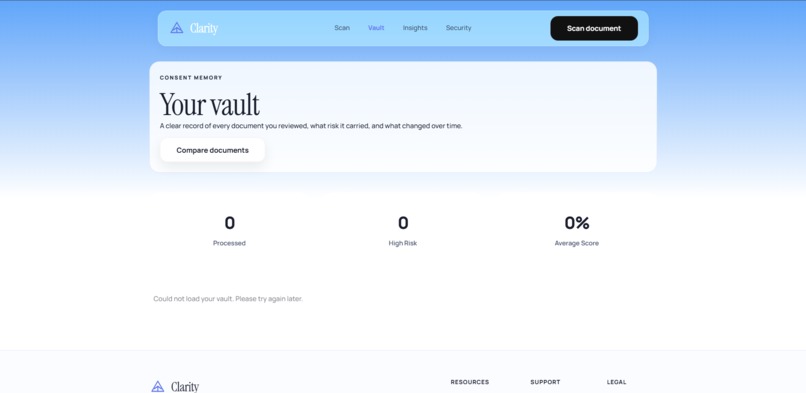
Your full scan history lives in your Consent Vault, retrievable from any device. Every document you've ever analyzed, every risk score, every flagged clause is stored and searchable.
How We Built It
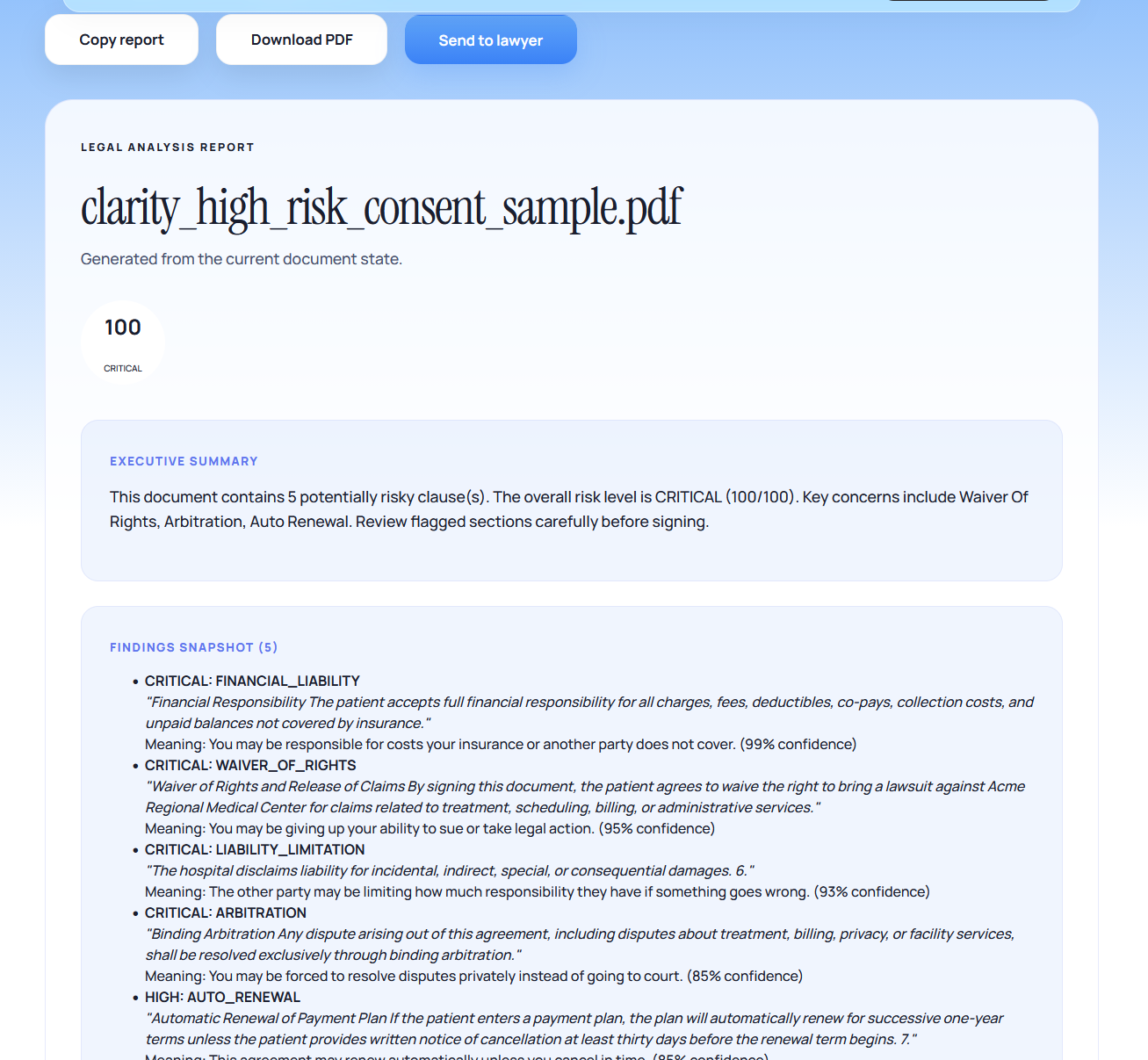
Custom Fine-Tuned Model: The Core We fine-tuned DistilBERT on CUAD, the Contract Understanding Atticus Dataset, 510 real commercial legal contracts with 13,000 expert-labeled clause annotations across 41 clause types. Our model performs multi-label classification: every clause segment gets tagged with one or more risk categories, including arbitration hooks, liability caps, rights waivers, indemnification clauses, and auto-renewals. Inference runs in under 800ms per page. Training completed in under two hours on a T4 GPU. This is not a general LLM wrapper; it is a specialized legal classifier that outperforms general models on contract understanding tasks.
Google Cloud Vision API: Reading the Document, Not Just the Text Standard OCR loses everything except the words. Google Cloud Vision reads the document's geometry, mapping how clauses relate spatially, identifying headers, sub-clauses, signature fields, and checkboxes. This spatial understanding is what allows our model to determine which clause governs which, and which sections carry the most legal weight. It also means Clarity works on physical documents photographed on a phone, crumpled, angled, poorly lit, not just clean PDF uploads. The primary use case is someone holding a paper waiver with a pen in their other hand.
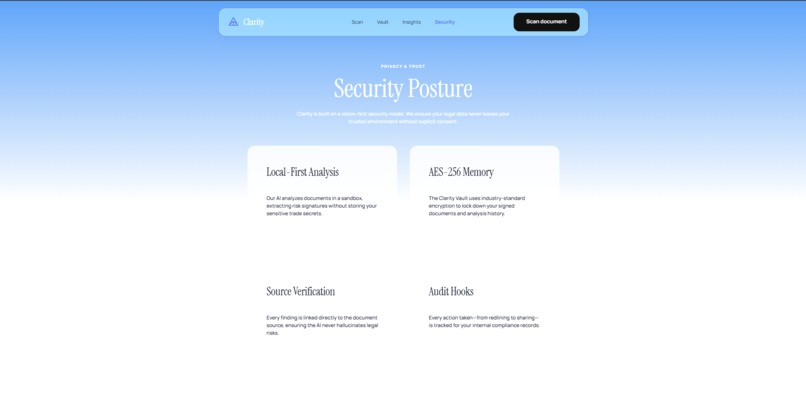
Gemma 4: Plain Language at the Edge Flagged clauses are passed to Gemma 4 via the Google Gemini API. Gemma rewrites every high-risk clause in plain English and generates the overall document risk summary. Using Gemma 4 means the reasoning layer is open-weight, Apache 2.0 licensed, and privacy-preserving — sensitive document content is never unnecessarily exposed to external APIs.
DCP: Parallelized at Scale Legal documents are long. A standard employment contract runs 20–40 pages. Processing them sequentially would take 40+ seconds, too slow to be useful. We integrated Distributive Compute Protocol to dispatch each page as a parallel job across DCP's global compute network. A 40-page contract processes in the same time as a single page. We benchmarked 40 pages in under 6 seconds versus 44 seconds sequentially. DCP is what makes Clarity feel instant regardless of document length.
Backboard: The Consent Vault Every scan is stored in Backboard with its timestamp, risk score, flagged clauses, and plain-language summary. Your consent history is persistent and retrievable from any device. The Vault UI lets you filter by risk level, document type, and date — and compare risk scores across documents from the same institution over time. Backboard is decoupled from the analysis engine: only structured analysis output is stored, never raw document content.
Frontend: UI/UX as a Product Decision Built in Next.js with Framer Motion animations. The centrepiece is the Risk Hue Ring, a score dial that animates from green to red on load, giving users a verdict before they read a single word. Typography uses Instrument Serif for legal clause text and Manrope for UI copy, a deliberate contrast that visually signals "this is the dangerous part, this is what it means." Every animation directs attention rather than decorates. Mobile-first throughout, because the primary user is standing in a doctor's office holding their phone.
Challenges We Ran Into
Getting Google Cloud Vision and our custom DistilBERT model to agree on clause boundaries was the hardest technical problem. Vision segments by visual layout, paragraphs, columns, text blocks. DistilBERT expects semantically coherent clause units. These don't always align. We built a reconciliation layer that merges Vision's spatial segments into logical clause units before classification, handling edge cases like clauses that span columns or continue after a page break.
DCP integration required rethinking our pipeline architecture entirely. We had to make each page's inference job fully self-contained, carrying its own context, so jobs could run independently across the compute network and be correctly reassembled in order.
Training the model in a hackathon window meant making fast decisions about which of CUAD's 41 clause types to prioritize. We focused on the nine categories most likely to harm an individual signer rather than the full commercial contract taxonomy.
Accomplishments That We're Proud Of
Training a specialized legal classifier in under two hours that genuinely outperforms prompting a general LLM on clause identification. Getting the full pipeline: Vision → DistilBERT → Gemma 4 → Backboard - running end to end in under five seconds on a single-page document. The Risk Hue Ring animation, which communicates a verdict faster than any text could. And building something that every single person who sees it immediately wants to use on a document they have in their pocket right now.
What We Learned
The hardest part of building AI products is not the model - it's the data pipeline between components that each speak a different language. Vision speaks in bounding boxes and confidence scores. DistilBERT speaks in token sequences. Gemma speaks in natural language. Backboard speaks in structured JSON. Building a system where these four components communicate cleanly under a five-second latency constraint taught us more about systems design than any coursework.
What's Next for Clarity
The immediate next step is expanding the clause taxonomy beyond the nine risk categories we prioritized for the hackathon to cover all 41 CUAD clause types. After that, jurisdiction-aware analysis - flagging clauses that are unenforceable or illegal in specific provinces and states. A browser extension that scans terms of service automatically before you click accept. And an enterprise tier for compliance teams and HR departments processing high volumes of employment contracts. The core insight that information asymmetry in legal documents is a solvable technical problem scales to every industry that uses contracts, which is every industry.
Built With
- backboard-api
- css
- cuad-dataset
- distilbert
- distributive-compute-protocol-(dcp)
- fastapi
- framer-motion
- gemini-api
- google-cloud-vision-api
- google-gemma-4
- hugging-face-transformers
- javascript
- next.js
- python
- supabase
- tailwind







Log in or sign up for Devpost to join the conversation.