Devpost Submission — Claim-ready
Tagline (max 200 chars)
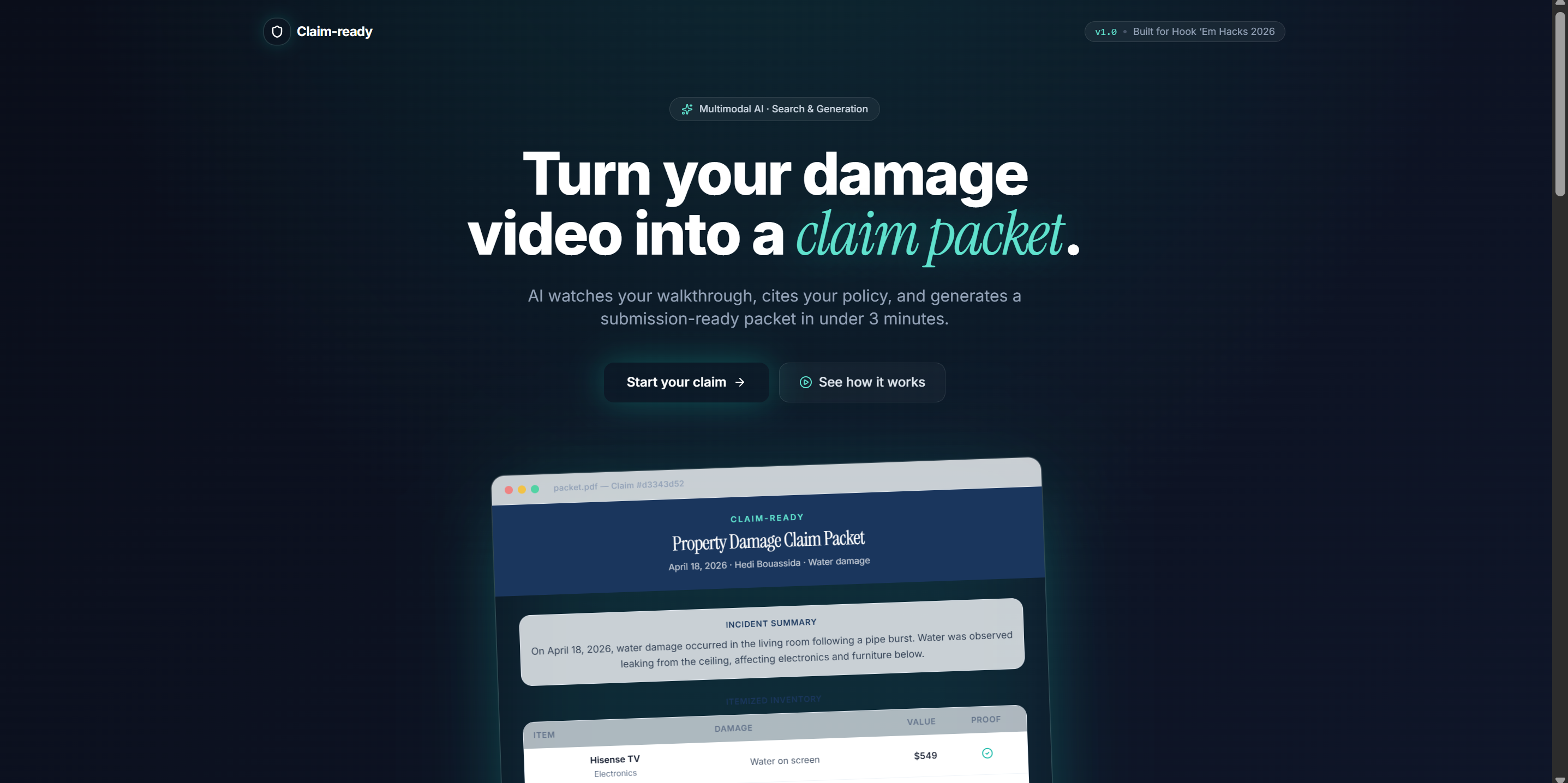
Turn your damage video into a claim packet. AI-generated inventory, policy citations, and FNOL letter — in under 3 minutes.
Project Story (About the project)
Inspiration
73 million Americans had insurance claims denied last year. Less than 1% appealed. The asymmetry is brutal: insurers deploy entire AI stacks to evaluate, adjust, and deny claims, while policyholders show up with a shoebox of receipts and a phone camera.
I wanted to flip the table. If AI can be used to deny claims, it can be used to file them, grounded in the claimant's own evidence, cited to their own policy, ready to send.
Claim-ready is what happens when you give the policyholder the same firepower.
What it does
Upload two things: a narrated video walkthrough of your damaged property, and your insurance policy PDF. Claim-ready returns a structured claim packet containing:
- A de-duplicated inventory of every damaged item, each linked to the exact timestamp in your video where it appears
- Visible-damage descriptions, category, and (user-entered) value per item
- Policy section citations retrieved for each item, so the packet says not just "MacBook damaged" but "MacBook damaged, covered under Coverage C — Personal Property"
- A generated FNOL (First Notice of Loss) letter that references your specific items and your specific policy language
- Everything bundled into a PDF your adjuster can actually read
Click any item in the review UI and the video jumps to the second it was captured. Every claim is grounded in the user's own footage. No hallucinations, no generic boilerplate.
How I built it
Claim-ready is a three-layer multimodal search and generation system.
Ingestion
- Video.
ffmpegextracts frames at 1 fps,imagehashperceptually deduplicates near-identical frames, CLIP (ViT-B/32) embeds each keyframe into a 512-dim vector. - Audio. Groq's Whisper (
whisper-large-v3) transcribes the narration (10× faster than hosted alternatives), chunked into narration segments and embedded with MiniLM (all-MiniLM-L6-v2, 384-dim). - Policy PDF.
pypdfextracts text, split on section headers with a regex fallback to 400-word chunks with 50-word overlap, embedded with MiniLM. Post-extraction filtering drops TOC entries, inventory-form pages, and duplicate sections.
All three embedding sets land in ChromaDB collections tagged by claim_id.
The three search layers
Cross-modal correlation during detection. I window the video into 10-second segments with 2-second overlap, align each segment's narration with its keyframes, and feed both (images + aligned narration text) to Gemini 2.5 Flash in a single prompt. Gemini correlates what's said with what's shown to emit structured JSON inventory items. This is where cross-modal understanding happens.
Video evidence retrieval. Every inventory item stores references to the CLIP-embedded frames and MiniLM-embedded narration chunks that produced it. Click-to-timestamp works because the search layer is the citation layer.
Policy RAG. For each detected item I build a query like
f"{item.category} damage: {item.name}. {item.damage_observed}"and retrieve the top-k policy sections by cosine similarity. Those become the citations on the packet.
Generation
Gemini writes the incident summary and FNOL letter with the detected inventory and retrieved policy sections in context. Jinja2 renders the packet HTML, Playwright (headless Chromium) turns it into a styled PDF.
Stack summary
- Backend: Python 3.11, FastAPI, ChromaDB,
sentence-transformers,open-clip-torch, Groq,google-genai, Playwright - Frontend: Next.js 14 (App Router), TypeScript, Tailwind, shadcn/ui, scaffolded in Cursor
- Infra: Frontend deployed to Vercel, backend runs locally for the multi-GB model stack
Challenges I ran into
Gemini hallucinating items not in the video. Early prompts let Gemini invent a "broken vase" because the narrator mentioned vases elsewhere. Fix: a hard constraint in the prompt ("If you cannot see an item in the images, do not include it even if mentioned in narration") plus shorter detection windows. Shorter segments = less room to hallucinate.
Items duplicating across overlapping windows. The same laptop showing up in three adjacent windows became three laptops. I shipped a multi-layer dedup: exact name match → substring match → brand-token match (two items merge if they share "Lenovo" or "Hisense" in their names) → SequenceMatcher ratio ≥ 0.7 within an 8-second temporal window. Plus an accessory-blocker that prevents "Hisense TV" from swallowing "Hisense Remote" since both share the brand token but represent physically distinct objects.
Policy RAG returning nonsensical sections. The first version retrieved header boilerplate for every query. Fix: two things. (1) Better chunking that respects real section boundaries like "Section 02 — What Your Renters' Policy Covers," plus aggressive filtering of TOC pages and inventory form templates. (2) Richer query strings that include the damage and the category, not just the item name.
Silent Playwright deadlock on Windows. At hour 10, the pipeline started hanging at "rendering PDF" with zero error output. Backend alive, 0% CPU, no Chromium child process. Spent 30 minutes chasing an asyncio + threadpool theory. Turned out the actual cause was a ModuleNotFoundError: No module named 'playwright' — the package was in requirements.txt but never actually installed in the venv. The exception was being swallowed by the background task's bare except Exception, which only stored str(e) in progress state. An hour of silent deadlock was really a swallowed import error. Lesson: always log tracebacks where you can see them.
Gemini tier gotcha. Enabling billing in Google Cloud Console doesn't auto-upgrade your API key's tier. There's a separate step in AI Studio. I burned 90 minutes on rate-limit debugging before figuring this out. Documented in the README so the next person doesn't.
Scope, with no one to split it with. Every hour spent on the frontend was an hour not spent on the pipeline. I set a hard rule up front: if the backend wasn't working end-to-end by hour 11, I would not start the frontend and would fall back to a Swagger UI plus recorded walkthrough demo. That rule saved me from myself more than once.
Accomplishments I'm proud of
- Real multimodal search, not a bolt-on. The video evidence retrieval isn't a demo feature. It's how the inventory gets built in the first place. Remove the CLIP + MiniLM + Gemini Vision layers and the product stops working.
- Every claim is verifiable. Click any line item in the packet, jump to the exact timestamp in the source video. Every policy citation links back to the exact section. Nothing is generated out of thin air.
- Human-in-the-loop by design. The product doesn't pretend to be perfect. The AI proposes candidates; the user verifies, edits values, and marks which items have receipts. The packet separates verified totals from unverified totals — a credibility signal for the adjuster. This is an explicit anti-fraud stance, not a bug.
- The PDF looks like something an adjuster would actually read. Clean typography, real tables, proper section hierarchy, thumbnails pulled from the middle of each item's timeline so they're representative.
- I shipped, solo. Full pipeline (video ingest, policy ingest, detection, RAG, generation, frontend) working end-to-end in a weekend, one person.
What I learned
- Multimodal doesn't mean throwing everything at one model. It means orchestrating specialized models (Whisper for audio, CLIP for images, MiniLM for text, Gemini for cross-modal reasoning) and letting each do what it's good at.
- Prompt engineering is the product. The
detect_inventoryprompt is 40+ lines and every line matters. When output quality was bad, the answer was almost always in that prompt, not in the model choice. - RAG quality is chunking quality. I burned an hour debugging retrieval before realizing the real problem was that my policy chunks started mid-sentence and included table-of-contents entries.
- Constraints are features. The 16-hour clock, the single-developer constraint, the fact that heavy ML dependencies don't fit serverless: all of it forced me toward simpler architectures that ended up being the right call.
- Locked data contracts let one person move fast. The dataclasses for
KeyFrame,NarrationChunk,PolicySection,InventoryItem, andClaimPacketwere the first thing I wrote. Every module after that was just "read this shape, return that shape." No integration surprises at hour 10.
What's next for Claim-ready
- Voice intake. An ElevenLabs-powered conversational agent that walks the claimant through the video recording live, prompting them to capture angles, serial numbers, and proof-of-ownership documents. Eliminates the "I forgot to narrate the bedroom" failure mode.
- Adjuster-side dashboard. A view for insurance adjusters to receive, review, and respond to Claim-ready packets, making life easier on both sides of the table.
- Proof-of-ownership matching. Users upload receipts, warranties, or original packaging photos. The system matches them to detected items automatically and attaches them to the packet.
- Policy diff-and-explain. Upload your renewal policy alongside last year's; Claim-ready flags the coverage that quietly changed.
- Beyond homeowner's and renters' insurance. Auto, small business, health. The pipeline is general-purpose; only the prompts and policy schemas need to adapt.
The insurance industry spent billions giving AI to the adjusters. I just gave it to the other side.
Built With (tags)
python, fastapi, next.js, react, typescript, tailwindcss, gemini, google-ai-studio, groq, whisper, clip, sentence-transformers, minilm, chromadb, playwright, jinja, ffmpeg, pypdf, imagehash, pydantic, uvicorn, shadcn-ui, lucide-react, vercel
"Try it out" links
- Live landing page: https://claim-ready-hookem.vercel.app
- Demo video: https://www.youtube.com/watch?v=z7nNDC8BowQ
- GitHub repo: https://github.com/peroute/claim-ready
Tracks / Bounties
- Multimodal Search & Generation (main track)
- Best Use of Gemini API (bounty)

Log in or sign up for Devpost to join the conversation.