

Project Story
Inspiration
Every year, 6 million property damage claims are filed in the US alone. The average policyholder spends 25 minutes on the phone just to file the initial report — navigating IVR menus, repeating information to multiple agents, and waiting on hold. On the insurer side, each claim costs ~$40 to process manually, and the industry hemorrhages $80 billion annually to fraud — a problem now supercharged by AI-generated deepfakes that can fabricate damage photos in seconds.
We asked: what if a policyholder could file a complete claim — with damage documentation, fraud screening, weather verification, cost estimation, and FNOL submission — in a single live conversation with an AI that can see, hear, and speak?
That's ClaimSight.
What it does
ClaimSight is a multi-agent AI claims assistant that handles the entire insurance claims lifecycle in one real-time conversation. A policyholder opens the app, describes their situation by voice or text, and ClaimSight takes over:
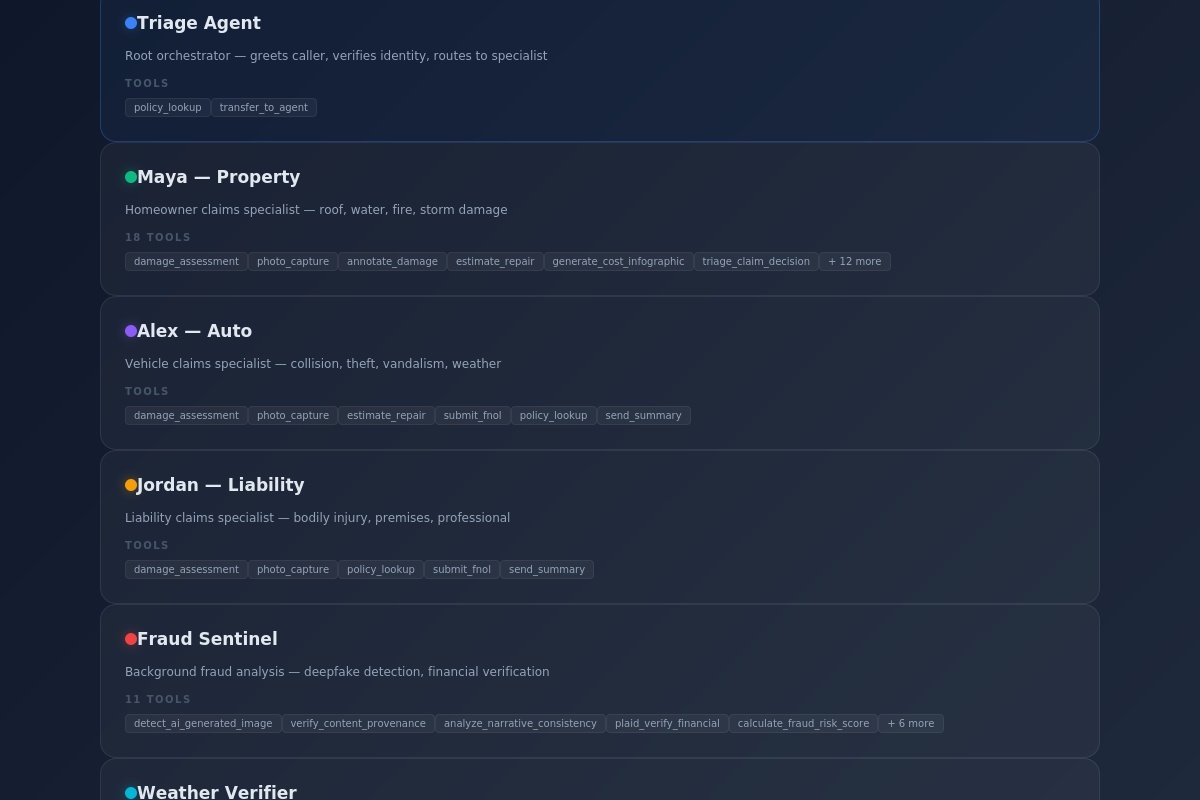
- Triage Agent greets the caller, pulls up their policy, identifies the loss type, and routes to the right specialist
- Maya (Property), Alex (Auto), or Jordan (Liability) — each with a distinct personality and natural voice — takes a detailed statement, captures photos through the live camera feed, assesses damage severity, and generates repair cost estimates
- Fraud Sentinel runs 11 tools in parallel behind the scenes — analyzing narrative consistency, detecting AI-generated/manipulated images with 3-layer deepfake detection, verifying content provenance via C2PA standards, and checking financial records through Plaid
- Weather Verifier cross-references storm claims against historical weather data for the reported location and date
- The system generates AI-annotated damage images (severity-coded markers), repair visualizations, and itemized cost infographics — all using Gemini's image generation
- Finally, it makes a triage decision, generates an adjuster brief, and submits the FNOL — all within a single session
The user can interrupt the agent mid-speech (barge-in), switch between voice and text, and watch every tool call happen in real-time through the Agent Brain panel.
How we built it
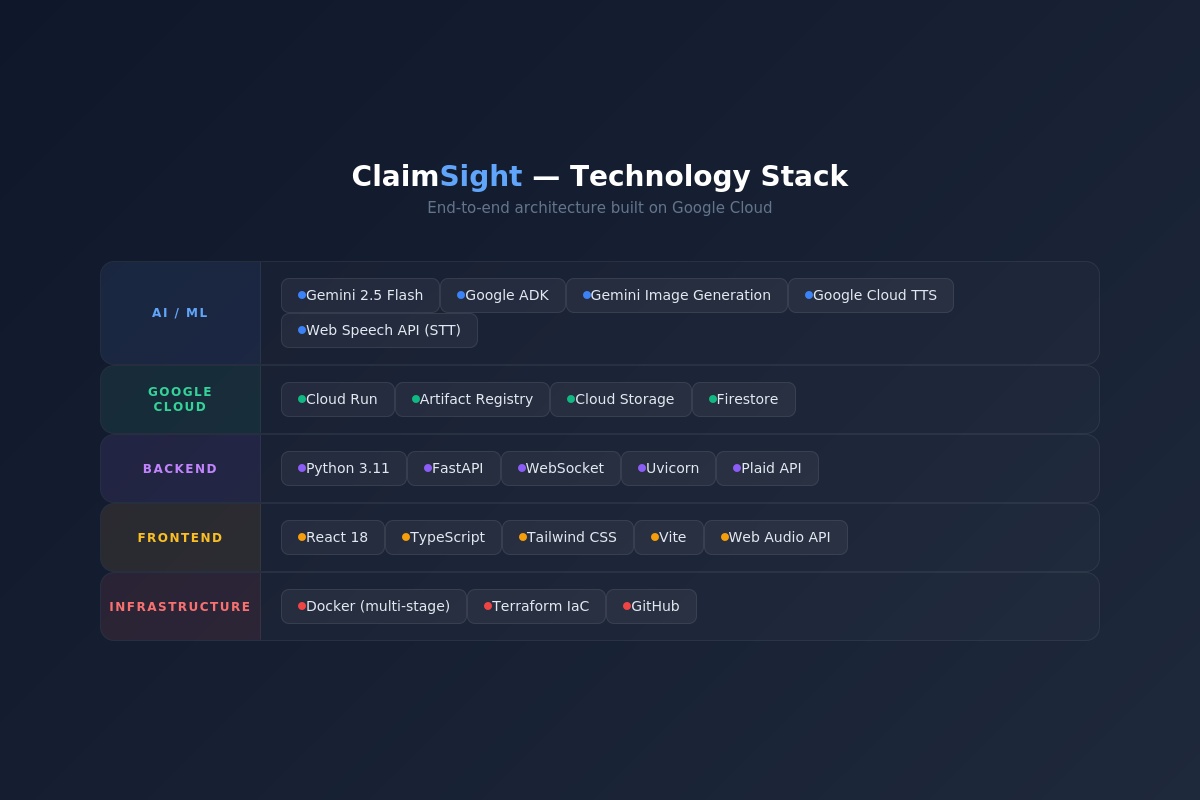
Backend: Python FastAPI server using Google ADK (Agent Development Kit) for multi-agent orchestration. 6 agents with 24 tools, powered by Gemini 2.5 Flash as the LLM. Each agent is defined with specific instructions, tools, and personality. The ADK runner handles agent transfers, tool execution, and session management.
Frontend: React + TypeScript with Tailwind CSS. Real-time WebSocket connection for bidirectional communication. Web Speech API for speech-to-text, Google Cloud Text-to-Speech for natural agent voices (Journey and Neural2 voice models — each agent has their own voice). Live camera feed captured at 1 FPS and sent to the backend for vision-capable tools.
AI/ML Pipeline:
- Gemini 2.5 Flash for conversational AI and tool orchestration
- Gemini image generation for damage annotations, repair visualizations, and cost infographics
- 3-layer deepfake detection: AI-generated image analysis, C2PA content provenance verification, and media authenticity scoring
- Plaid API integration for financial verification in fraud detection
Infrastructure: Deployed on Google Cloud Run with a multi-stage Docker build (Node frontend + Python backend). Terraform infrastructure-as-code for reproducible deployment (Cloud Run, Firestore, Artifact Registry, Cloud Storage).
Challenges we ran into
Agent response deduplication: When one agent transfers to another mid-conversation, both agents can produce text in the same turn. We had to build careful deduplication logic — tracking which agent is speaking, clearing buffers on transfer, and sending pre-transfer text as a separate message so responses don't get jumbled together.
Echo prevention in voice mode: The agent's TTS voice would get picked up by the user's microphone and fed back as user input, creating an infinite feedback loop. We solved this by pausing speech recognition during TTS playback and resuming with a 600ms delay to let trailing audio dissipate.
Progressive text reveal: We wanted the chat text to appear in sync with the agent's speech — not all at once. This required splitting responses into sentences, tracking TTS playback progress per-sentence, and overlaying partial text on the transcript while keeping the full text in state.
Real-time tool visibility: Making the Agent Brain panel feel "alive" — showing tool calls as they happen, tracking progress across 9 claim stages, and handling the visual complexity of 6 agents firing 24 different tools without overwhelming the user.
Accomplishments that we're proud of
- True multimodal experience: Voice in, voice out, live camera vision, AI-generated images — all in one seamless conversation. This isn't a chatbot with extras; it's a fundamentally different interaction paradigm.
- 6 distinct agent personas: Each specialist has their own personality, expertise, and natural-sounding voice. Maya sounds different from Alex, and they both behave differently based on their domain expertise.
- 3-layer deepfake detection: In an era where anyone can generate fake damage photos with AI, we built content provenance verification (C2PA), AI-generated image detection, and media authenticity scoring — all running automatically in the background.
- 13 battle-tested scenarios: We didn't just build a demo — we built 13 comprehensive test scenarios covering the most complex claim disputes in US insurance, from hurricane-tornado combos to suspected deepfake fraud attempts.
- Real-time observability: The Agent Brain panel lets you watch the AI think — every tool call, every agent transfer, every progress update visible in real time. It's both a demo feature and a trust-building mechanism.
- Infrastructure-as-code: Full Terraform deployment — Cloud Run, Firestore, Artifact Registry, Cloud Storage — all reproducible from the repo.
What we learned
- ADK is remarkably capable for multi-agent orchestration. Defining agents with sub_agents, tool routing, and transfer logic was intuitive. The runner handles the complexity of agent-to-agent communication behind the scenes.
- Voice-first UX requires fundamentally different thinking. Text chatbots can dump walls of text. Voice agents need to be concise, paced, and interruptible. We redesigned agent prompts multiple times to make responses feel natural when spoken aloud.
- Fraud detection is an arms race. Single-layer detection is trivially bypassed. Stacking multiple verification methods (visual analysis + metadata + provenance + financial) makes the system far more robust.
- Google Cloud TTS Journey voices are shockingly natural. The jump from browser SpeechSynthesis to Cloud TTS was transformative — it made the agents feel like real people rather than robots.
- Real-time WebSocket architectures need careful state management. Coordinating audio capture, video frames, agent responses, tool calls, and UI state across a persistent WebSocket connection — while handling disconnections and race conditions — was the hardest engineering challenge.
What's next for ClaimSight
- Gemini Live API integration: We have the WebSocket infrastructure ready for full bidirectional audio streaming. Moving from browser STT → Cloud TTS to native Gemini Live would reduce latency and enable true real-time voice conversation.
- Persistent claims database: Replace in-memory storage with Firestore for claim history, document management, and cross-session context.
- Adjuster dashboard: A companion interface for human adjusters to review AI-generated briefs, annotated photos, and fraud risk scores before making final decisions.
- Mobile-native experience: React Native app with native camera integration for on-site damage documentation.
- Multi-language support: Leverage Cloud TTS's language capabilities to serve non-English-speaking policyholders.
- Integration with actual insurance systems: Connect to industry-standard platforms (Guidewire, Duck Creek) for end-to-end claim processing.
Built With
- docker
- fastapi
- firestore
- gemini-2.5-flash
- gemini-image-generation
- google-adk
- google-cloud
- google-cloud-artifact-registry
- google-cloud-run
- google-cloud-text-to-speech
- plaid-api
- python
- react
- tailwind-css
- terraform
- typescript
- vite
- web-speech-api
- websocket


Log in or sign up for Devpost to join the conversation.