-
-

Front Page!
-
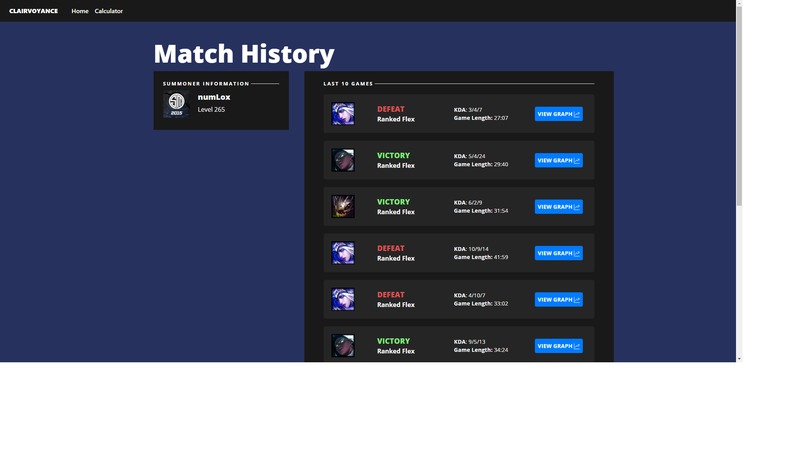
Match History
-
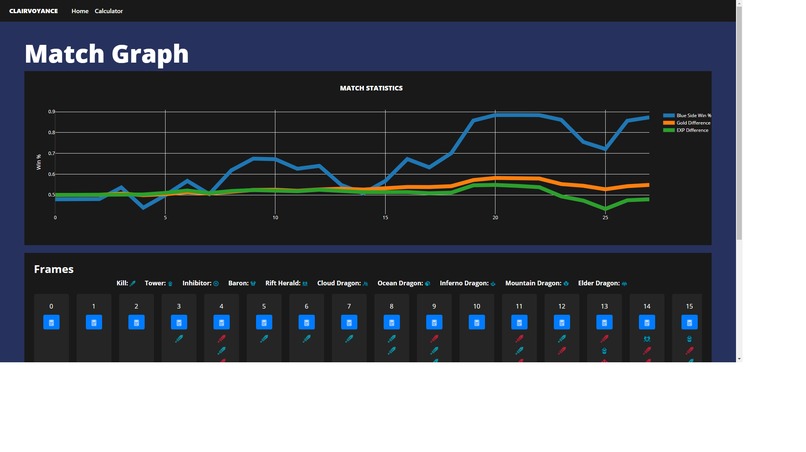
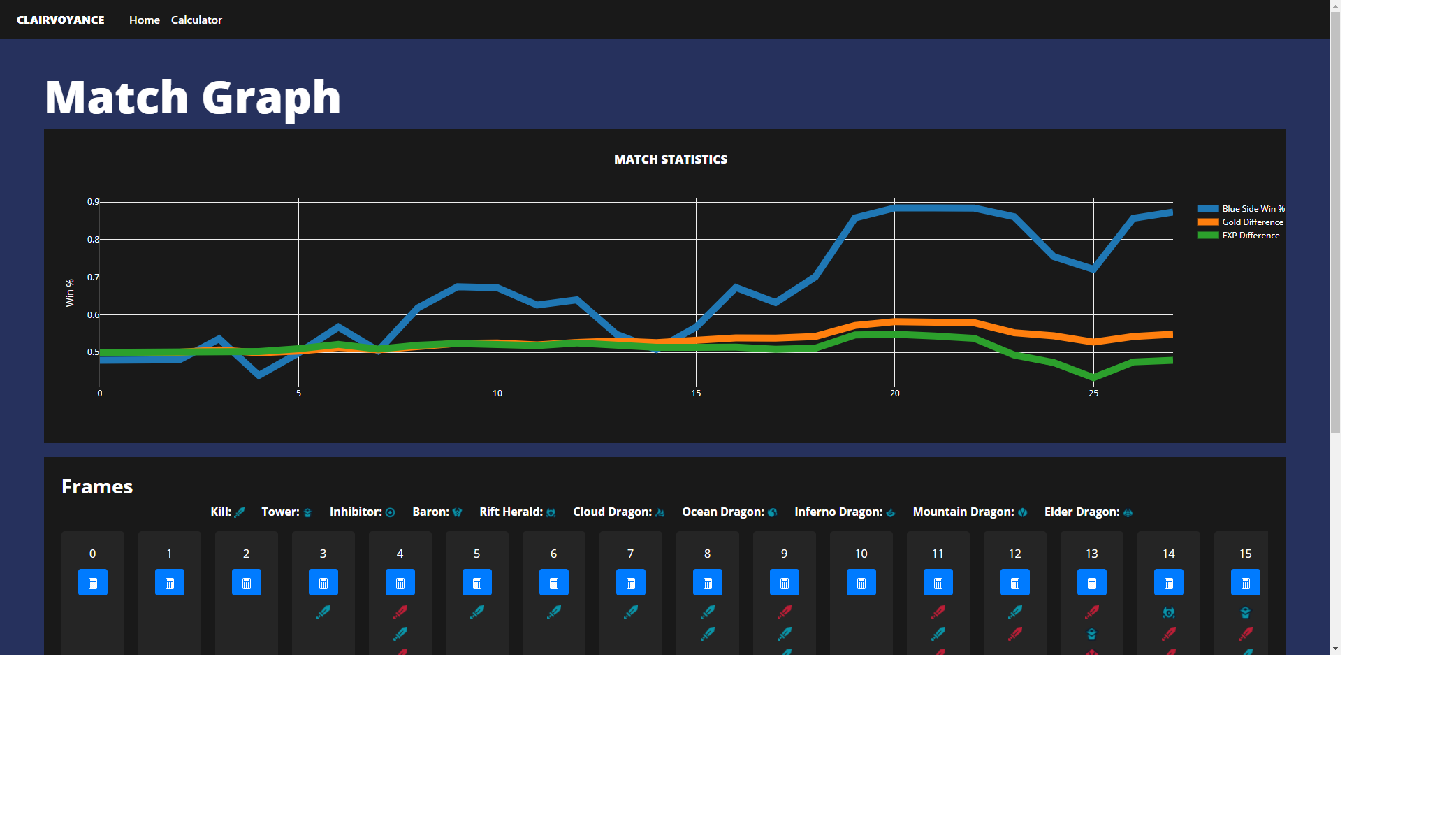
Graph Page, with win% plotted against gold diff and exp diff
-
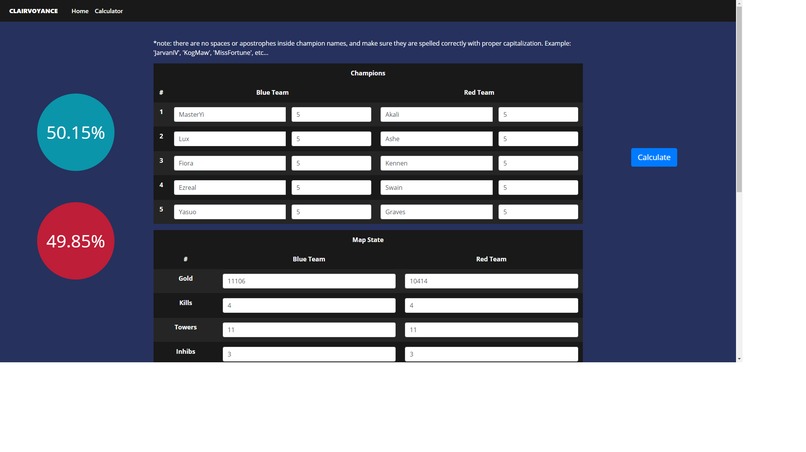
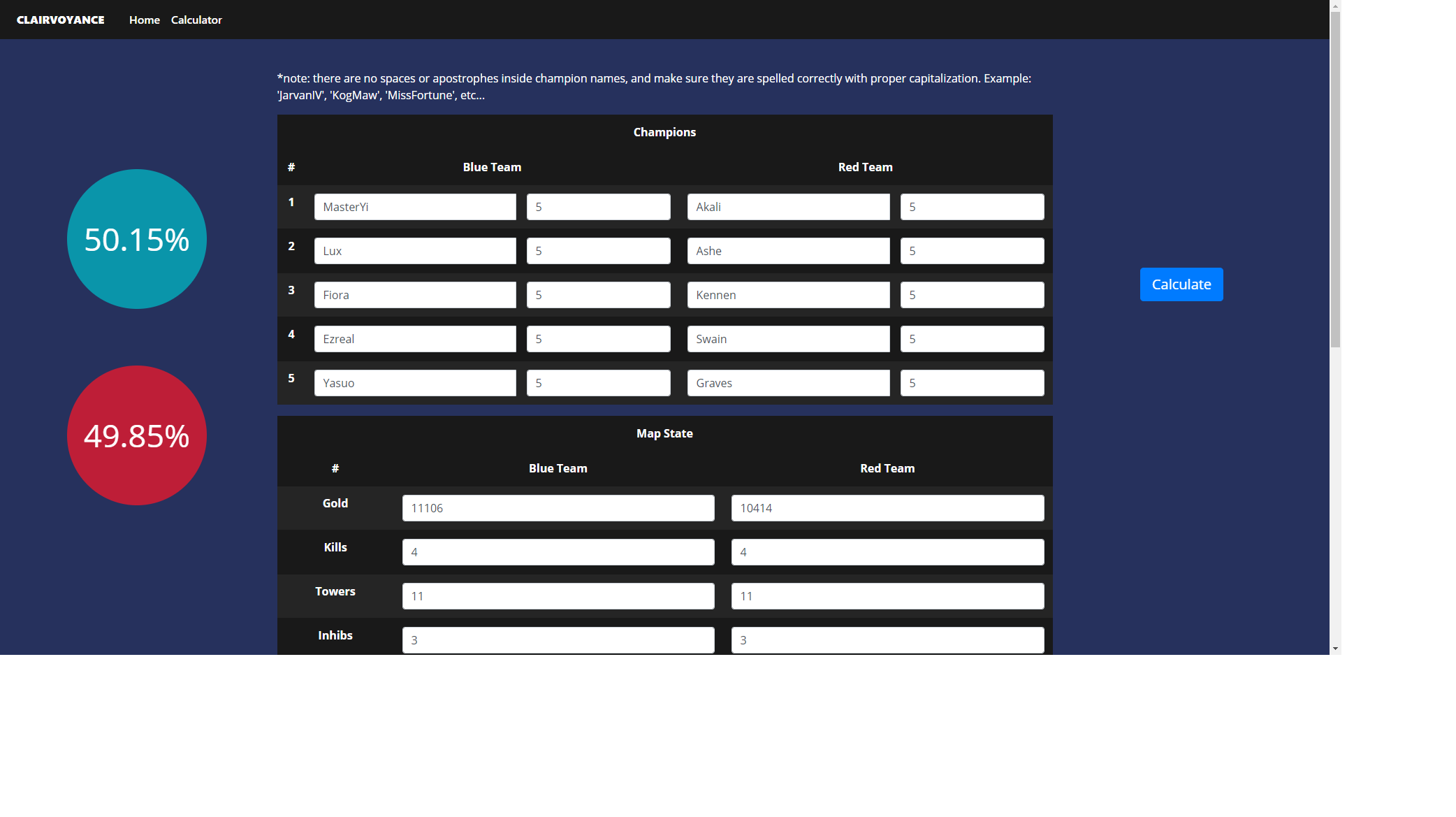
Calculator Page, where you are able to input your own data


the rate limit on our API calls are very limited, so if the website experiences heavy traffic or repeated usage, we might exceed our rate limit and cause a 404. Here are our rate limits: 20/seconds, 100/2 minutes. Each summoner lookup uses about 12 API calls.
Inspiration
This project was inspired by the Oracle Elixir machine learning model to predict win% in LoL. I really wanted to build a model that was more holistic and takes into account champions, types of dragons, all that sort of data when making predictions. With this tool, we can compare things like whether an infernal drake or a mountain drake is better for your team composition.
What it does
The web app uses a neural network built with PyTorch to estimate win probabilities in the game, given data like champion picks, total team gold, total team exp, etc.
From the front page, you can input your summoners name (we're restricted to NA for the time being) and it will show you your match history, much like op.gg. There will be a view graph button and it will take you to our graphing page. There, you will see the win probability plotted against stats like gold differential and exp differential. Below the graph, there is a timeline where you can export the data at each frame into our custom calculator, where you can play around with the data (perhaps try things like "what if the enemy team got that dragon") and calculate the results there!
How we built it
We used PyTorch to build the model, Bootstrap for the CSS on our website, Flask for the backend interfacing, and Plotly to plot graphs.
Challenges we ran into
Merge issues are the worst!!
The data pipeline was difficult to build, as many components needed different types of data to function. The model was also hard to make robust, as it would often get caught up on the champion picks and not look at other data. We also had a team member who was new to "hacking" and had to help him out with using GitHub, VSCode, and Bootstrap
Accomplishments that we're proud of
In the end, the model was pretty robust, and makes good predictions. The website in general looks very sleek as well, and we're very happy with ourselves for that.
What we learned
None of us really had any significant amount of experience with Flask or pushing machine learning models to production, so this was really educational as we learned how to do those things. We also experimented with different neural network architectures, and this was helpful in gaining experience with that as well.
What's next for Clairvoyance
We want to polish up the website, as a lot of hacks were used to make it work. The model can be improved as well, if we have more time to tweak its architecture.


Log in or sign up for Devpost to join the conversation.