-
-
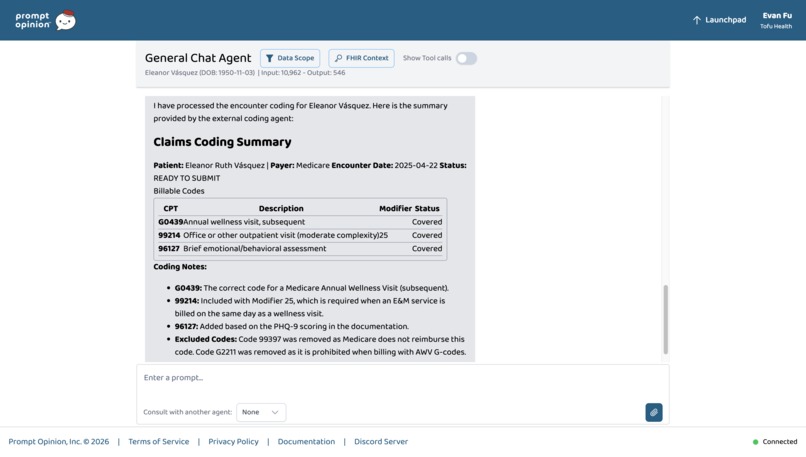
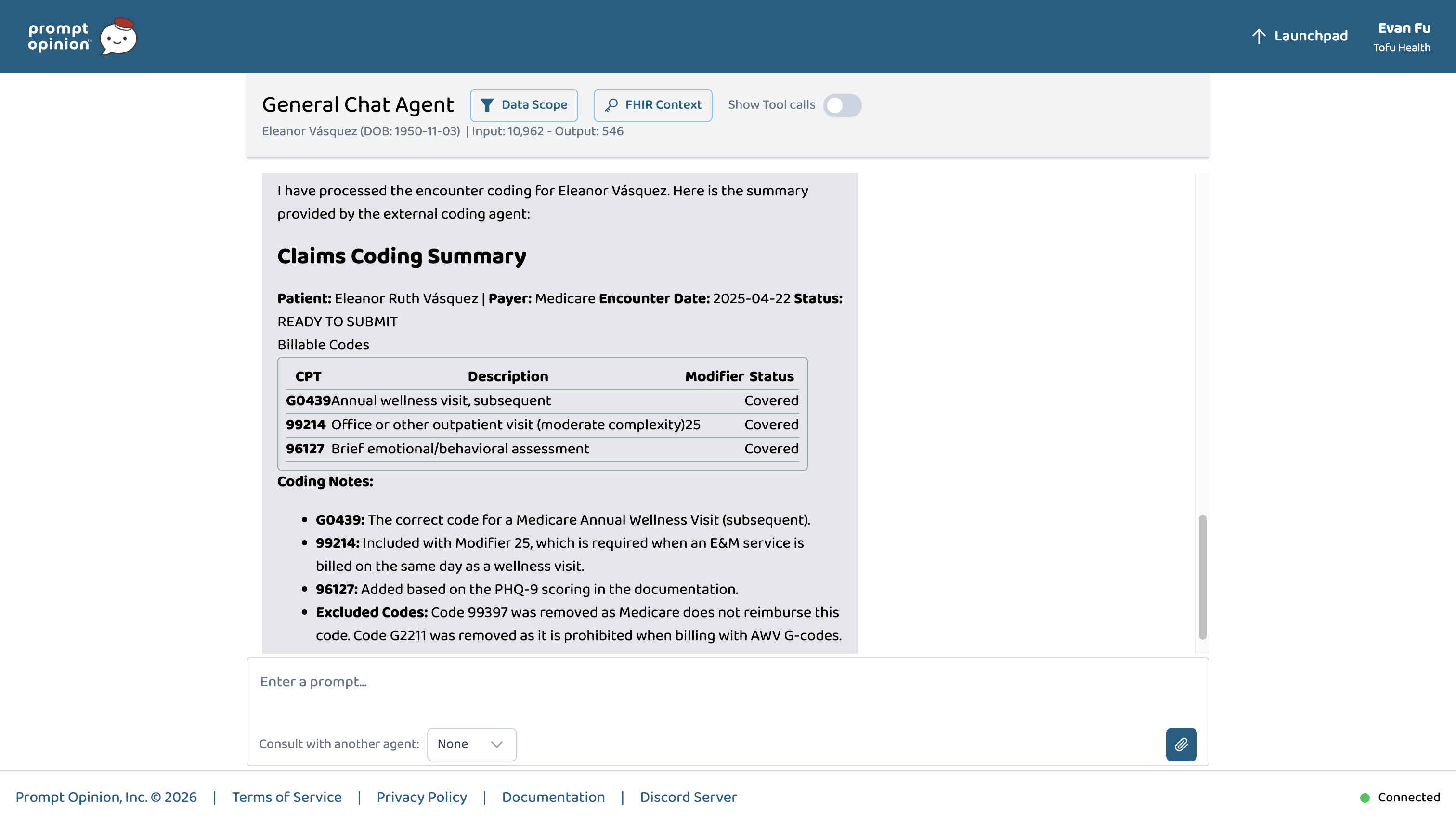
Patient encounter coded live in the Prompt Opinion platform
-
150/150 pass rate across 6 cases, zero flakes
Inspiration
Medical billing errors cost the US healthcare system over $125 billion annually. Most happen at the coding step: a wrong code submitted to Medicare, a missing modifier that causes a claim to deny, an excluded add-on that creates a compliance risk, a documented service that never gets billed. These aren't edge cases. They're the daily reality of medical billing, and they cost practices real money on every patient encounter.
I wanted to build an agent that could catch these errors automatically. Not as a rule-based lookup table, but as a reasoning system that reads live clinical documentation, understands payer-specific policy, and produces a traceable audit log with a CMS citation for every decision.
What it does
Given a patient ID, the Claims AI Agent:
- Retrieves the patient's live FHIR R4 clinical record — conditions, medications, observations, and clinical notes
- Assigns CPT procedure codes based on documented services
- Checks every code against a structured CMS rules database and payer-specific policy PDFs via a hybrid RAG pipeline
- Detects billing errors in submitted claims: wrong codes, missing modifiers, excluded add-ons, omitted procedures
- Produces a structured audit log with clinical evidence and CMS citations for every coding decision
How we built it
Agent layer — Google ADK orchestrating Gemini 2.5 Flash with thinking_budget=0 for latency. The agent follows a structured eight-step workflow from demographics retrieval through audit log generation.
Rules layer — A TypeScript MCP server exposing a structured CMS rules database (cms_rules.json, v1.1.0, 19 codes) with per-code eligibility, modifiers, denial triggers, and hard stops.
RAG layer — A Chroma vector store of payer-specific policy PDFs, enabling the agent to cite specific source documents for payer rules beyond the CMS baseline.
Evaluation — A custom chaos testing framework runs the full golden case suite across multiple iterations with configurable sleep intervals to stay under Gemini API rate limits. Retry logic handles transient upstream failures automatically.
Challenges we ran into
Rate limiting at scale — Gemini 2.5 Flash hits sustained RPM ceilings during chaos testing. Fixed by tuning sleep intervals and adding automatic retry logic for upstream 503s.
Session accumulation — The ADK runner accumulated sessions without a custom contextId strategy, causing state bleed between eval runs. Fixed with a custom Runner using InMemorySessionService and per-request context IDs.
FHIR data heterogeneity — Real FHIR bundles have inconsistent resource structures. The tool layer normalizes across resource types and falls back to clinical note text when discrete resources are absent.
Wrong-code correction — The hardest eval case required the agent to reconcile a submitted claim against a clinical note, identify four simultaneous errors, and produce corrections with CMS citations for each.
Accomplishments that we're proud of
$$F_1 = \frac{2 \cdot \text{Precision} \cdot \text{Recall}}{\text{Precision} + \text{Recall}} = 1.000$$
| Metric | Value |
|---|---|
| F1 Score (all cases) | 1.000 |
| Pass rate (chaos testing) | 150/150 (100%) |
| Independent runs | 2 |
| Transient failures recovered | 5 |
| Logic failures | 0 |
| Cases | 6 |
Cases span Medicare AWV, preventive medicine, pediatric well-child, chronic care, asthma, and wrong-code correction across Medicare Part B and commercial payers.
What we learned
Building a reliable medical coding agent is less about the LLM and more about the scaffolding around it. The agent's accuracy comes from the structured CMS rules layer, the FHIR data normalization, and the evaluation framework that catches regressions immediately. Without chaos testing, the session accumulation bug and the rate limiting cliff would have gone undetected until demo day.
What's next for Claims AI Agent
- Expanded CMS rules coverage — The current MCP server covers 19 codes. A production system needs hundreds, including ICD-10 diagnosis codes, HCPCS Level II codes, and specialty-specific modifiers.
- Payer PDF ingestion pipeline — The RAG layer is built but sparsely populated. Automating ingestion of payer policy PDFs would enable truly payer-specific denial prediction.
- Denial appeal generation — When a hard stop fires, the agent could automatically draft an appeal letter citing the same CMS evidence used to flag the error.
- Broader encounter coverage — Current golden cases cover 6 encounter types. Expanding to surgical, emergency, and specialist encounters would make the agent viable across a full revenue cycle.
Built With
- a2a-protocol
- chroma
- fastapi
- fhir-r4
- gemini-2.5-flash
- google-adk
- mcp-(model-context-protocol)
- ngrok
- prompt-opinion-sharp-extension
- python
- typescript
- uvicorn

Log in or sign up for Devpost to join the conversation.