
Inspiration
The hackathon's Governance & Collaboration track explicitly warned about tools that can be "weaponized for manipulation or suppressing dissent" and tools that "both-sides" reality with false balance. We looked at the existing options for sanity-checking a social-media post, Grok in X, screenshot-and-ask AI features built into iOS / Android / Chrome, and noticed all of them have the same shape: a user pastes content, the AI gives a verdict. That tweet is biased. That claim is true. That argument is extreme. The verdict is what users react to and share, and the verdict is exactly what the track is warning against.
We wanted to build the opposite: a tool that helps users think more clearly themselves, instead of one that delivers conclusions.
What it does
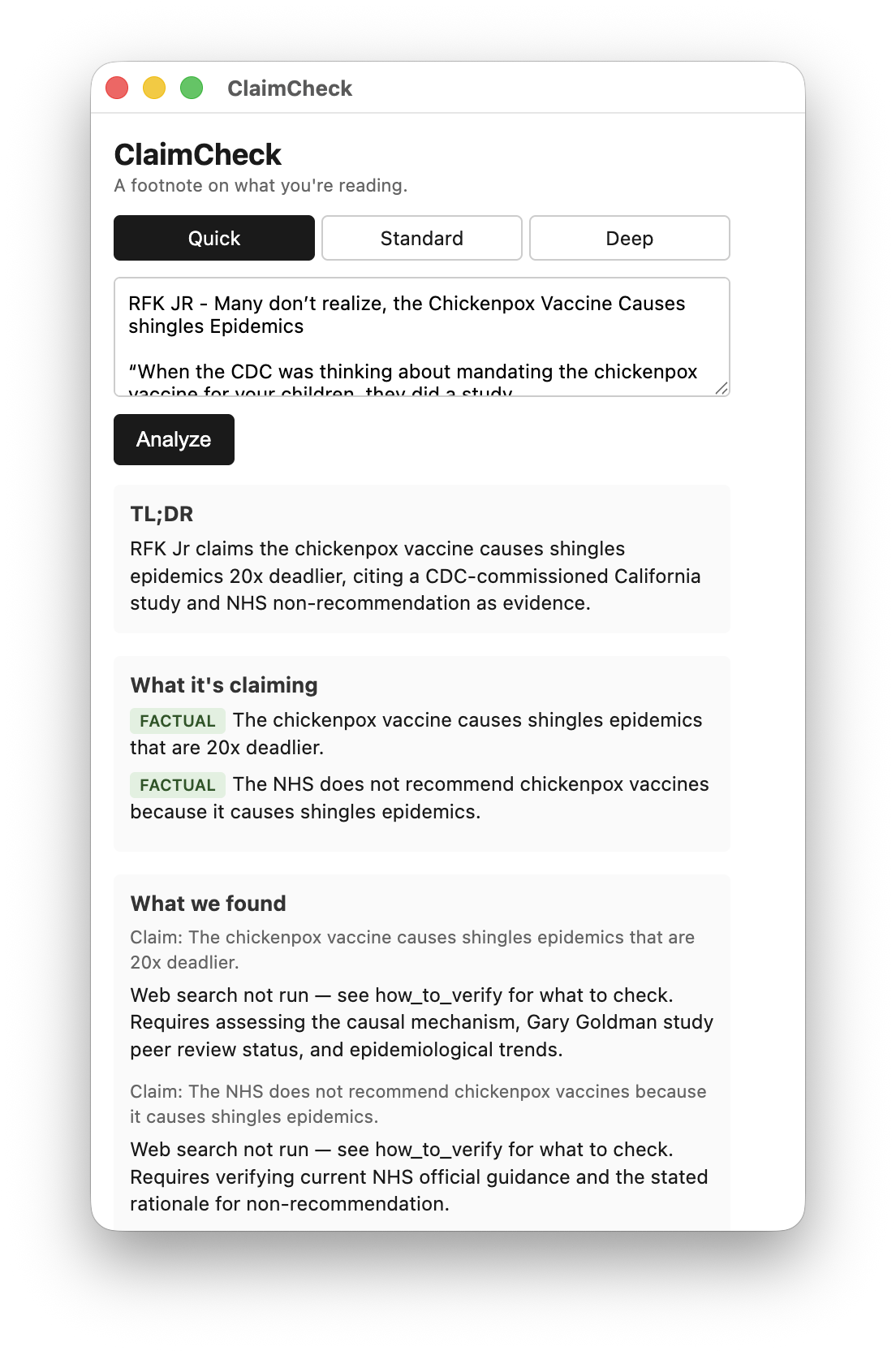
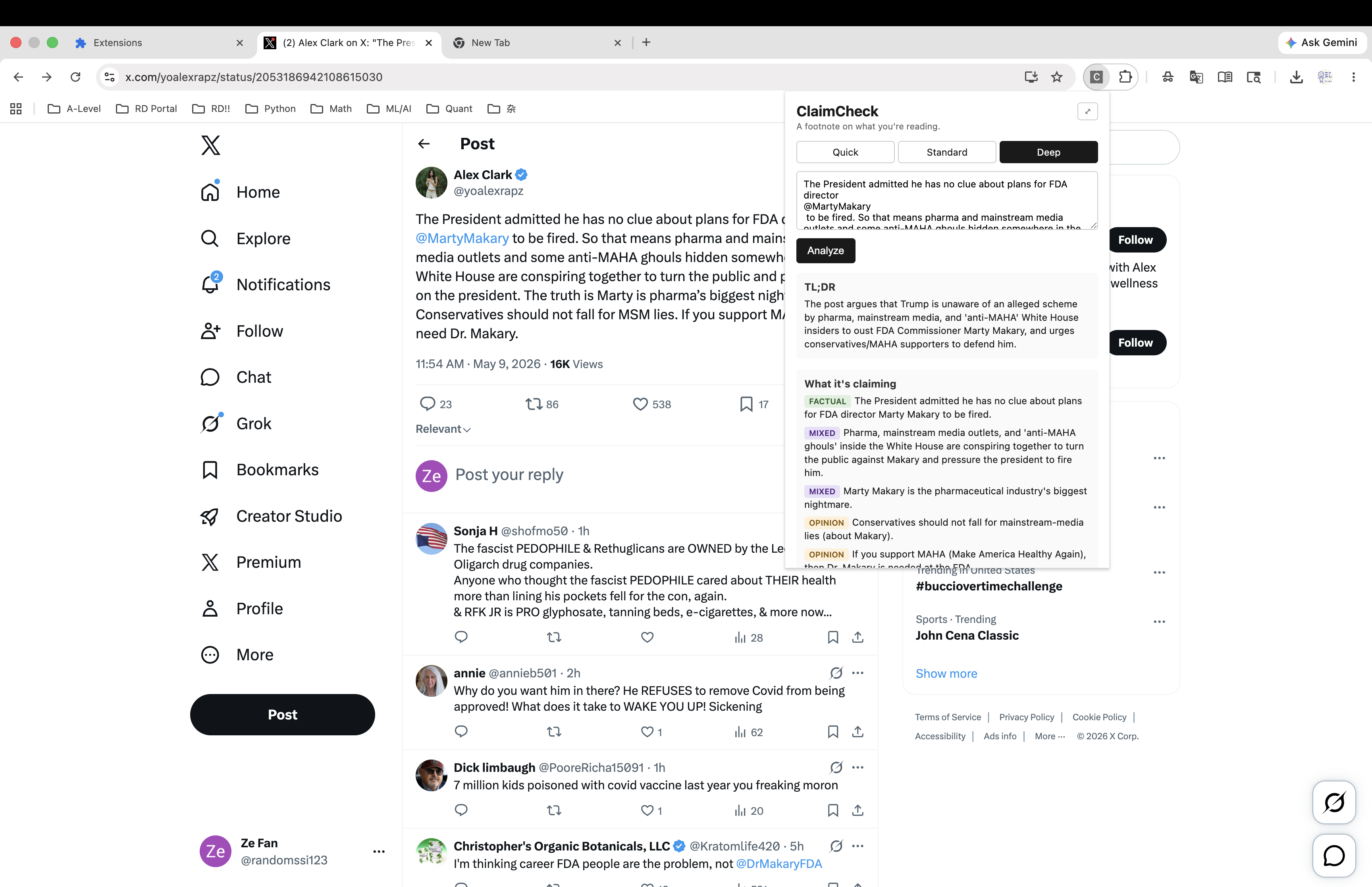
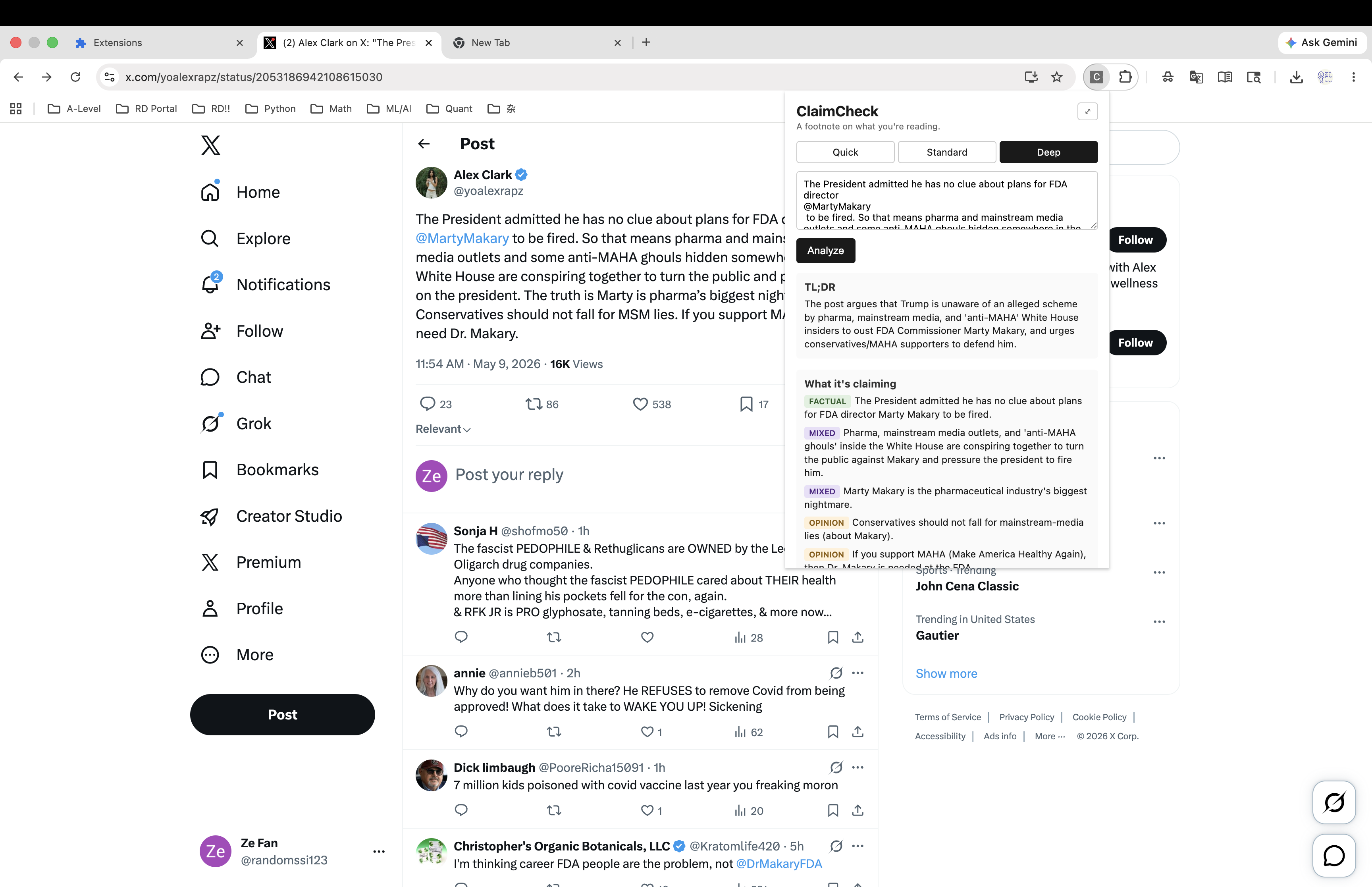
ClaimCheck is a Chrome extension that helps a reader think critically about a social-media post (primarily X/Twitter, but it works on any pasted text — Reddit, news articles, emails). The user pastes the post into the extension popup; a small Node proxy on the user's own machine, authenticated with their Claude Max OAuth, calls Claude and returns six fixed sections:
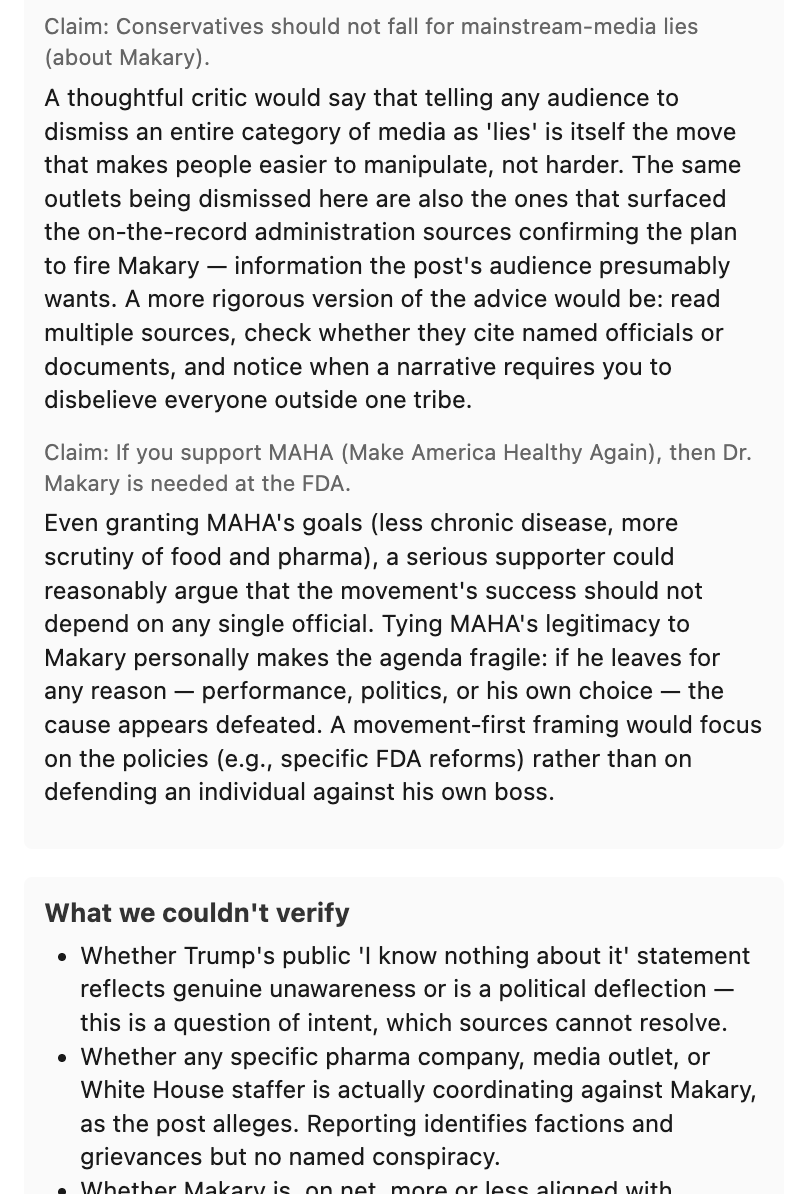
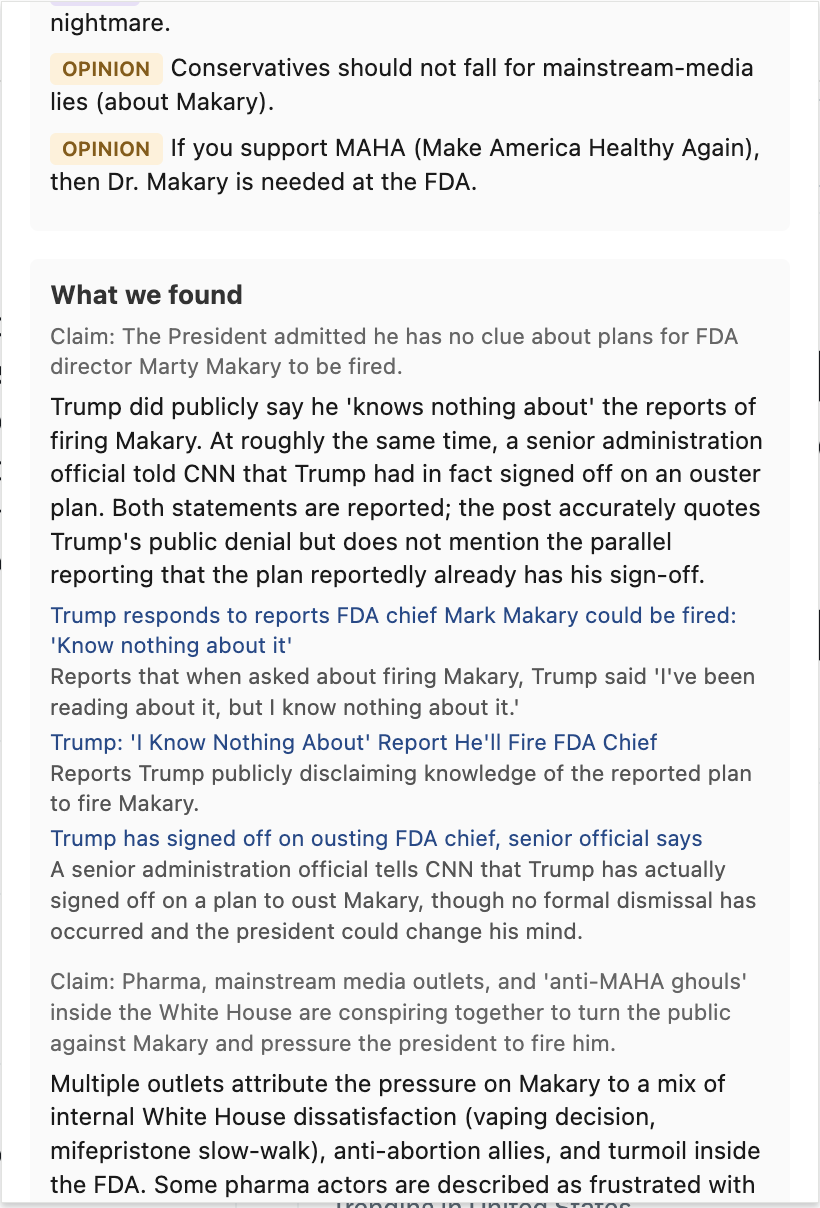
- TL;DR — a neutral one-sentence restatement of what the post is communicating
- What it's claiming — distinct claims tagged
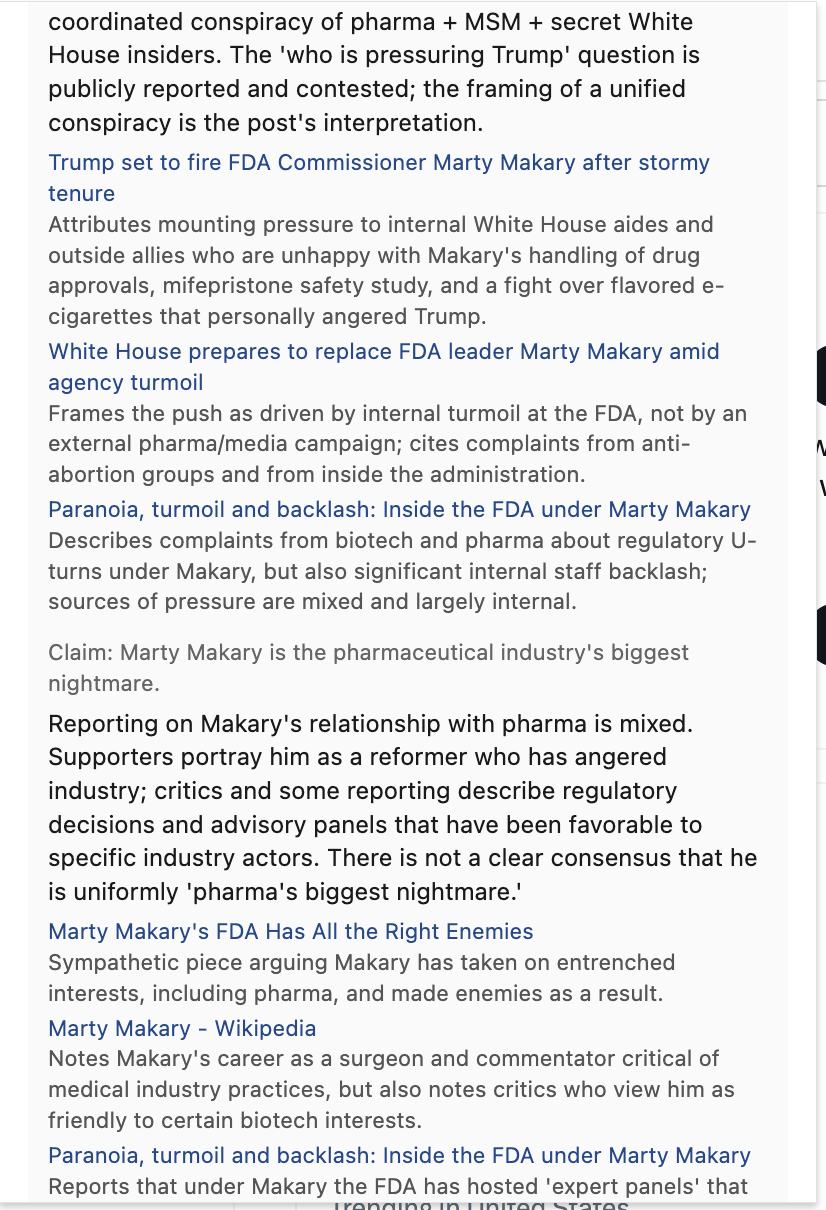
[Factual],[Opinion], or[Mixed] - What we found — evidence with real cited URLs from web search
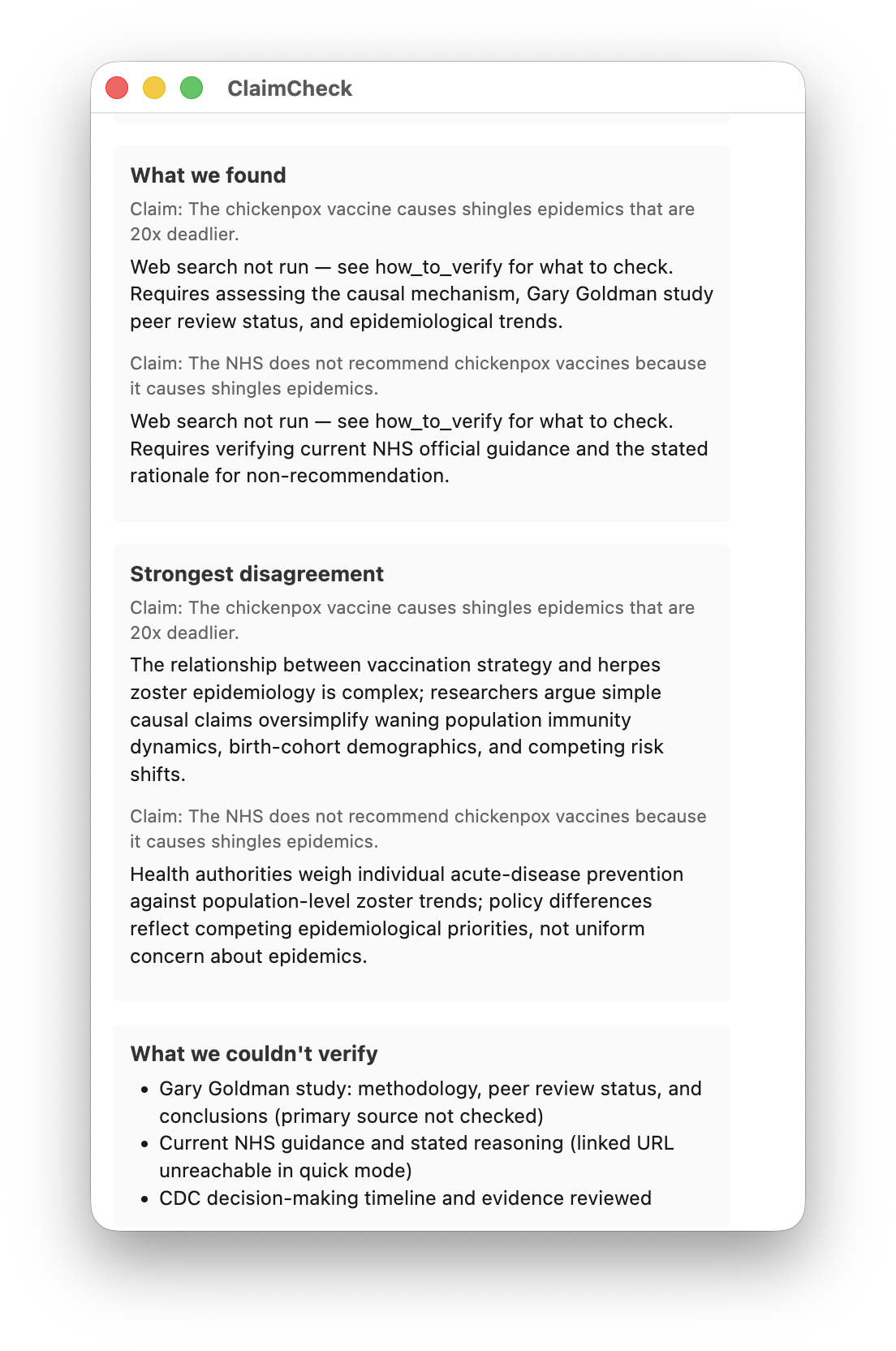
- Strongest disagreement — the steel-manned counter from a thoughtful critic (NOT a partisan rebuttal)
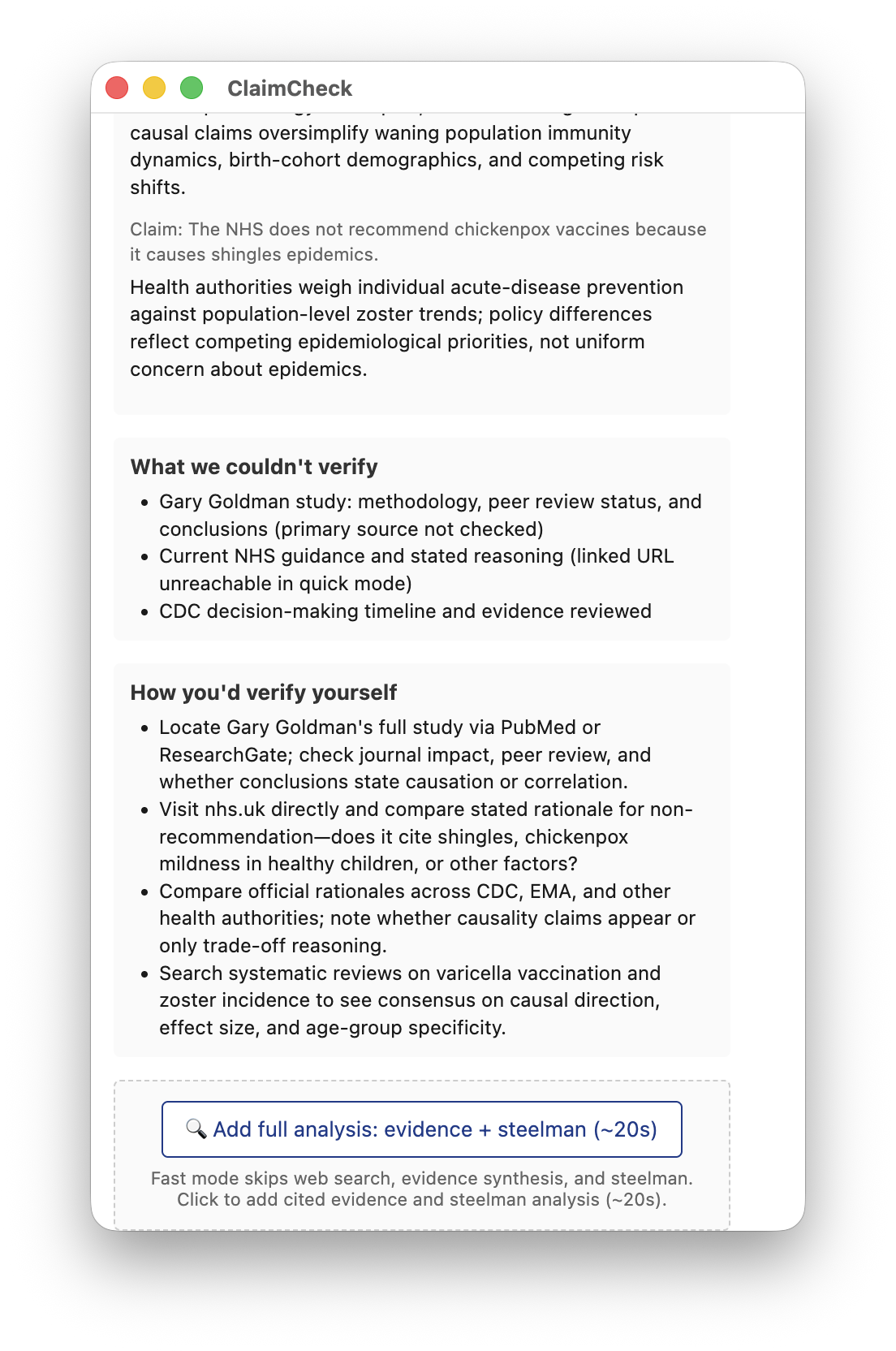
- What we couldn't verify — explicit limitations: paywalls, missing expertise, evidence that's genuinely mixed
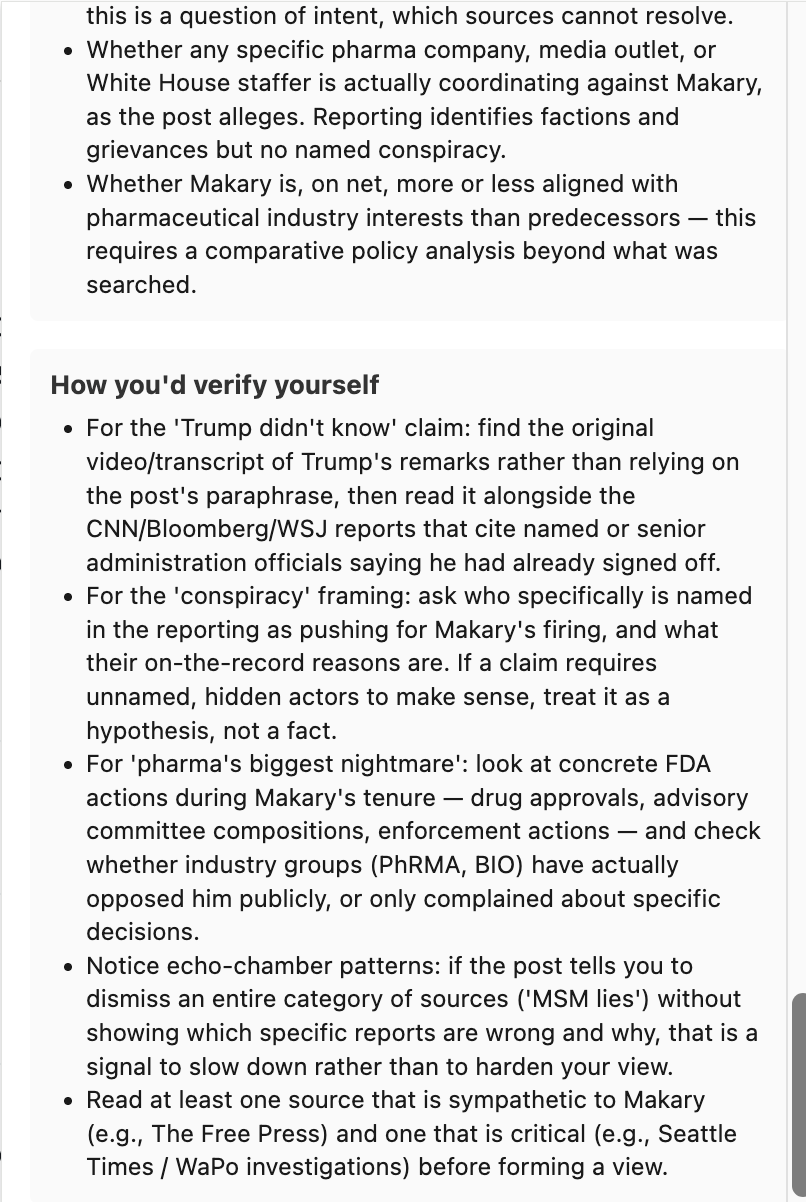
- How you'd verify yourself — concrete strategies the user can apply on their own
The product refuses to render verdicts. No partisan-lean meter. No "extreme content" flag. No "is this true" rating. The job is to expose patterns, not to issue judgments.
It runs in three modes. Quick (Haiku 4.5, no web search, ~10–20s) extracts claims and points the user at how to verify them. Standard (Sonnet 4.6 with web search, ~30–60s, recommended default) returns the full analysis with cited sources. Deep (Opus 4.7 with web search, ~60–90s) is the power-user mode for thorough analysis.
How we built it
- Chrome extension (Manifest V3, vanilla HTML/JS, no framework) with a popup UI, a background service worker, and a segmented control for mode selection
- Local Node proxy on
localhost:3001— no hosted backend, no analytics, no telemetry. The user runs it on their own machine - Claude Agent SDK with
WebSearchtool, authenticated via the user'sclaude login(Max plan OAuth), so OAuth tokens never leave the user's laptop - Mode-aware system prompt —
MODE_CONFIGparameterizes model,maxClaims,maxSources,maxTokens, and which tools are available; one rule (BUDGET) is template-substituted per mode - In-code no-verdict validator —
proxy/validator.jsrecursively strips any field named likepartisan_lean,bias_score,verdict_label,political_lean,is_extreme,truth_score, etc. before the response reaches the extension. Defense-in-depth, not just prose in the prompt - Search-override pattern — Quick mode skips web search by default for speed; the popup shows an opt-in "Add full analysis" button that re-runs with
searchOverride: true - Mode-keyed cache so the same input under different modes returns independent results
- Service-worker fetch persistence with stale-marker recovery and a cancel button so a popup that closes mid-analysis doesn't lose state
We used Claude Code (Opus 4.7) under our direction to write the implementation, with subagent-driven two-stage review on every task (spec compliance, then code quality). We made the design decisions; Claude wrote the code.
Challenges we ran into
- Latency. Initial Quick mode took 60–120 seconds because it was still doing web searches. We had to redesign Quick to be a different product — claim extraction only, no search — to get it under 20 seconds. The Claude Agent SDK adds ~5–6s of session-init overhead per call (loads skills + hooks); we couldn't eliminate it but worked around it with mode-aware token budgets
- WebSearch permissions. The SDK gates tools per call; without
allowedTools: ['WebSearch']the model silently fails to search. Confirmed via Phase 0 spike before parallel work began - MV3 service worker lifecycle. Workers can be killed mid-fetch, leaving stale
inFlightmarkers. Built client-side stale detection (5 min) + an explicit cancel button + an AbortController so the user is never stuck - Tweet URLs. X requires authentication to fetch tweet bodies, so pasting a URL alone usually returns nothing. Added URL-pattern detection in the popup with a hint to paste the text instead
- False-positive auth errors. Our auth-error regex
/auth|.../imatched the substring "auth" in tweets containing words like "authorities", wrapping JSON parse failures as "Authentication failed." Tightened to\bauthentication\b|\bunauthorized\b|...with word boundaries - JSON parse failures. Claude occasionally returned valid JSON followed by trailing prose. Built a robust parser that extracts the first balanced
{...}block instead of trustingJSON.parse(rawText) - Default-mode question. We launched with Quick as the implied "main" mode and quickly realized Standard (with search) is what users actually want — flipped the default and rewrote the tooltips
Accomplishments that we're proud of
- The no-verdict validator that runs in code, not just in the prompt. The design philosophy is enforced even if the LLM slips
- The anti-false-balance rule actually fires in practice. On a tweet claiming "homework has no measurable effect," Claude correctly used
factually_wrong_redirectinstead of fabricating a fake balanced steelman of an overstated claim - Real scholarly sources in evidence — meta-analyses (Cooper 2006, Bas 2017, PMC 2024) with substantive synthesis, not made-up citations
- Privacy by design — no backend, no analytics, no telemetry, no account, no terms of service. The proxy runs on the user's machine; OAuth tokens stay there
- Cross-platform by accident — the popup is just a textarea, so the same tool works for X / Reddit / news articles / emails
- The product shipped a coherent design philosophy rather than a feature list. Every cut feature (partisan-lean bar, "extreme" flag, auto-paired opposite-view articles) was a deliberate alignment choice, not a time constraint
What we learned
- The hardest constraint to design around is what not to build. Refusing to render a verdict was harder than rendering one — most LLM-app instincts pull toward "give the user an answer."
- Subagent-driven two-stage code review (spec compliance, then code quality) caught real bugs that a single-pass review missed. The auth-regex false positive in particular surfaced because a fresh reviewer noticed the pattern matched user-input substrings.
- Different speed/depth needs are different products, not different settings on the same product. Quick mode's value proposition (claim extraction only, opt into search) is genuinely distinct from Standard's (full analysis with sources). Trying to make a single mode "tunable" produced something that was bad at both.
- Claude Agent SDK + Max OAuth is the right path for cost-conscious development (vs. paying per API call), but the SDK's session-init overhead is a real latency floor we had to budget for.
What's next for ClaimCheck
- X thread support — concatenate replies so a multi-post argument can be analyzed as one unit. Threads are usually where the most weaponizable content lives
- Empirical bias audit — take ~30 tweets each from left-coded and right-coded accounts, run them through Standard mode, and check whether evidence-section synthesis tone differs in any systematic way
- "Share this analysis" export that includes the system prompt and the validator's allowed/forbidden-key lists. Concrete support for the track's "transparency in how recommendations are made" criterion
- Image / video understanding for screenshot tweets (out of scope for v1; needs multimodal calls)
- Hosted backend option for users who don't have a Claude Max plan and don't want to run a local proxy. Would need to add API-key entry and rate limits

Log in or sign up for Devpost to join the conversation.