-
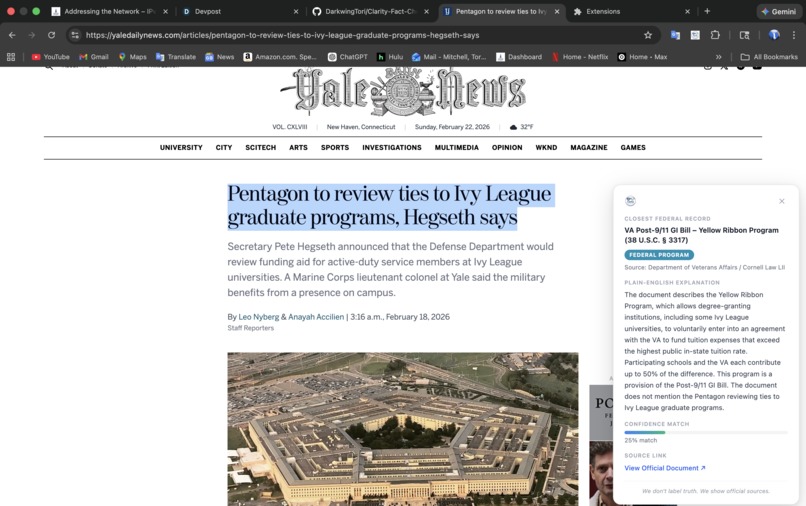
An example of Clarity identifying the lexemes to determine what the article may reference to in terms of government documentation.
Clarity -- See the Facts Clearly
Inspiration
It started with a simple question:
$$ \text{"How do we know what the government actually said?"} $$
Every day we encounter headlines and social media posts making claims about government actions, policies, and court decisions. "The government banned gas stoves." "Veterans can't use the GI Bill at elite schools." "Nursing is no longer a recognized degree." Some of these claims are accurate, some are misleading, and most are impossible to verify quickly.
When we tried to verify claims ourselves, we ran into the same wall every time:
- Fact-checkers tell you true or false — but rarely show you the actual document
- Government sources exist, but they're buried, technical, and hard to read
- By the time you've found the source, you've lost the thread of the conversation
This revealed a fundamental gap:
$$ \text{People don't want opinions about what's true.} \quad \text{They want evidence.} $$
Instead of building another fact-checker that renders a verdict, we asked a different question:
$$ \text{What if verification was instant — and the source did the talking?} $$
That question became Clarity.
Our guiding principle:
$$ \boxed{\text{Don't tell people what to believe — show them where it came from.}} $$
What It Does
Clarity is an AI-powered Chrome extension that connects any highlighted text on any webpage directly to official government documents in real time.
When a user highlights a claim, Clarity:
- Captures the selected text instantly
- Shows a loading card on the right side of the screen in under 50ms
- Sends the claim to a local Python backend
- Runs the claim against 27 federal documents using the Groq Cloud API
- Returns the closest matched source with a plain-English explanation and confidence score
Instead of:
$$ \text{Claim} \xrightarrow{\text{fact-checker}} \text{True / False} $$
Clarity delivers:
$$ \text{Claim} \xrightarrow{\text{AI}} \text{Primary Source} + \text{Plain-English Summary} $$
The user decides what to think. We just show them where to look.
How We Built It
We built Clarity in four distinct phases, each solving the limitations of the phase before it.
Phase 1 — The Hardcoded MVP
We started as simple as possible. The backend was a Python dictionary with three pre-written responses, and the matching logic was pure substring search:
$$ \text{if } \texttt{"nursing"} \in \text{claim.lower()} \Rightarrow \text{return nursing_response} $$
This covered exactly three topics — nursing degrees, GI Bill benefits, and gas stoves — and only if the user happened to use one of our expected keywords. Any other phrasing would fall through to a generic fallback.
It was functional enough to demo. It was not good enough to ship.
Phase 2 — Replacing Rules With Reasoning (Groq + Llama)
The breakthrough came when we replaced the keyword dictionary with a real language model.
We integrated the Groq Cloud API running Meta's Llama 3.1 model. Instead of checking for keywords, we send the entire claim alongside all available federal documents to the LLM and ask it to reason:
$$ \text{Given claim } c \text{ and documents } {d_1, d_2, \ldots, d_n}, \quad \text{find } \arg\max_i \; \text{Relevance}(c, d_i) $$
The model returns structured JSON with four fields:
cleaned_claim— the claim rephrased as a neutral questionmatched_document_id— the ID of the best matching documentsummary— a 3–4 sentence plain-English explanation grounded only in the documentsimilarity_score— a confidence float from 0.0 to 1.0
We enforced structured output using response_format={"type": "json_object"} and temperature=0.1 to keep responses factual and consistent.
This meant a user could highlight "my army buddy can't use his benefits at a fancy school" and Clarity would correctly match the GI Bill Yellow Ribbon Program — even though the words "GI Bill," "veteran," and "Yellow Ribbon" never appeared in the highlighted text.
The semantic gap between informal claim and formal document:
$$ \text{Short informal claim} \xrightarrow{\text{LLM}} \text{Long technical document} $$
was bridged entirely by the model's language understanding — no rules needed.
We initially used llama-3.3-70b-versatile (70 billion parameters), but response times were 2–4 seconds. Switching to llama-3.1-8b-instant (8 billion parameters, purpose-built for speed) cut that to under one second with no meaningful loss in matching quality.
Phase 3 — Building a Credible Document Index
An AI is only as trustworthy as its sources.
We grew the document index from 3 entries to 27 federal documents across 9 topic areas, carefully selecting what to include:
| Topic Area | Coverage |
|---|---|
| Healthcare | ACA, Dobbs v. Jackson, Medicare Part D |
| Immigration | DACA, Title 42 border policy |
| Education | Student loan forgiveness (Biden v. Nebraska), Title IX |
| Economy & Labor | TCJA 2017, minimum wage, Inflation Reduction Act |
| Environment | Paris Agreement, Keystone XL EO |
| Guns | Brady Act / NICS, Bipartisan Safer Communities Act |
| Social Programs | SNAP eligibility, Social Security solvency |
| Voting & Civil Rights | Shelby County v. Holder, Citizens United |
| COVID-19 | CARES Act, OSHA vaccine mandate (NFIB v. OSHA) |
We also made a deliberate decision about sourcing. Rather than linking only to agency .gov pages — which can move or be updated — we routed statutes to Cornell Law LII (stable U.S. Code permalinks), Supreme Court cases to Oyez (plain-language summaries with full oral argument audio), and fiscal claims to the Congressional Budget Office and Government Accountability Office, both nonpartisan by law.
The credibility formula:
$$ \text{Trust} = f(\text{Source Authority}, \text{Source Neutrality}, \text{Source Stability}) $$
All three had to be high.
Phase 4 — Fixing the User Experience
Two UX problems needed solving.
Problem 1: Dead silence. After highlighting text, the user saw nothing for 1–2 seconds. There was no indication the extension had registered the selection at all.
Solution: We separated the overlay into two functions. showClarityLoading(rect) fires in under 50ms — immediately after selection — showing the card with a spinning indicator. showClarityOverlay(data, rect) replaces it when the API responds. The user always knows something is happening:
$$ T_{\text{feedback}} \approx 50\text{ms} \ll T_{\text{API}} \approx 800\text{ms} $$
Problem 2: Off-screen positioning. The card was anchored below the selected text using rect.bottom + 14. Highlighting text near the bottom of a page pushed the card entirely below the viewport.
Solution: We moved to right-side fixed positioning:
$$ \text{left} \to \text{right: 12px}, \quad \text{top} = \min(\text{rect.top},\; \text{innerHeight} - 100) $$
The card now always appears on the right edge of the screen, vertically aligned with the selection and clamped within the viewport. We added max-height: calc(100vh - 24px) with overflow-y: auto so even a tall result card never extends beyond the screen.
What We Learned
Technical Lessons
LLMs replace rule engines. What took hundreds of lines of keyword matching, edge-case handling, and synonym dictionaries collapsed into a single well-structured prompt. The model reasons over language the way a human researcher would.
Perceived performance is real performance. Adding a loading state that fires in 50ms made the extension feel dramatically faster, even though the actual API response time was unchanged. Users tolerate waiting — they don't tolerate silence.
You don't need infrastructure to use world-class AI. Groq runs their own LPU hardware in their data centers. We inherit the speed through a simple API call. No GPUs, no model deployment, no inference optimization — we just write the prompt.
A flat JSON file beats a database. Our entire document index lives in a single
documents.jsonfile loaded into memory at startup. For a read-only dataset of 27 entries, this is faster, simpler, and easier to maintain than any database would have been.
$$ \text{Right tool for the right job:} \quad \text{complexity} \propto \text{actual need} $$
Product Lessons
Trust is a design problem. We had early ideas for bias scoring, truth ratings, and political classification. We dropped all of them. The moment Clarity makes a judgment call about what's "true," it becomes one more opinion in a sea of opinions. Neutral framing — showing the source without commentary — is what makes the tool trustworthy.
Source quality is the product. The AI matching is impressive technically, but what users actually see is a link to a document. If that document is a dead
.govpage or a partisan source, the whole experience falls apart. We spent significant time on sourcing standards.
$$ \text{Product quality} = \text{AI accuracy} \times \text{Source credibility} $$
Both factors multiply. Either one going to zero makes the product useless.
Challenges We Faced
Challenge 1 — Keyword Matching Was Fundamentally Broken
Our first version required users to phrase their highlights in ways that matched our expected keywords. A user highlighting "the federal government is cutting nursing programs" got a match. A user highlighting "RNs losing their credentials" got the fallback.
$$ \text{Precision} \uparrow \text{ but } \text{Recall} \downarrow \text{ with keyword matching} $$
The only real fix was semantic understanding. Integrating Groq and Llama solved this completely — the model handles any phrasing, any topic, any level of formality.
Challenge 2 — Latency vs. Quality Tradeoff
llama-3.3-70b-versatile produced excellent results but at 2–4 seconds per request. That's too slow for a browser extension where users expect near-instant feedback.
We tested llama-3.1-8b-instant and found the quality difference for document matching was negligible — the task (select the best document from a list of 27) doesn't require a 70B model. The 8B model handles it accurately at a fraction of the latency.
$$ \text{Quality}{8B} \approx \text{Quality}{70B} \quad \text{for this task} \quad \text{but} \quad T_{8B} \ll T_{70B} $$
The right model for the job is not always the biggest model.
Challenge 3 — Chrome's Content Security Policy
Chrome extensions running on HTTPS pages cannot make direct fetch() calls to http://localhost. The page's Content Security Policy blocks it. Our content scripts (which inject into the page) hit this wall immediately.
The solution was routing all network requests through a background service worker, which runs in the extension's own context and is not subject to the page's CSP. Every analysis request takes the path:
$$ \text{content.js} \xrightarrow{\text{sendMessage}} \text{background.js} \xrightarrow{\text{fetch}} \text{localhost:8001} $$
A layer of indirection that bypasses the security restriction entirely.
Challenge 4 — The Overlay Went Off-Screen
Positioning a floating element relative to selected text sounds simple. It isn't. Anchoring to rect.bottom + 14 means the card follows the text — right off the bottom of the screen when text appears in the lower half of the page.
Moving to right-side fixed positioning decoupled the card's horizontal position from the text entirely:
$$ x = \text{window.innerWidth} - 12 - \text{card width} \quad \text{(always)} $$
$$ y = \text{clamp}(\text{rect.top},\; 12,\; \text{innerHeight} - 100) $$
The card now lives in a consistent, always-visible position regardless of where on the page the user highlights.
Challenge 5 — Source Credibility at Scale
Adding more documents to the index is easy. Adding trustworthy documents is harder.
For every new topic, we had to answer:
- Is this source nonpartisan?
- Will this URL still work in a year?
- Does this document actually address common misconceptions about this topic?
We landed on a tiered sourcing standard: .gov agencies for policy and programs, Cornell LII for statute text, Oyez for court decisions, CBO for fiscal claims, and GAO for government accountability findings. No news outlets, no think tanks, no opinion sources.
$$ \text{Credibility standard:} \quad \text{Source} \in {\text{.gov}, \; \text{Cornell LII}, \; \text{Oyez}, \; \text{CBO}, \; \text{GAO}} $$
Why Clarity Matters
The problem with modern information isn't a lack of content. It's a lack of primary sources.
Today, the typical path from claim to verification looks like:
$$ \text{Claim} \rightarrow \text{Search engine} \rightarrow \text{Opinion article} \rightarrow \text{More uncertainty} $$
Clarity short-circuits that entire chain:
$$ \text{Highlight} \rightarrow \text{Primary source} \rightarrow \text{Read for yourself} $$
We're not arbiters of truth. We're a direct line to the original document — available in under one second, on any webpage, for any claim about U.S. federal policy.
Future Plans
The foundation is built. The roadmap extends it:
- Full Article Mode — scan an entire page at once, flag every checkable claim
- Live index updates — new executive orders and signed bills added within 24 hours
- Citation export — MLA, APA, Chicago format for journalists and researchers
- State-level documents — expand beyond federal to all 50 state law databases
- Voting records — show how each representative voted on the matched bill
Better models mean better matches:
$$ \text{Larger index} + \text{Better models} \Rightarrow \text{More accurate matches} $$
Conclusion
Clarity demonstrates what becomes possible when AI is used to increase access to primary sources rather than to replace human judgment about them.
$$ \text{AI} + \text{Primary Sources} = \text{Informed Users} $$
We didn't build a tool that tells you what's true. We built a tool that shows you where it came from — instantly, neutrally, and always grounded in official documents.
$$ \boxed{\text{See the Facts Clearly.}} $$
That is the goal of Clarity.
Built With
- css
- fastapi
- groq
- html
- javascript
- llama
- pydantic
- python
- uvicorn

Log in or sign up for Devpost to join the conversation.