-
-
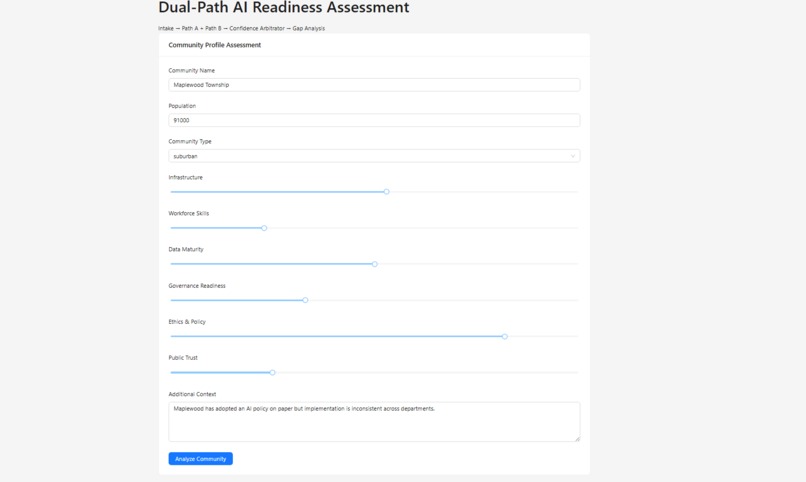
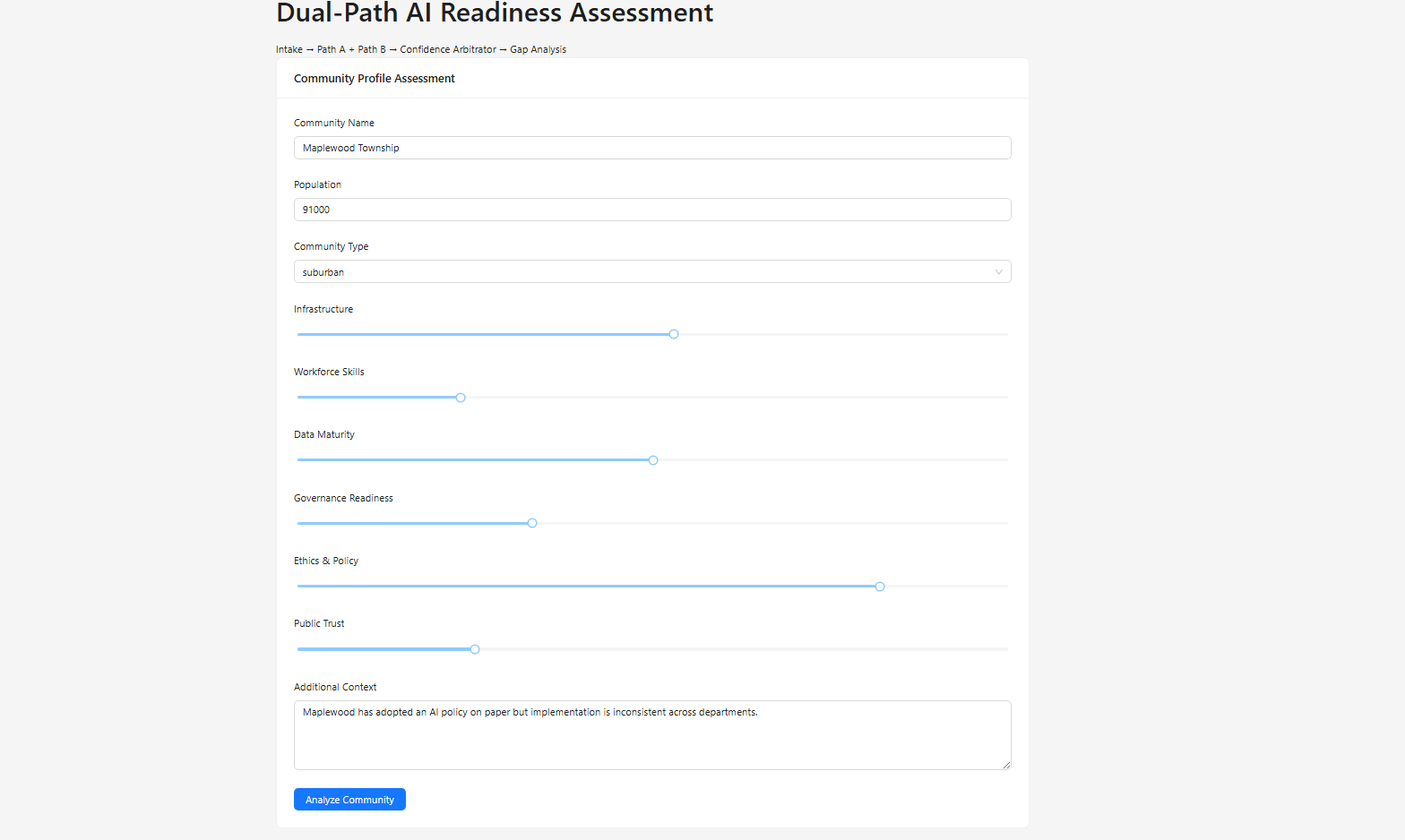
Community Profile Intake structured assessment across 6 AI readiness dimensions
-
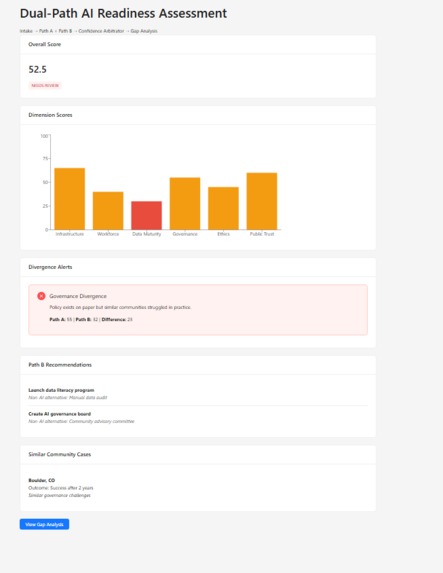
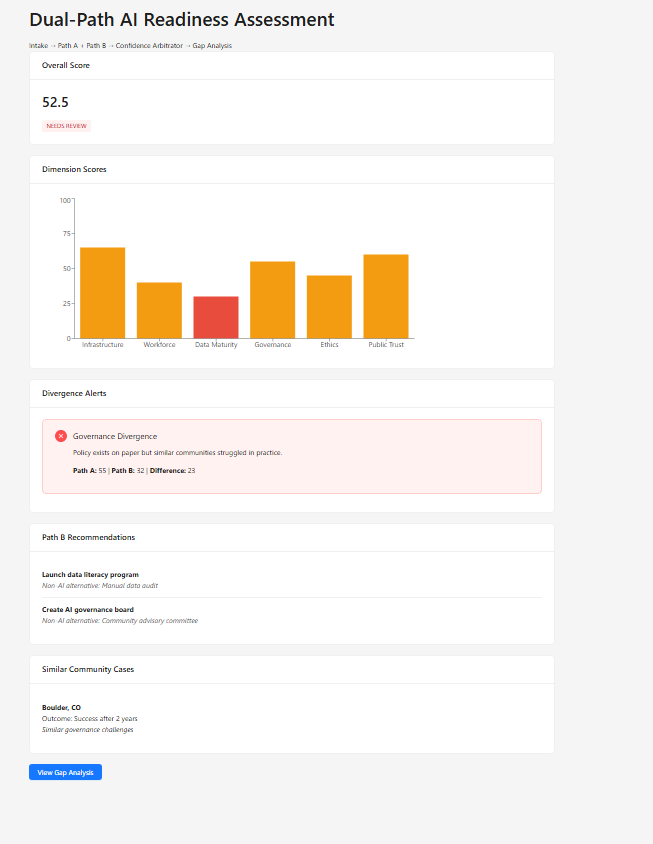
Divergence Alert — Confidence Arbitrator flags governance gap between Path A (58) and Path B (32)
-
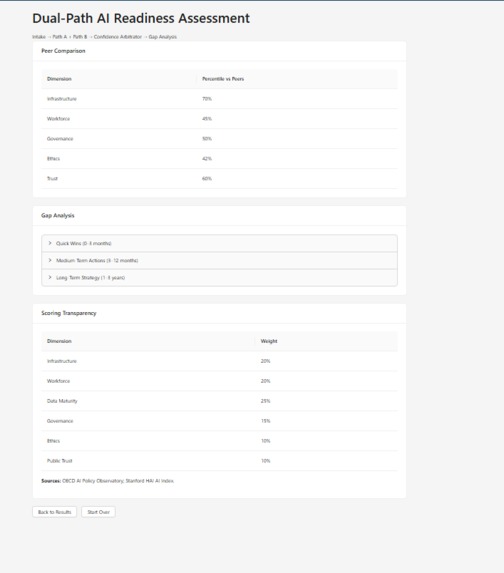
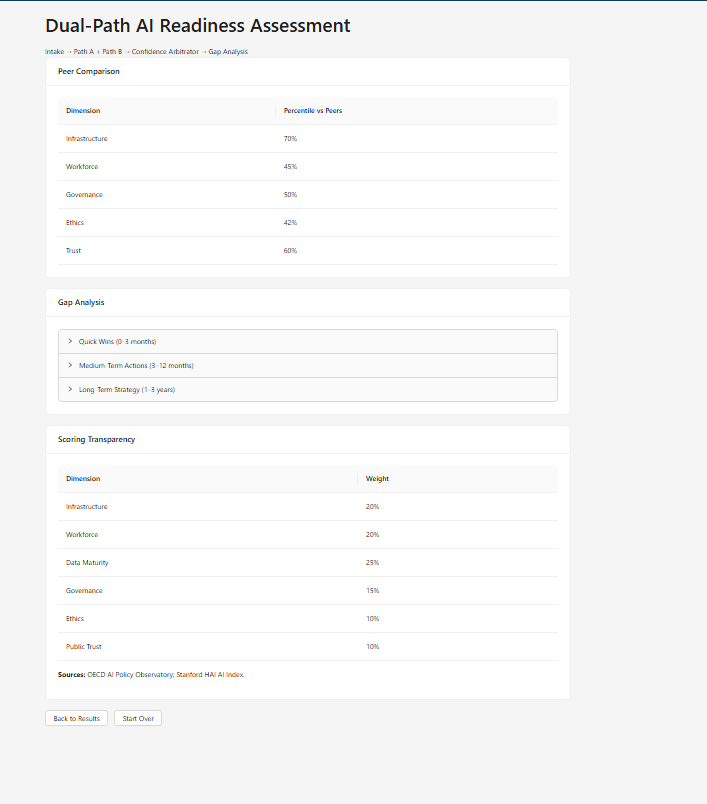
Dual-Path Scoring Results — peer benchmarking and gap analysis with action plans
Inspiration Communities seeking to adopt AI face a fundamental information asymmetry — they don't know what they don't know. Generic checklists ignore local context, and hiring consultants at $50K–$200K per engagement doesn't scale. We asked: what if we could make AI readiness assessment comparable, repeatable, and auditable for any community?
What it does CivicMind AI runs a dual-path scoring architecture on community profiles across six dimensions (Infrastructure, Workforce, Data Maturity, Governance, Ethics, Public Trust):
-Path A (Deterministic):** Weighted scoring with transparent, citable weights from OECD and Stanford HAI frameworks. Every score comes with exact reasoning. -Path B (Contextual):** LLM-powered analysis using Llama 3.3 70B that compares the community against documented AI implementations and surfaces non-obvious patterns.
- Confidence Arbitrator:** Compares both paths dimension-by-dimension. Agreement = high confidence. Divergence = flags the exact dimension and triggers human review.
The system also generates peer benchmarking (percentile rankings), tiered action plans (quick wins, medium-term, long-term), and mandates a non-AI alternative for every recommendation.
How we built it Backend built with Python (FastAPI), deterministic scoring via scikit-learn, and contextual analysis via Groq API (Llama 3.3 70B). Frontend in React with Ant Design and Recharts for interactive dashboards. The Confidence Arbitrator uses rule-based divergence detection with configurable thresholds per dimension.
Challenges we faced The core challenge was making the LLM output structured and reliable enough for policy-level decisions. We solved this by constraining Path B to return JSON with mandatory citation fields and pairing every LLM recommendation with a deterministic cross-check from Path A. If they disagree, the system says so rather than hiding the uncertainty.
What we learned AI readiness assessment is fundamentally a governance problem, not a technical one. Any tool that scores "readiness" is encoding value judgments in its weights. Making those weights transparent, challengeable, and citable is as important as the scoring algorithm itself.
What's next
- RAG pipeline with a curated knowledge base of 500+ community AI implementation case studies
- Multilingual intake and output (starting with Spanish)
- Community-driven feedback loop where communities can challenge scores with evidence
- External advisory board review of weight adjustments on a quarterly cycle
Built With
- ant-design
- fastapi
- groq
- llama-3.3-70b
- pydantic
- python
- react
- recharts
- scikit-learn

Log in or sign up for Devpost to join the conversation.