-
-
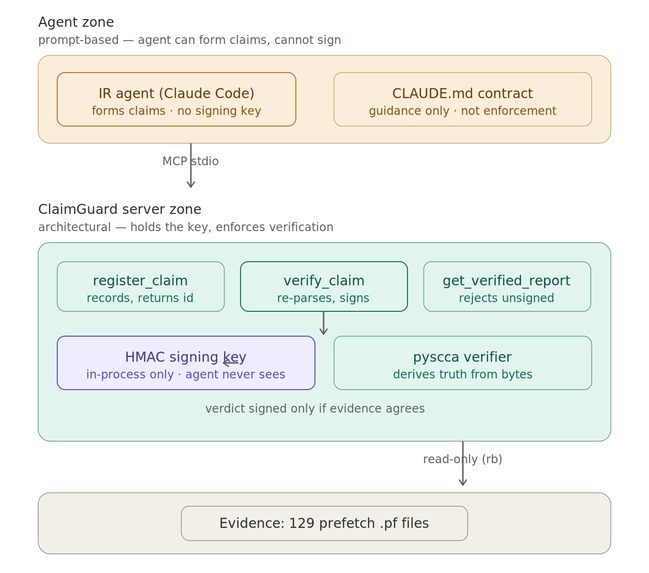
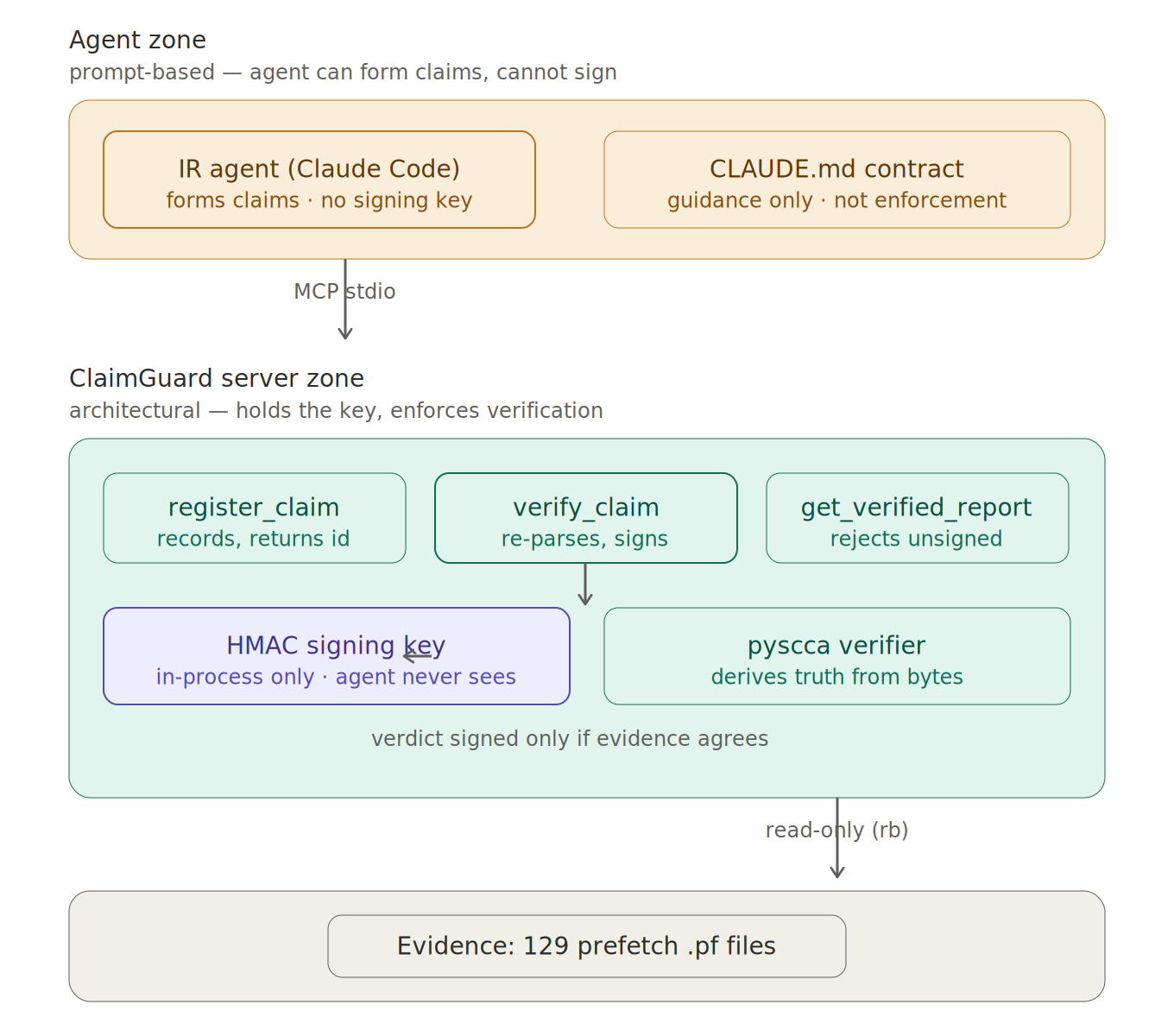
Architecture
Inspiration
In November 2025, Anthropic disclosed GTG-1002: a state-sponsored operation that drove Claude Code through reconnaissance, exploitation, and lateral movement at 80–90% autonomy, at request rates a human couldn't match. The offensive side already moves at machine speed. The defensive side — Protocol SIFT on the SANS SIFT Workstation — can match that speed, but it has one disqualifying problem for forensic work: it hallucinates. A run count that's confidently wrong. A timestamp three years off. A binary that was never executed.
In incident response, a confident wrong answer is worse than no answer. A finding that can't be traced to evidence isn't admissible, isn't actionable, and erodes trust in every other finding the agent produced. We didn't want to make the agent "hallucinate less" through better prompting — prompting is a request, not a guarantee. We wanted to make it structurally unable to report anything it can't prove.
What it does
ClaimGuard is a Model Context Protocol (MCP) server that sits between an IR agent and its conclusions. The agent may form claims freely. It may not publish them freely. Every factual claim about the evidence must pass through three tools:
register_claim— the agent states a specific, falsifiable claim (e.g. "SVCHOST.EXEwith prefetch hashFE99AE69ran 47 times, last on 2021-09-15 17:49:04 UTC") and receives a claim ID.verify_claim— ClaimGuard independently re-parses the raw evidence withpysccaand checks every claimed field against ground truth. It returns a verdict —verified,contradicted, orinconclusive— cryptographically signed with an HMAC key that lives only inside the server process.get_verified_report— assembles the final report. It validates the signature on every verdict and drops any claim that lacks one. Confirmed findings, contradicted claims, and rejected (unverified) claims are kept in separate sections, so "we checked and it was wrong" is recorded as the finding it is.
The agent never holds the signing key. It cannot forge a verdict, and it cannot get a finding into the report by any path other than verification. The guardrail is architectural, not a sentence in a prompt.
We tested ClaimGuard against base-wkstn-01-c-drive.E01 from the SANS SRL-2018
"Compromised APT Attack Scenarios" evidence set — 129 Windows Prefetch artifacts
extracted from a real workstation image. In the recorded demo, we hand the agent
a confident but wrong belief — that one SVCHOST.EXE instance (prefetch hash
FE99AE69) ran 120 times. The agent registers the claim exactly as stated and
asks ClaimGuard to verify it. ClaimGuard re-parses the raw prefetch file and
contradicts the claim: the executable and hash match, but the real run count is
47, not 120. The agent then self-corrects, re-registering the claim with the
evidence-backed value before continuing. From there it investigates the rest of
the host autonomously, confirming eight executions against their prefetch
artifacts — including an SDELETE + WEVTUTIL pairing it flags as a possible
evidence-destruction signature. The final signed report records nine claims:
eight confirmed, one contradicted. The hallucinated number could not reach the
findings. That is the whole point.
How we built it
Architecture: Custom MCP Server. Of the four supported patterns, we chose the one the hackathon brief itself calls "the most sound" — and the most work. Instead of handing the agent a generic shell, ClaimGuard exposes three typed, read-only functions. The agent physically cannot issue a destructive command through ClaimGuard because ClaimGuard has no such command to issue.
The signing mechanism is the load-bearing wall. A VerdictRecord is signed
with HMAC-SHA256 over the canonical JSON of its contents, using a 32-byte key
generated fresh per server process. get_verified_report recomputes and compares
the signature (via hmac.compare_digest) before admitting any claim. Because the
key is generated inside the server and never crosses the MCP boundary, the agent
process has no access to it. We chose an ephemeral per-process key deliberately:
it means verdicts from one session can't be replayed into another — an
anti-replay property — at the cost of long-term verdict archiving, which we
documented as a conscious tradeoff rather than an oversight.
Verification is genuinely independent. verify_claim does not look at what
the agent did, ran, or reasoned. It opens the evidence fresh, parses it with
pyscca (the Python bindings for libscca, the reference Windows Prefetch parser),
and derives truth from the bytes. If the agent used one tool to form a claim,
ClaimGuard re-derives the answer through a different path. Agreement across
independent derivations is what earns a signature.
Evidence integrity by construction. The verifier contains exactly one
evidence-file operation: a read-only open(path, "rb") used for hashing. A
source-wide search for write modes, deletions, and mutation calls returns zero
matches. We proved this empirically too: SHA-256 of all 129 artifacts is
byte-for-byte identical before and after a full verification run. The original
image was mounted read-only throughout acquisition (ewfmount + ntfs-3g -o ro).
Every verdict also carries the SHA-256 of the specific .pf file it was derived
from, so any finding traces back to an exact artifact on disk.
Stack: Python 3.12, the MCP Python SDK (FastMCP, stdio transport), pyscca
20250915 for prefetch parsing, dataclasses for the schema, pytest for the test
suite. Runs on the SANS SIFT Workstation. The agent layer is Claude Code,
configured with an MCP connection to the ClaimGuard server and a behavioral
contract (CLAUDE.md) that instructs it to route every claim through
verification — guidance that is backed by the architecture, not relied upon as
the enforcement.
Challenges we ran into
Parsing Windows 10 Prefetch on Linux. Windows 10+ Prefetch files use Xpress
Huffman compression, and the pure-Python parser we first reached for could only
decompress it via a Windows-only API call — a dead end on the Linux SIFT
Workstation. We switched to libscca, the C reference implementation (by the
author of the libewf library that powers ewfmount), which ships its own
decompressor and is what professional tooling like Plaso uses. The right tool
turned out to be the credible one.
Dependency hell, honestly. Getting pyscca working on SIFT surfaced PEP 668's
externally-managed-environment block, a conflict between two libscca package
versions, and a venv that initially couldn't see the system-installed bindings.
The resolution — a venv created with --system-site-packages plus apt's
libscca-python3 — is documented step by step in the README so a judge doesn't
repeat the journey.
The evidence wasn't shaped like we assumed. base-wkstn-01-c-drive.E01 is a
volume image, not a full disk image — no partition table, filesystem starts at
byte 0. Our first mount attempts failed against a partition offset that didn't
exist. Reading the actual fls output rather than trusting the assumption fixed
it. A small lesson that is also, fittingly, the entire thesis of the project.
Keeping the two roles separate. The same Claude Code tool builds ClaimGuard
and acts as the IR agent that ClaimGuard constrains. These are different jobs
with contradictory needs — the builder writes code freely, the agent must be
tightly bounded. We separated them by working directory and layered CLAUDE.md
contracts so neither role bled into the other.
What we learned
Prompts request; architecture guarantees. The sharpest lesson was feeling the difference in our own hands. We could have written "never report unverified findings" in the agent's instructions and called it a guardrail. It would have worked most of the time. "Most of the time" is not a security boundary. Moving the enforcement into a signing key the agent can't reach changed the guarantee from behavioral to structural — and that distinction is exactly what separates a constraint that holds under adversarial pressure from one that doesn't.
Absence of evidence is not evidence of absence — and we shipped a bug that got
this wrong. ClaimGuard currently returns contradicted when no prefetch artifact
exists for a claimed executable. That's logically incorrect: Prefetch can be
disabled (Windows Server defaults) or deleted. The correct verdict is
inconclusive. It didn't affect our results because base-wkstn-01 had Prefetch
enabled, but a Server-edition target would expose it. We documented it as a real
failure mode rather than hiding it, and scoped the fix.
Honest scope beats inflated scope. We resisted adding memory analysis, registry parsing, and four more claim types. One evidence source, one claim type, verified end-to-end with a provable trust boundary, demonstrates the architectural idea more convincingly than a broad system that verifies nothing rigorously. Depth on one thing beat breadth across many.
What's next
- Fix the absence-vs-contradiction verdict so missing artifacts return
inconclusivewith a note on Prefetch policy. - A second evidence source for the same host. The schema and signing layer are already source-agnostic; a Volatility-backed memory verifier slots in alongside the prefetch verifier. The high-value direction is cross-source corroboration: the same claim verified against disk and memory independently, with discrepancies (a process in memory with no prefetch on disk, say) flagged as their own finding.
- More claim types — registry persistence, logon events, network IOCs — each a new verifier behind the same three-tool interface.
- An accuracy benchmark. Our demo claims and test cases are designed demonstrations, not a statistical rate. A labeled corpus of true and false claims at scale would turn "caught these hallucinations" into a measured false-positive/false-negative rate the community could track.
- Persistent, access-controlled signing keys for teams that need to archive and re-verify verdicts across sessions.
Built With
- claude
- claude-code
- dfir
- forensics
- mcp
- model-context-protocol
- pyscca
- python
- sift
- windows-prefetch

Log in or sign up for Devpost to join the conversation.