-
-

Landing page
-
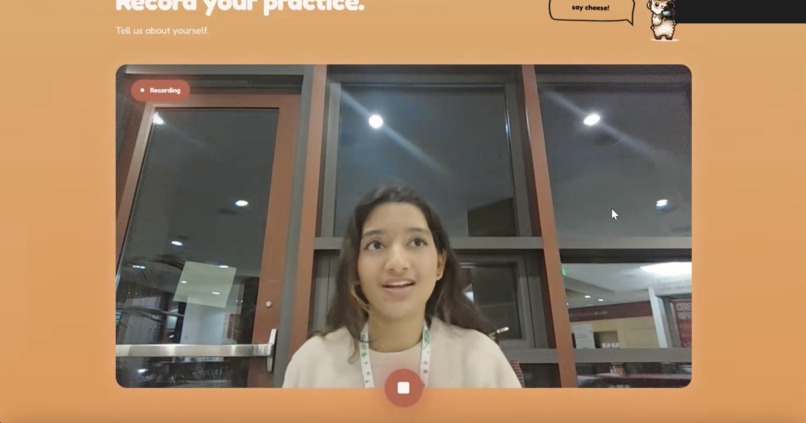
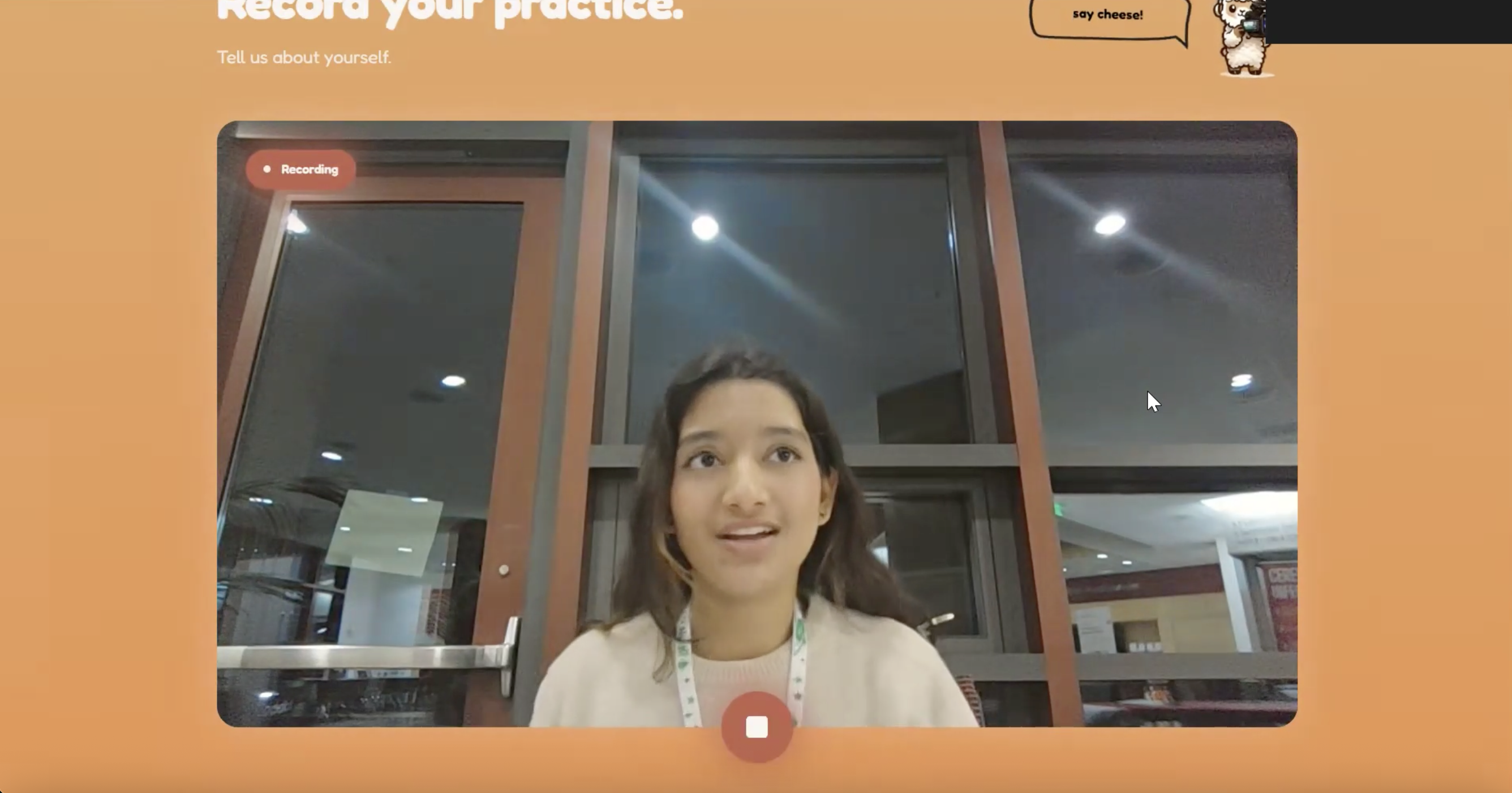
Live recording page
-
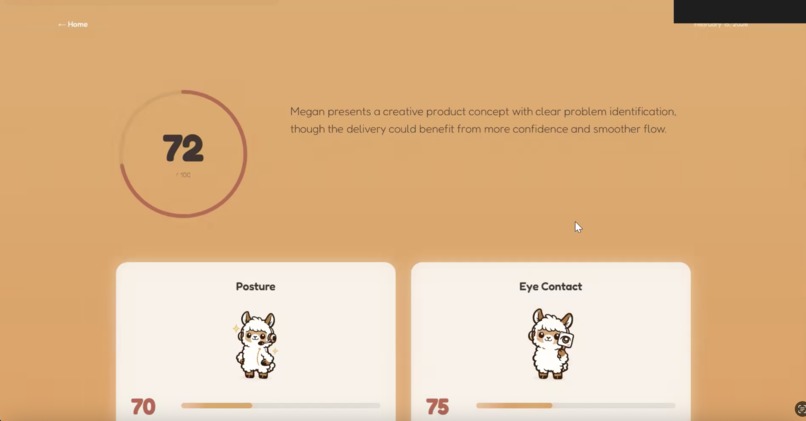
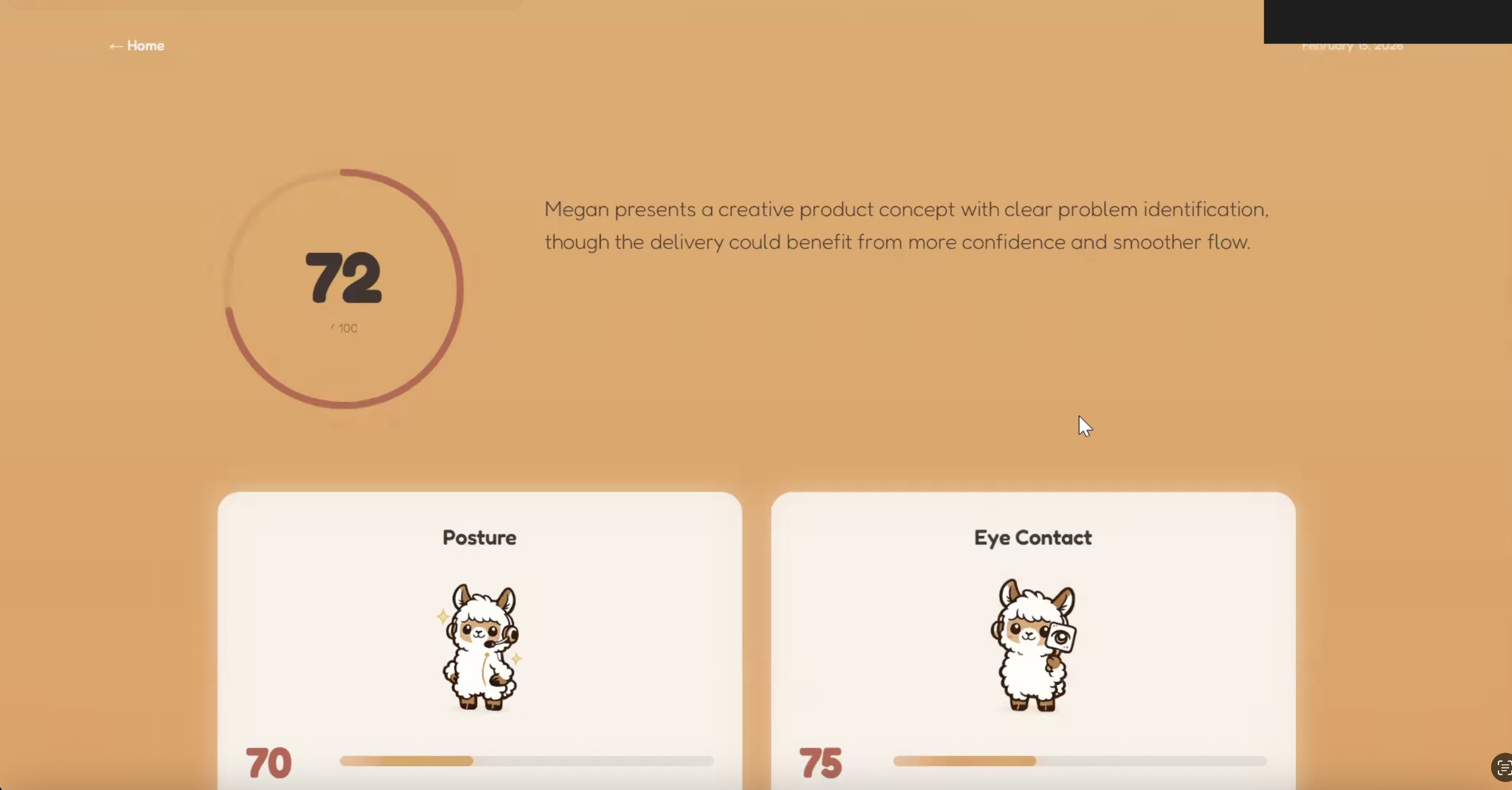
Results and analysis page
-
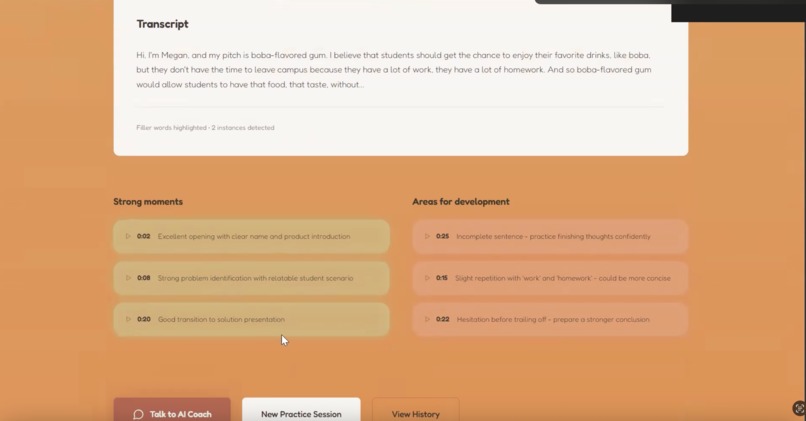
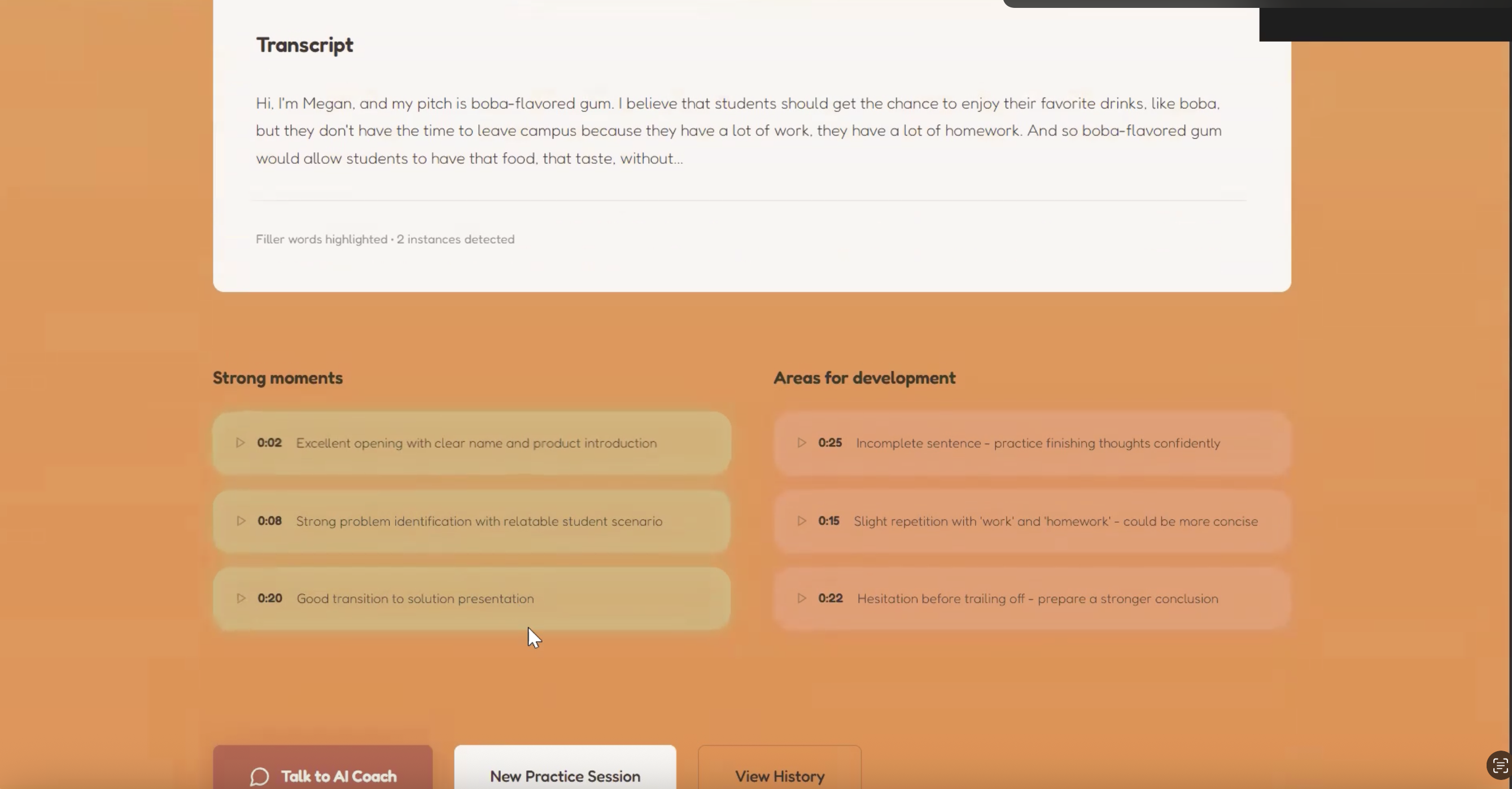
Results and analysis page
-
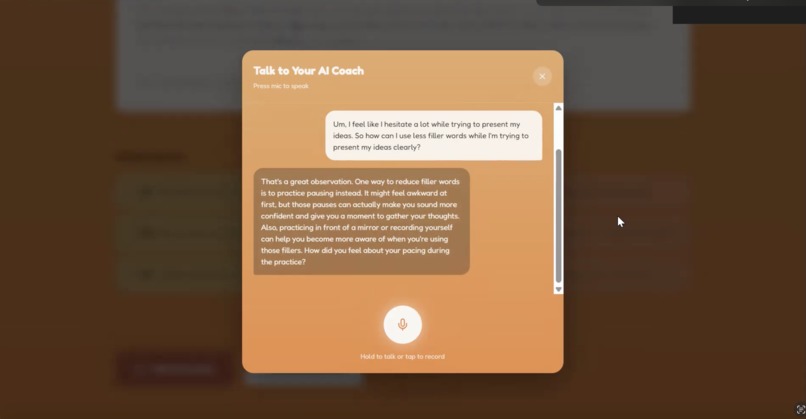
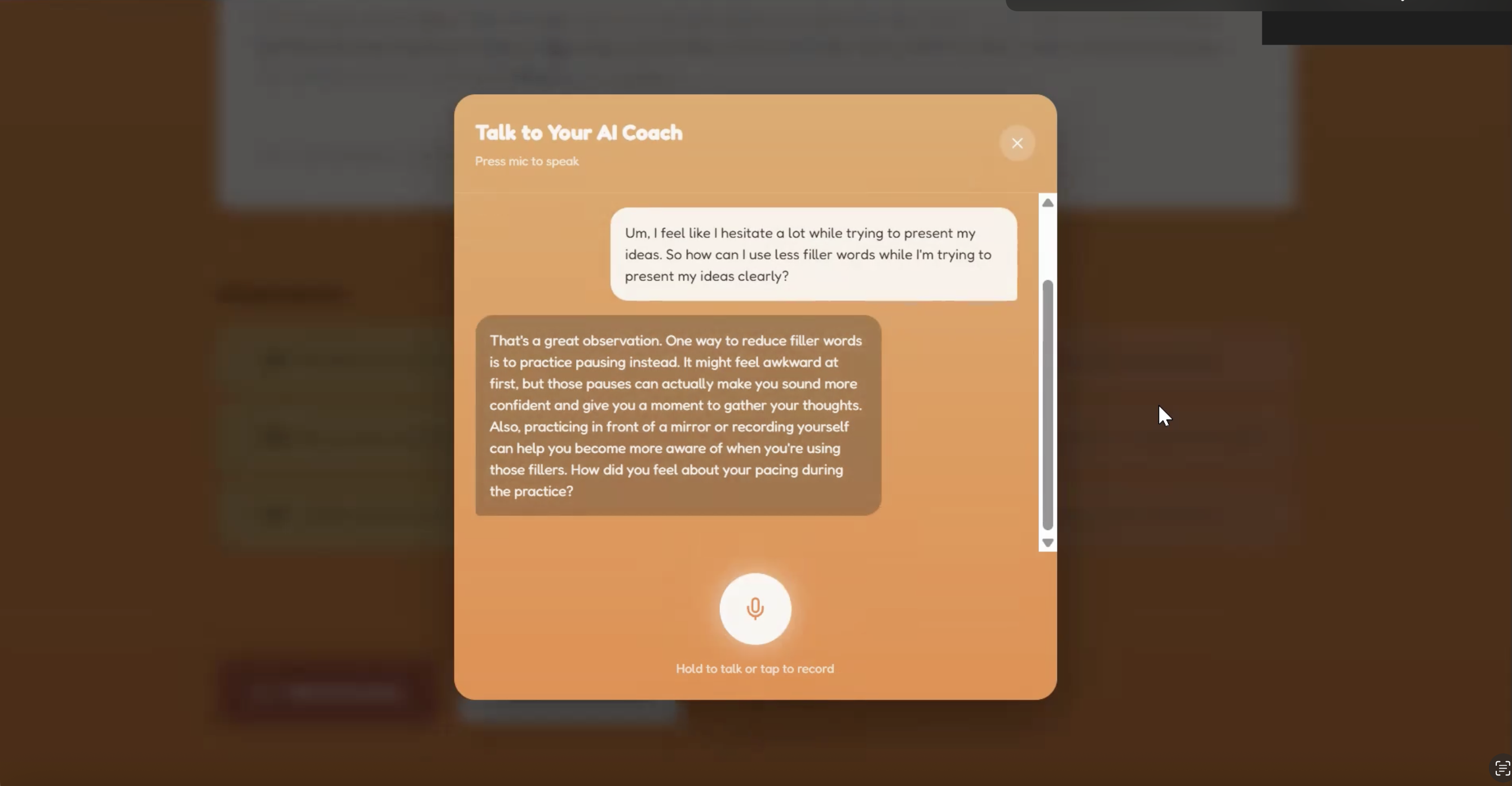
AI coach page

Inspiration
Roughly 1 in 5 U.S. residents grew up speaking a language other than English at home. ESL speakers often face invisible friction: interviewing for jobs, speaking up in class, or even navigating casual social interactions can feel intimidating when language confidence lags behind ability – especially in modern-day linguistically homogenous societies.
All four of our team members grew up in bilingual households. We know firsthand the hesitation before speaking, the anxiety after mispronouncing a word, and the pervading feeling of being evaluated rather than understood. We realized that while language apps teach vocabulary and grammar, very few platforms simulate real-world speaking scenarios with personalized feedback.
So we built Clarity Coach: an AI-powered speaking platform that helps users build confidence in their second-language communication skills. Through real-time video recording, personalized speech and body language feedback, visual and audio analytics, and gamified progress tracking, Clarity Coach helps individuals acclimate to unfamiliar linguistic environments in a safe, welcoming, yet productive learning platform.
What it does
Clarity Coach lets users record a 45 second video of themselves and analyzes their posture, body language, eye contact, and speech. The website then provides users with a specialized analysis of their presentation, rating on posture, eye contact, clarity, and pacing. The user can ask specific questions relating to their performance and improvement to a human-sounding conversational AI. Finally, Clarity Coach tracks prior runs of recordings and saves them and respective stats to show user progress over time.
How we built it
We built Clarity Coach as a full-stack AI application with the following stack:
• Backend: FastAPI + Uvicorn for asynchronous API endpoints; Pydantic for structured validation; python-multipart and aiofiles for video uploads; MoviePy for audio extraction; OpenCV + MediaPipe for video/pose processing; OpenAI + Anthropic APIs for transcript evaluation and feedback generation; Modal for scalable processing
• Frontend: HTML/CSS/JS for general web development; MediaRecorder API for in-browser recording
Challenges we ran into
We ran into lots of fickle issues along the way, requiring us to relentlessly and strategically debug. Some of the main challenges we faced were:
• Slow computing times of video and audio analyzing models → Solved by offloading inference to GPU-backed Modal containers to accelerate model processing
• Creating a natural conversational coaching experience → Solved by designing structured LLM outputs and prompt constraints to produce short voice-ready responses and a follow-up prompt, enabling iterative turn-taking
• Realtime voice sessions connecting but not returning audio → Solved by properly attaching WebRTC audio tracks and using ephemeral session tokens for authenticated streaming
• Synchronizing multiple AI services in one pipeline → Solved by sequencing transcription, LLM analysis, and text-to-speech generation to ensure reliable end-to-end responses
What we learned
As a team of beginner hackers, we learned SO MUCH within this period of 36 hours. Since the initial check-in, we’ve been living in and breathing the innovative air of Huang basement. Whether it was learning how to reason our idea into fruition or how to debug a seemingly trivial issue, we’ve become more inventive, more creative, and more confident in our abilities to solve problems in our communities.
In terms of concrete technical abilities, we learned:
• how to capture live audio using the MediaRecorder API and navigator.mediaDevices.getUserMedia()
• how to process chunks of recorded media and send them to a backend server
• how to structure a full-stack app with separated frontend and backend logic
• how to design feedback systems that turn raw model outputs into substantial insights
• how to stream microphone input as Blob chunks, encode them, and transmit via multipart/form-data to an Express backend
• how to orchestrate a real-time speech pipeline combining Whisper transcription, Claude LLM analysis, and ElevenLabs text-to-speech synthesis
• and lots more!
What's next for Clarity Coach
Next, we want to bring Clarity Coach beyond a standalone web app and make it something users can access wherever they practice speaking. We’re exploring browser extensions and lightweight integrations that provide feedback directly inside tools people already use! We’re also excited about building interactive AI avatars that simulate different interviewers or audiences (from a fast-paced recruiter to a skeptical panelist) so users can practice adapting their delivery in more realistic, dynamic environments.
Built With
- anthropic
- api
- claude
- css
- elevenlabs
- express.js
- getusermedia
- html
- javascript
- mediapipe
- mediarecorder
- modal
- moviepy
- node.js
- numpy
- openai
- opencv
- pydantic
- python
- realtime
- uvicorn
- webrtc
- whispher



Log in or sign up for Devpost to join the conversation.