-
Home page
-
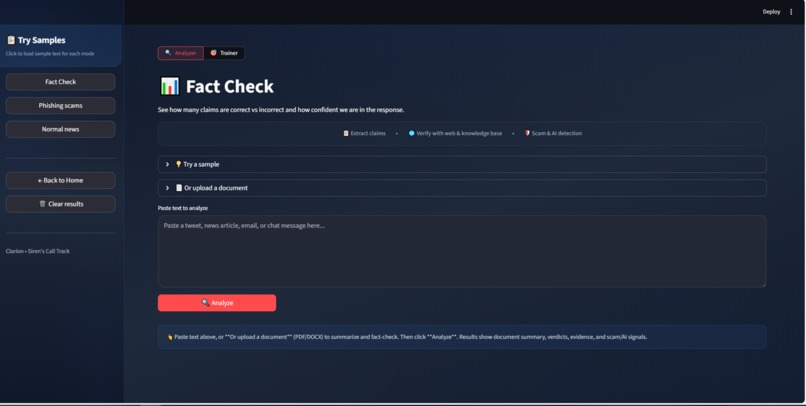
Fact Check Page
-
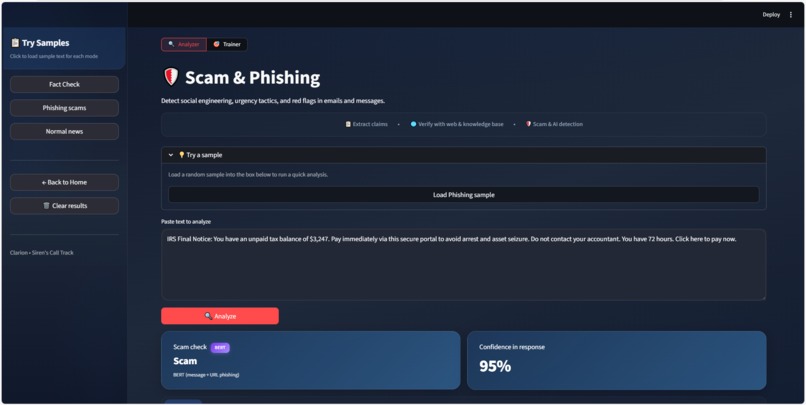
Phishing detector
-
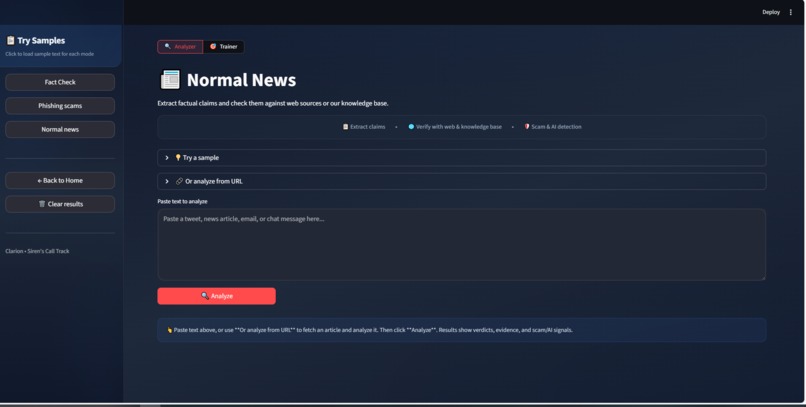
News checker
-
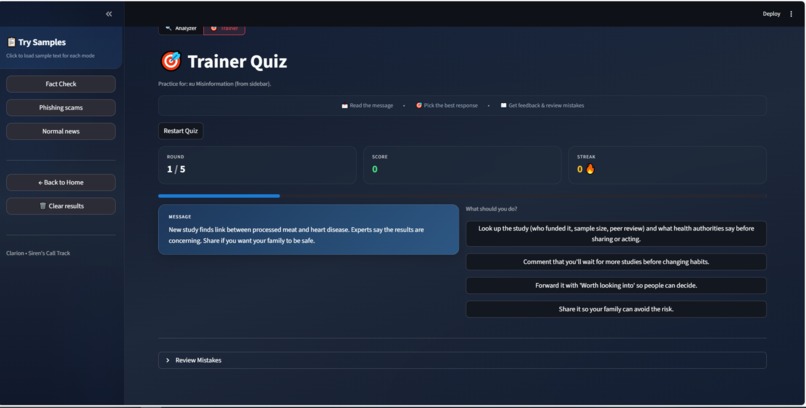
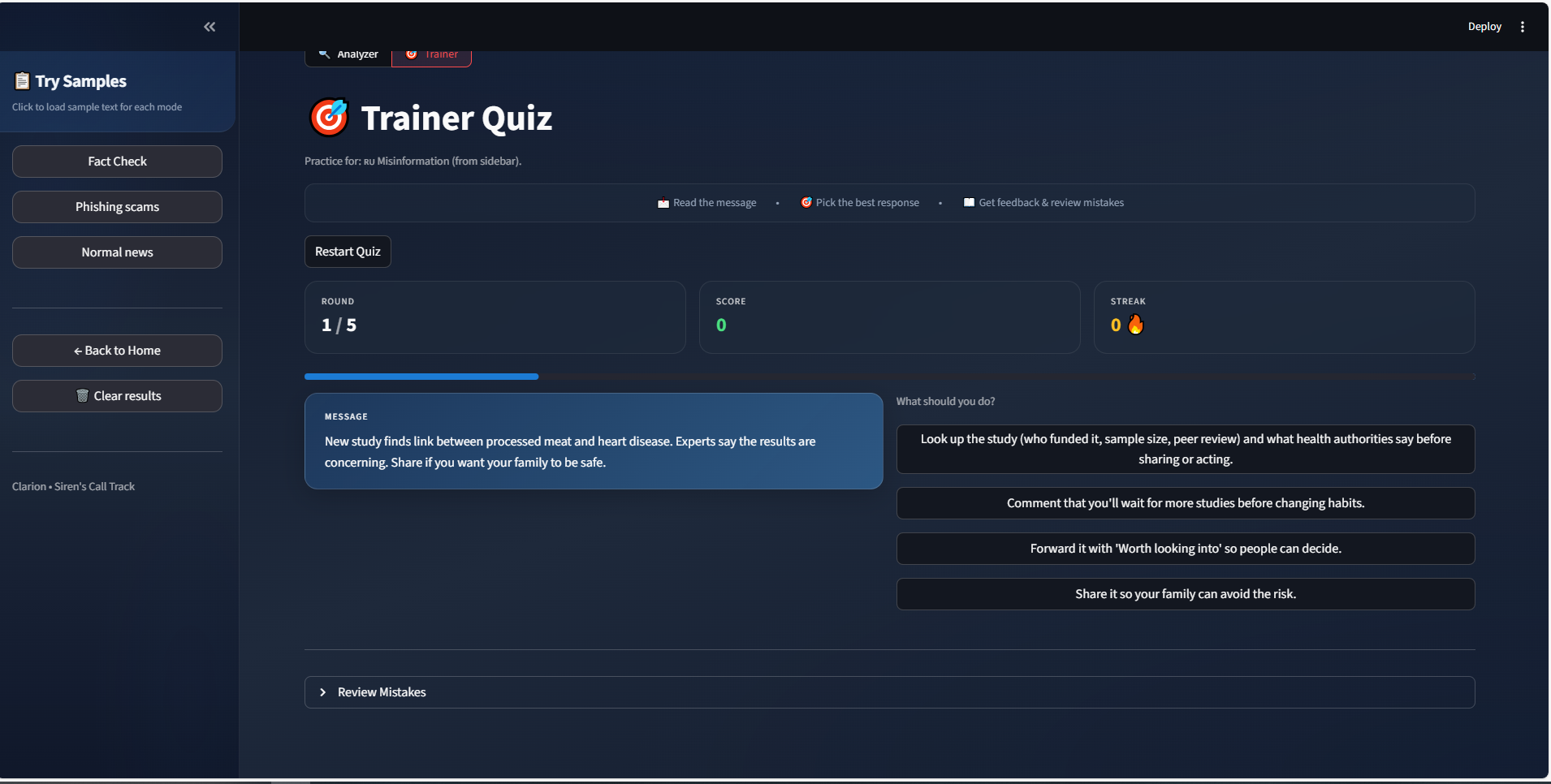
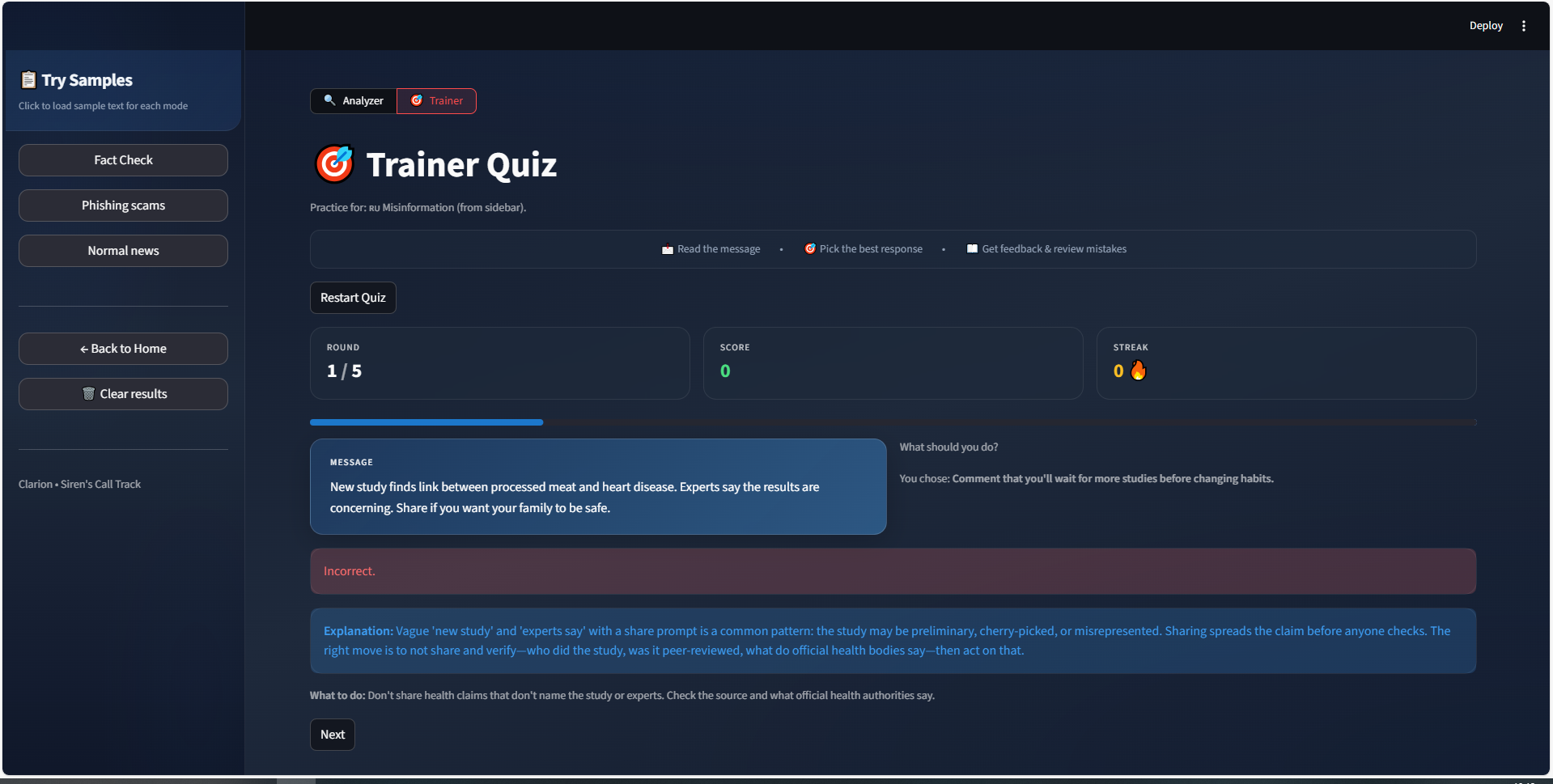
quiz
-
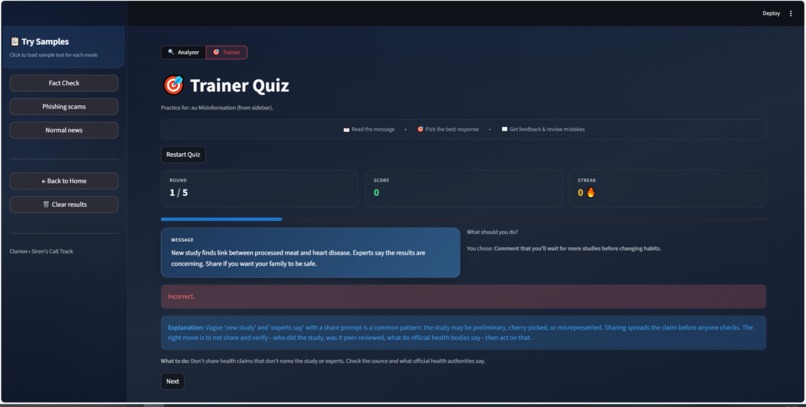
Quiz
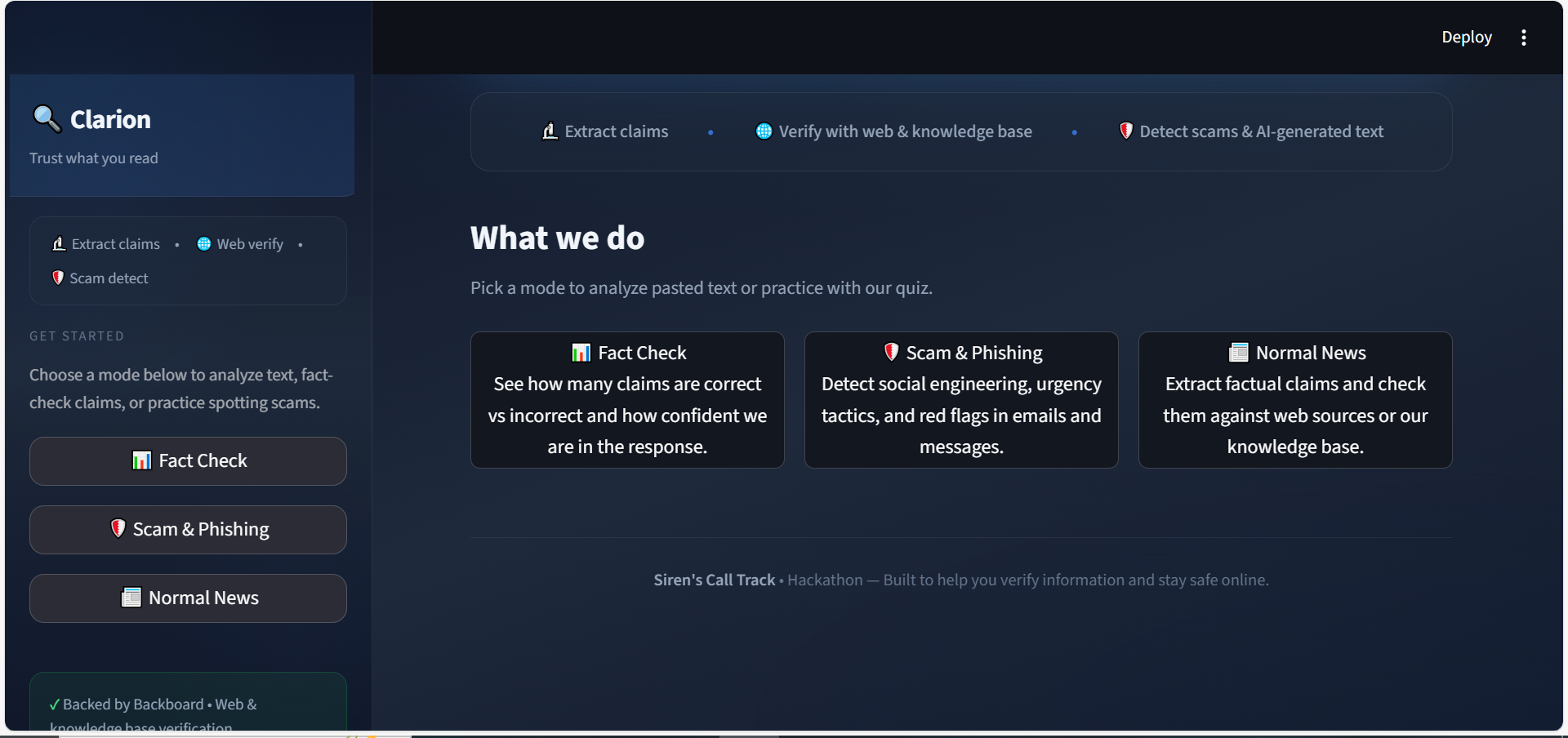
Clarion
Inspiration
Misinformation isn't just "fake news" anymore. It's manipulative messaging, phishing that looks like your bank, and AI-generated text that sounds just human enough to be dangerous. Most people don't have a quick, simple way to check whether something is trustworthy, so we asked: what if one app could take any text and tell you how risky it is, in plain language?
We built Clarion on the Siren's Call track to do exactly that: a single place where you can paste, upload, or link to content and get a clear, multi-layer trust analysis, without needing API keys or a PhD.
What it does
Clarion is a web app where you paste text, upload a document, or drop in a URL and get a full trust check in one go.
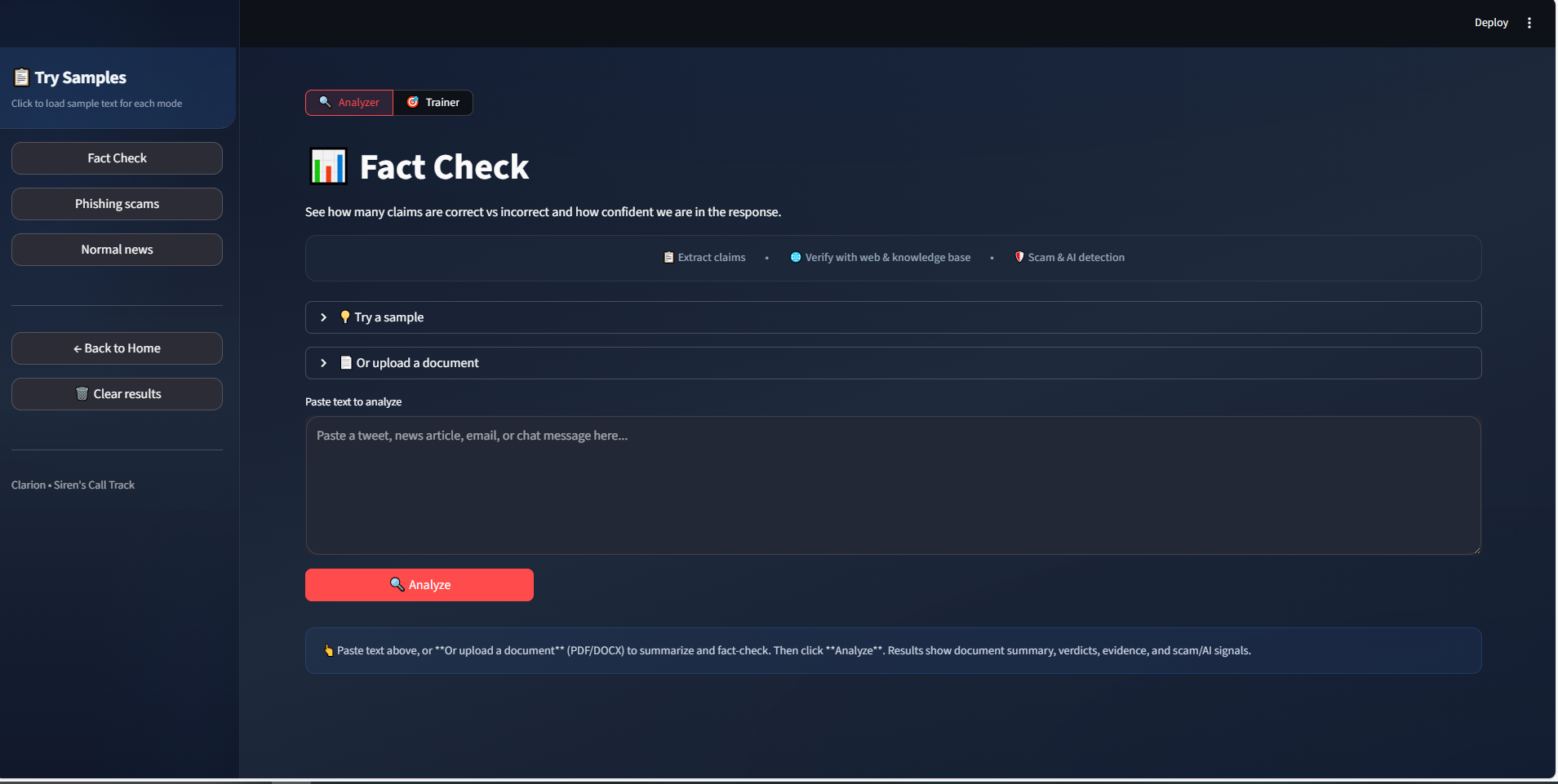
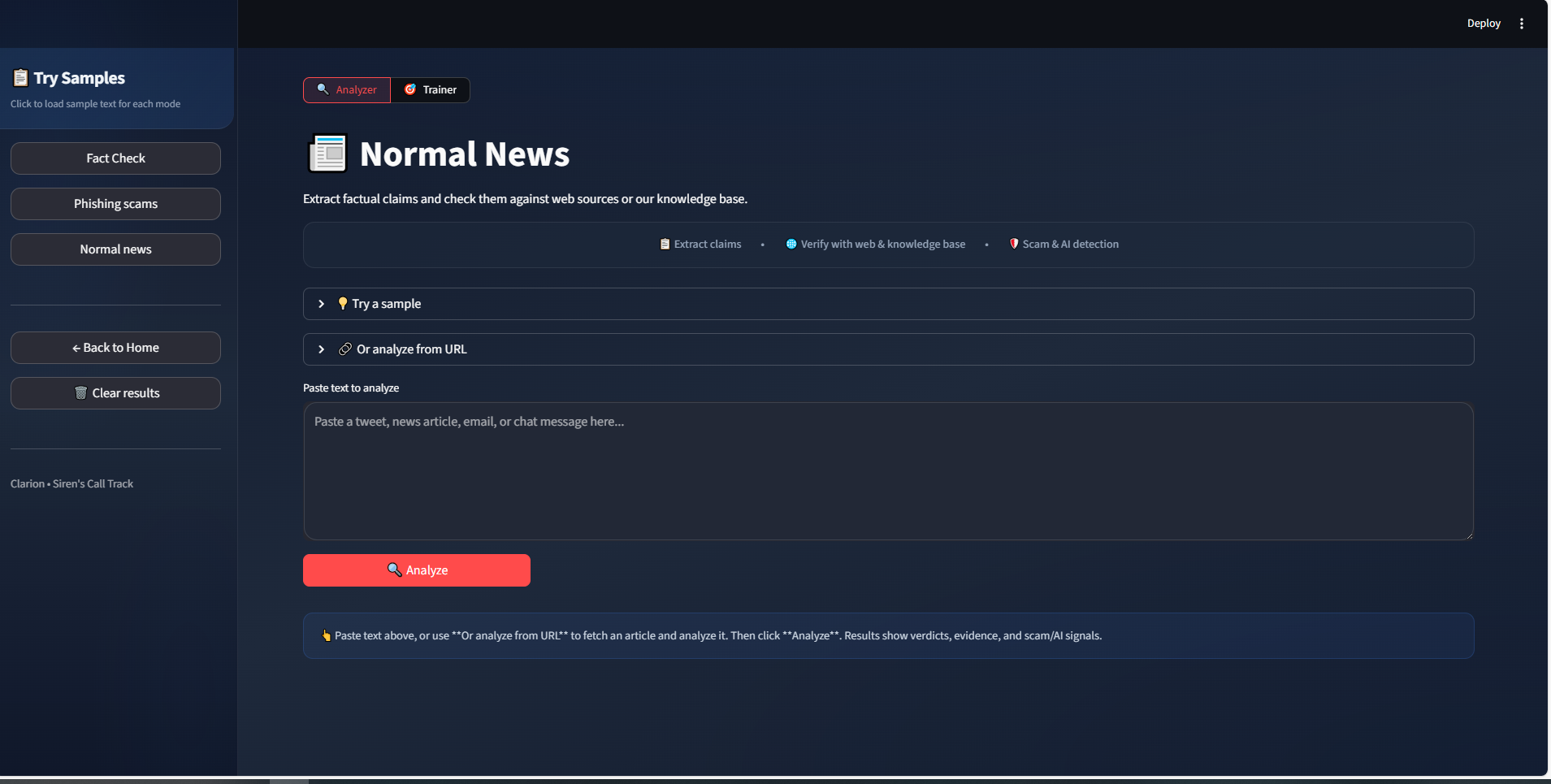
Fact-checking
Paste a paragraph, upload a PDF or DOCX, or paste a news/article URL. We pull out individual claims, check them against the web (and our own knowledge base when needed), and show you how many are supported vs refuted, plus an overall confidence score.
Risk and manipulation
We combine those results with other signals to flag misleading or manipulative patterns and spell out what's suspicious.
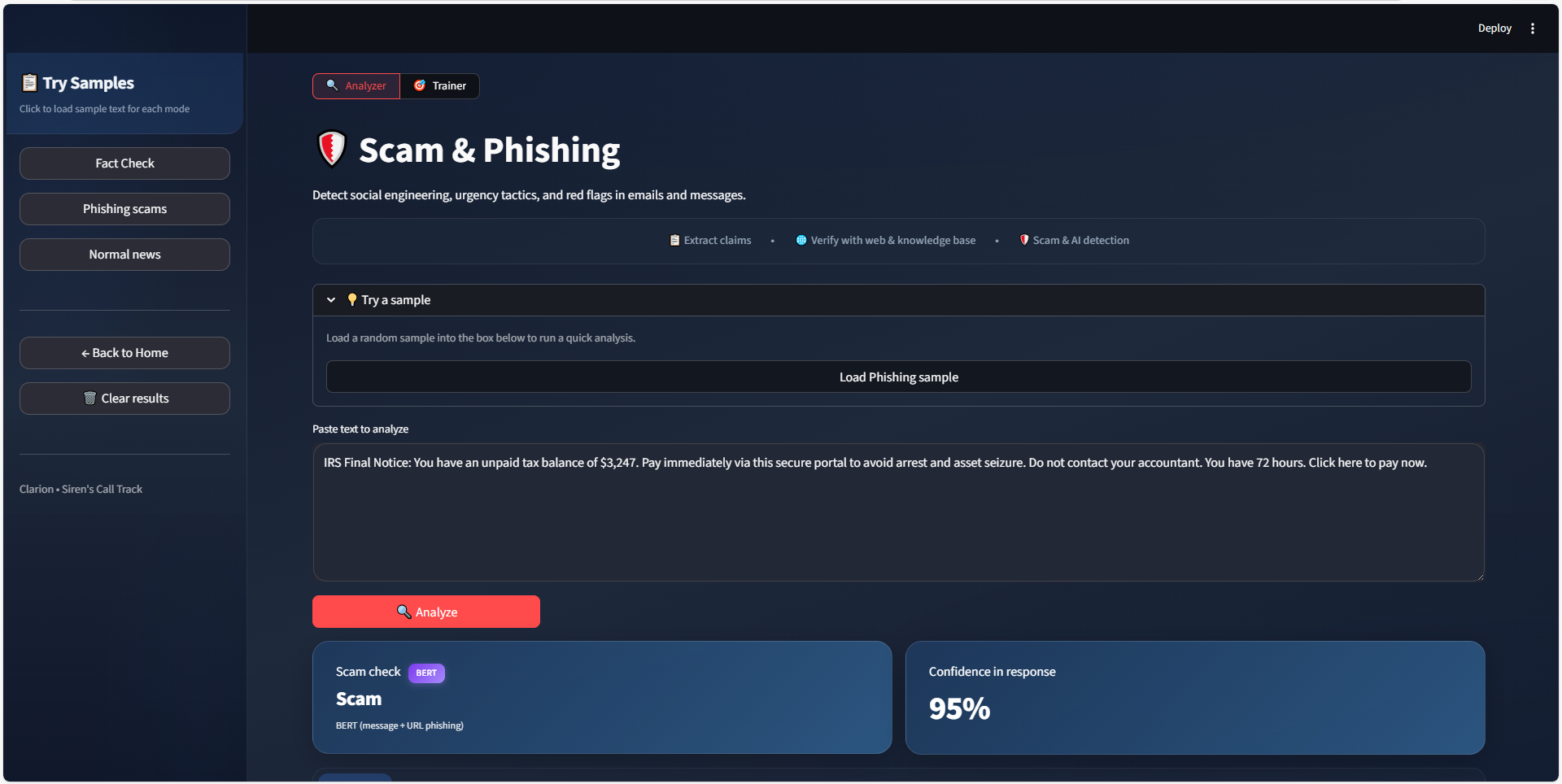
Scam and phishing
A local BERT model scores messages and URLs for phishing and scam tactics so you can spot "urgent" or "verify now" style content.
AI-generated text
We use simple but effective heuristics (repetition, generic phrasing, etc.) to suggest when text might be synthetic.
Evidence
We don't just say "trust" or "don't trust." We show snippets and sources so you can see why we said it.
Document upload (Fact Check)
In Fact Check mode, upload a PDF or DOCX. We extract the text, optionally summarize it, and run the same claim extraction and verification.
URL analyze (News & Fact Check)
Paste an article or page URL. We fetch the content, extract the main text, and run the same pipeline. Great for checking a news link or a long read without copying and pasting.
All of this is designed to work without API keys, so it's easy to run and demo anywhere.
How we built it
We wanted a pipeline that's modular, explainable, and still fast enough to feel useful.
1. Input preprocessing
We clean the text and break it into atomic claims using rule-based extraction. No LLM calls, so it's cheap and predictable. Input can be pasted text, an uploaded document (Fact Check), or content fetched from a URL.
2. Verification
We verify claims with a clear order of operations: DuckDuckGo web search first, optional Backboard when configured, and a local RAG knowledge base as an offline fallback. So the app keeps working even when the internet is flaky or you're offline.
3. Detection
A local BERT model handles phishing/scam classification. No external API means consistent behavior and no per-call cost.
4. Scoring
We bring everything into one view: claim-level correctness, detector scores, and confidence. The high-level confidence blends verification and detection like this:
$$ \text{Confidence} \propto 0.4 \times \text{claim_score} + 0.6 \times \text{detector_score} $$
Tech we used
Python, Streamlit for the UI, duckduckgo-search for web verification, Hugging Face (BERT) for phishing, optional Backboard, and a local RAG. For document upload we use pypdf and python-docx; for URL analysis we use requests and BeautifulSoup to fetch and extract article text.
Challenges we ran into
Claim extraction without an LLM
Skipping LLMs kept things fast and free but made claim extraction trickier. Our rule-based approach is solid for most text but sometimes misses very implicit or nested claims.
Zero-API design
We wanted "works out of the box." That meant careful fallback logic: Backboard to DuckDuckGo to Local RAG, so the app degrades gracefully instead of failing hard.
Speed vs depth
Web verification is more accurate but slower. We tuned the pipeline so it stays responsive while still giving enough depth for judges and users to trust the results.
One story from many signals
Fact checks, phishing scores, and AI heuristics had to be combined into a single, readable story without overwhelming people. We spent time on normalization and wording so the output feels coherent, not like a dashboard dump.
Accomplishments we're proud of
- One place for trust: Fact-checking, phishing, and AI signals in a single flow.
- Document upload and URL analysis: You can analyze a PDF, a Word doc, or a news link without copying text.
- Runs without API keys: Portable and demo-friendly.
- Transparent metrics: Claim-level verdicts and confidence so you see how we got there.
- Graceful fallbacks: The app keeps working when services are down or offline.
- Evidence-first: We show why something was flagged, not just a score.
What we learned
- Trust is multi-dimensional: truth, intent, and manipulation all matter, and the product had to reflect that.
- Modular pipelines made it easier to swap backends and add document/URL inputs without rewriting everything.
- Local models gave us predictable behavior and no per-request cost.
- Explainability was non-negotiable: people trust the tool more when they can follow the reasoning.
- Small heuristics (repetition, generic phrasing) turned out to be surprisingly useful in practice.
What's next
- Stronger AI-generated text detection (e.g. perplexity-based).
- Richer multilingual claim extraction.
- Batch analysis for feeds or multiple messages.
- Adaptive feedback and persistent memory to make the tool more personalized over time.
The one-liner
Clarion is a unified trust-analysis platform: paste text, upload a document, or paste a URL, and get fact-checking, risk detection, and AI-content analysis in one place, so you can see how trustworthy something really is.
Built With
- backboard.io
- python
- streamlit


Log in or sign up for Devpost to join the conversation.