-
-
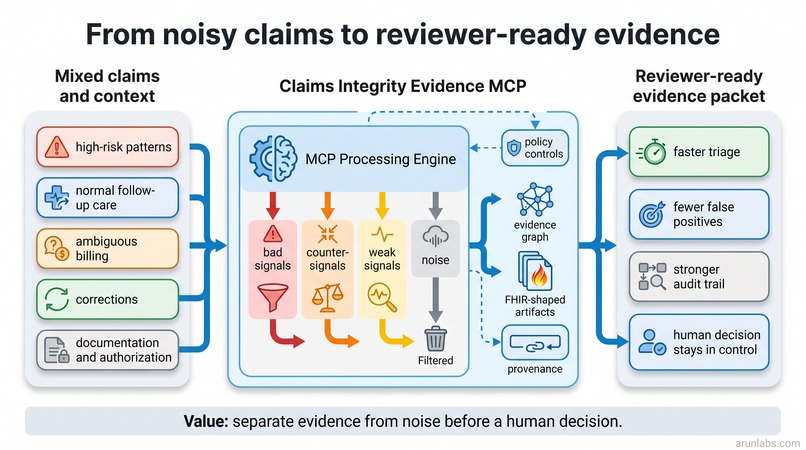
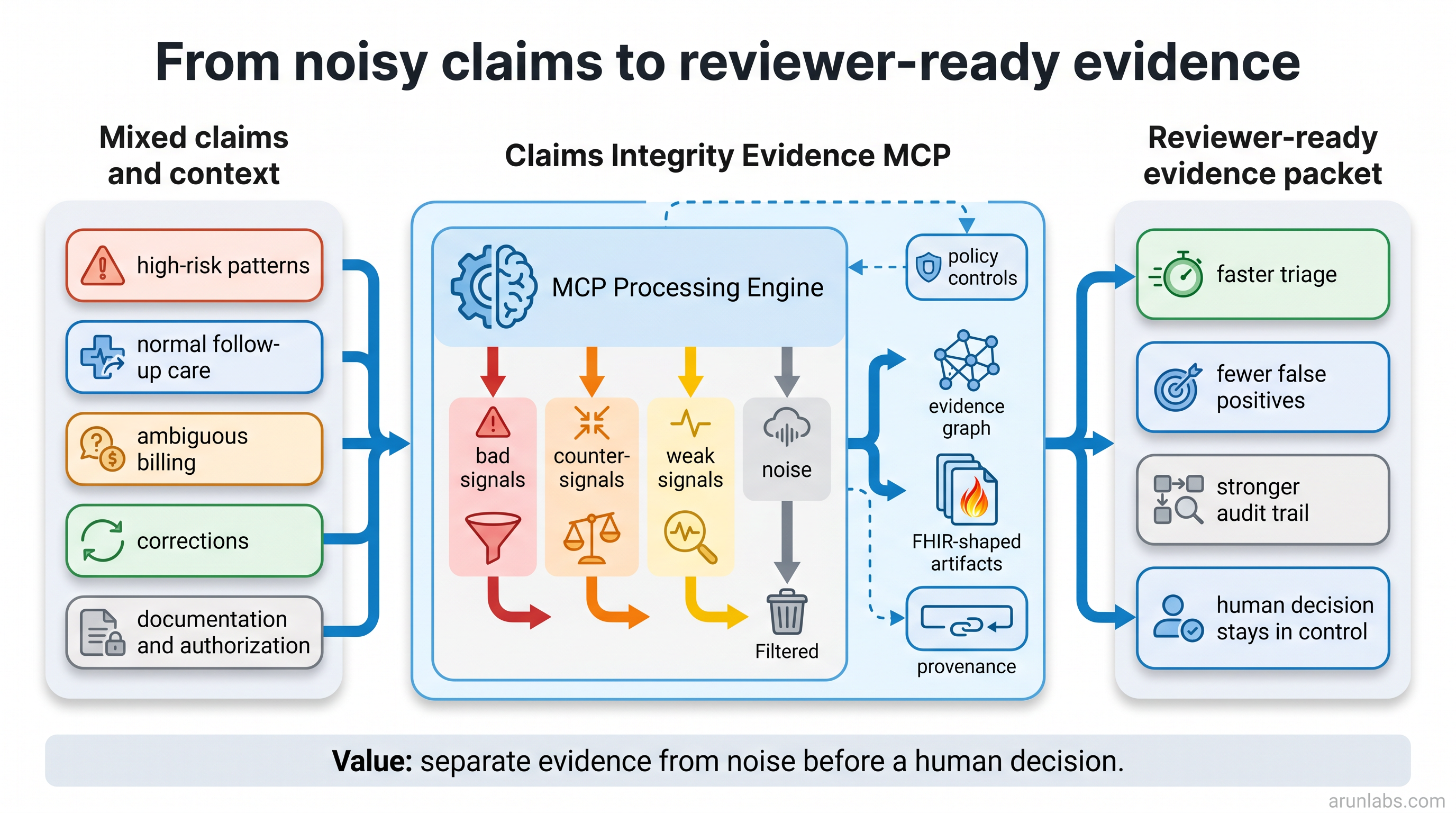
Solution Architecture
-
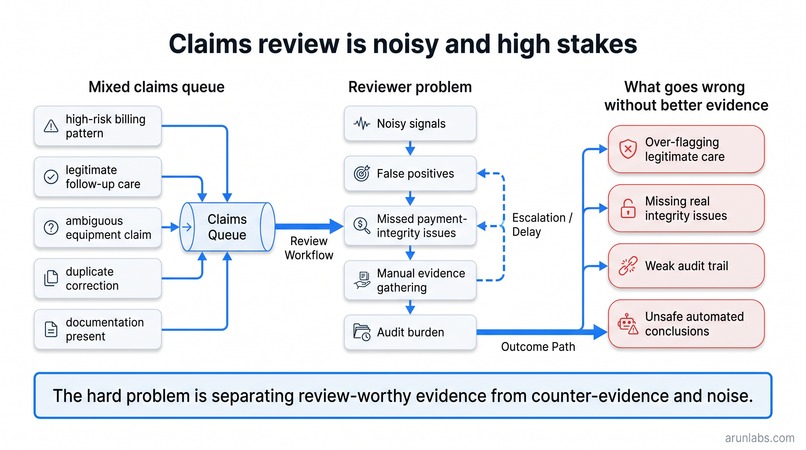
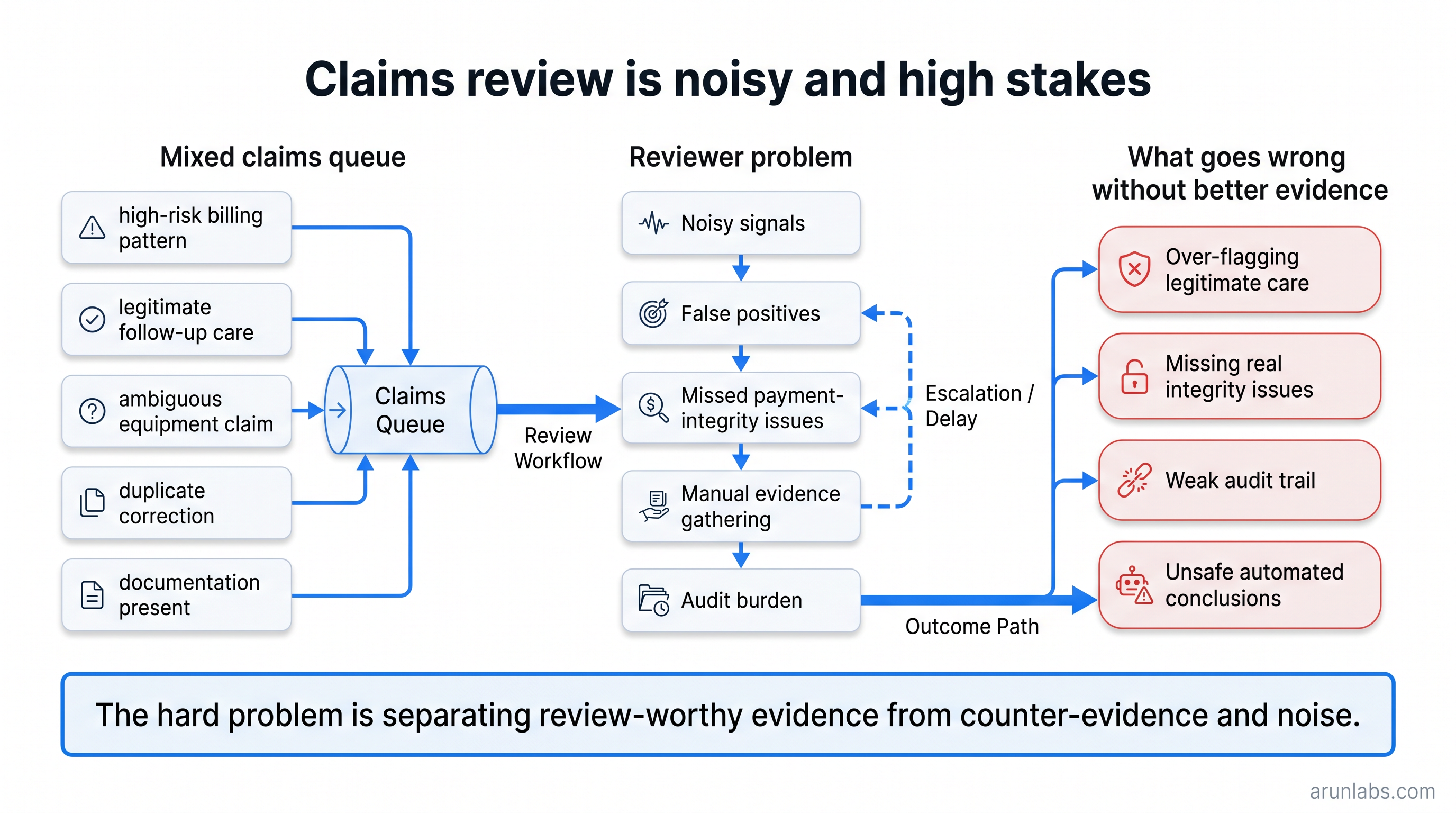
Problem Statement
Inspiration
Claims review is noisy and high-stakes. A reviewer may see a high-risk billing pattern, a legitimate follow-up visit, an ambiguous equipment claim, and a corrected duplicate all in the same queue. The hard problem is not just finding risk. It is explaining why a case deserves review without over-flagging legitimate care or producing a weak audit trail.
What it does
Claims Integrity Evidence MCP is a payment-integrity evidence engine running inside Prompt Opinion. In the demo, a reviewer selects a patient, opens the General Chat Agent, consults the connected Claims Integrity Reviewer, and uses one natural prompt to get:
- claim integrity risk score and risk band
- scenario or case type
- queue/routing decision
- top evidence and counter-signals
- FHIR-shaped RiskAssessment, AuditEvent, and Provenance outputs
- investigator-safe language that keeps the final decision with a human reviewer
The system separates bad payment-integrity signals, good counter-signals, weak signals, and context noise. That matters because a mixed case should not be treated the same as a clean low-risk case or a clearly suspicious pattern.
How we built it
The project uses a Python Streamable HTTP MCP server with deterministic synthetic scenarios, policy controls, signal scoring, FHIR-shaped artifacts, and a chat-safe summary path. The MCP is deployed behind a public HTTPS endpoint and connected to a Prompt Opinion workspace agent named Claims Integrity Reviewer.
Prompt Opinion patient context is used to route the reviewer to the right synthetic case. The same prompt works across the demo patients: Nina Patel returns low risk, Avery Stone returns high risk, and the mixed cases route to documentation review instead of automatic escalation.
Challenges we ran into
The biggest challenge was avoiding overclaiming. A claims integrity tool can easily sound like it is making a fraud finding or payment decision. We designed the output to avoid that: no fraud label, no denial recommendation, no recoupment recommendation, and every signal includes caveats and a reviewer step.
Another challenge was platform-native context. The MCP needed to work from Prompt Opinion agent chat, not just from curl or a standalone test. We added FHIR context support, safe request logging, and patient-context routing so the connected agent can choose the right tool without the demo prompt naming the MCP directly.
Accomplishments that we're proud of
- A live Prompt Opinion agent workflow with a connected MCP protocol server
- One prompt that works across five selected demo patients
- Distinct risk outputs: low, medium, and high cases route differently
- Twelve MCP tools covering risk scoring, evidence graphs, queue ranking, policy controls, FHIR artifacts, provenance, audit events, and investigator briefs
- Safety-first language that supports human review without making fraud or payment determinations
What we learned
Useful healthcare AI needs restraint. In claims review, value comes from showing the reviewer what is risky, what lowers concern, what is weak, and what is just noise. The best demo is not the one that escalates everything. It is the one that can say: this looks high risk, this is ambiguous, and this one should stay in routine monitoring.
What's next for Claims Integrity Evidence MCP
Next steps are to expand the synthetic scenario library, add richer document evidence extraction, strengthen benchmark coverage, and make the reviewer workflow easier to audit across more patient and group contexts.
Safety boundary
This is an independent hackathon prototype. It uses synthetic demo data only. It does not use PHI, live claims feeds, internal systems, or non-public data. It supports human claims integrity review; it does not make automated fraud, denial, or recoupment decisions.
Built With
- devpost
- fhir
- github
- kubernetes
- mcp
- prompt-opinion
- python
- synthetic-healthcare-data

Log in or sign up for Devpost to join the conversation.