-
-
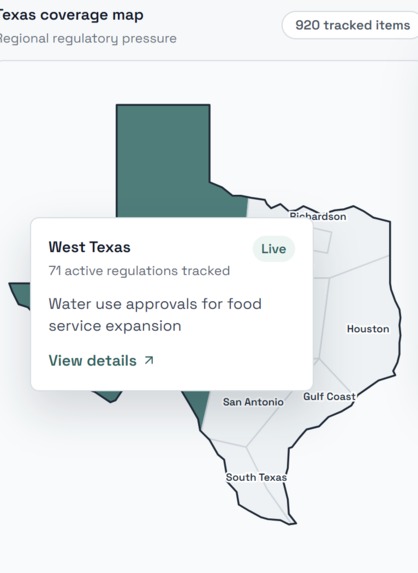
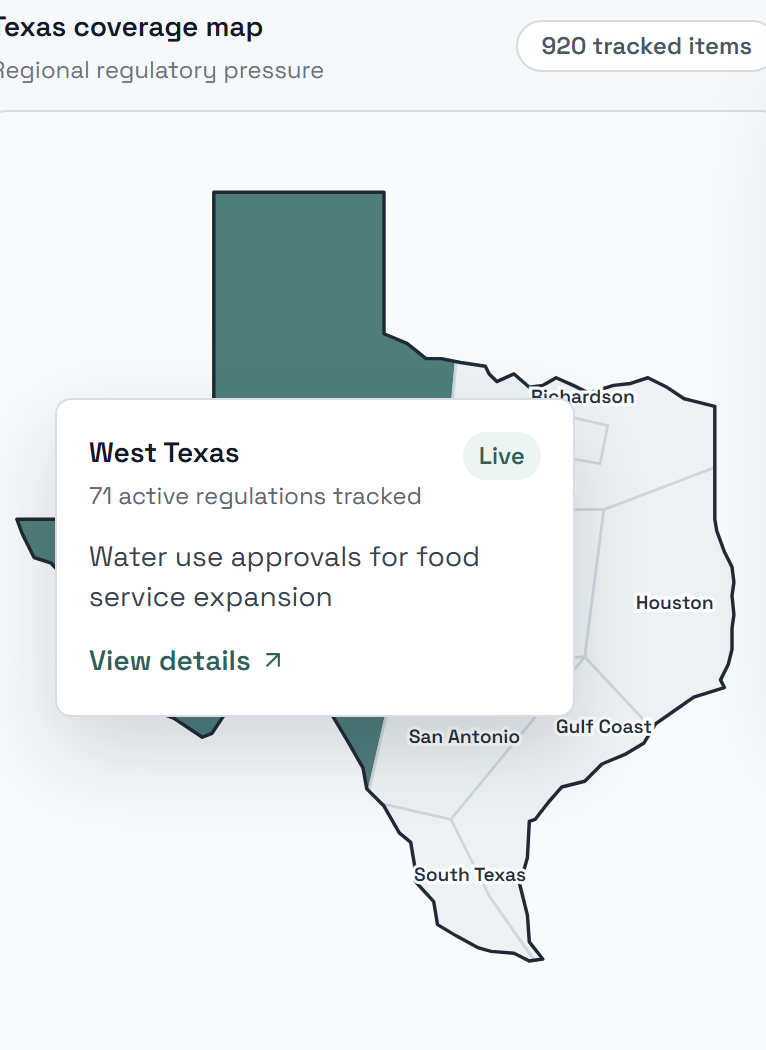
Interactive Map
-
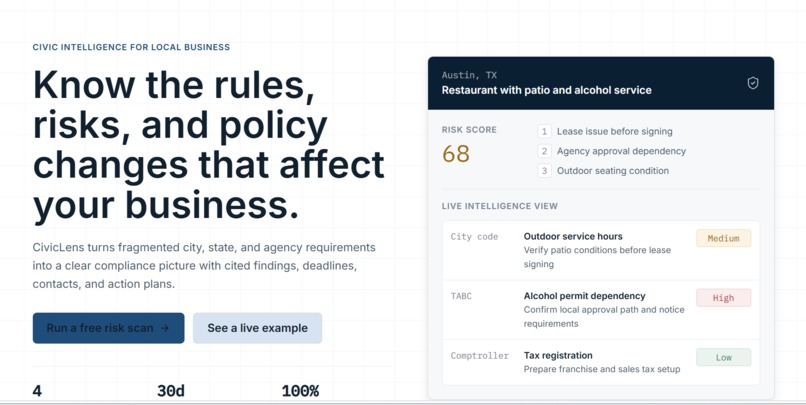
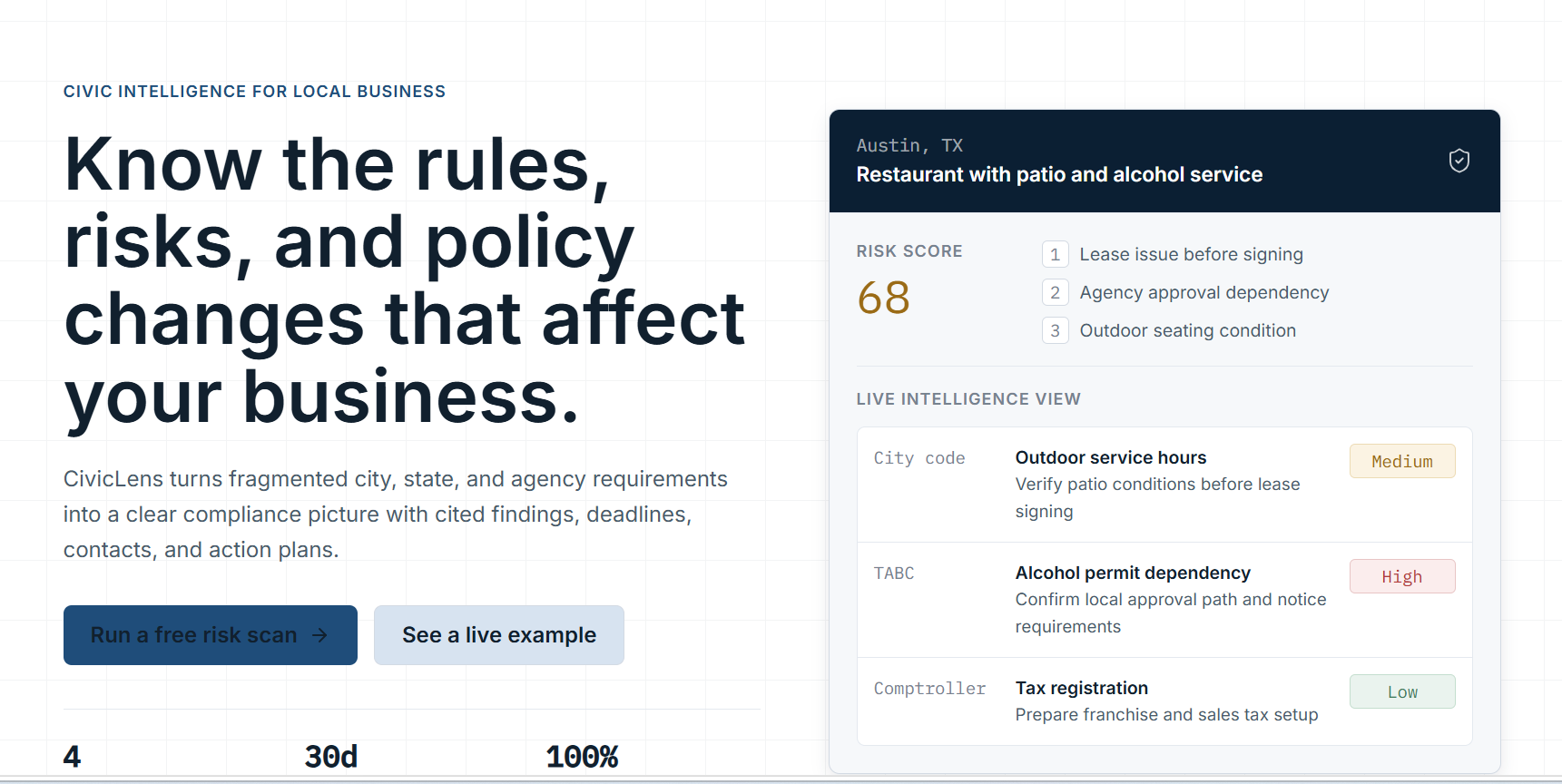
landing
Inspiration
We started with a real problem. A small business owner in Texas failed a health inspection three days before opening because she didn't know a separate food handler certificate was required. She found out from her neighbor, not from any government website. This shouldn't happen. In Texas, compliance obligations are split across state agencies, county departments, and city governments with zero coordination. A business with a $500/hr lawyer gets this mapped in an afternoon. A business without one spends weeks—and still misses things. We built CivicLens to close that gap.
What it does
CivicLens is an AI regulatory intelligence platform for small business owners. You describe your business in natural language: "I own a food truck in Dallas and want to open a restaurant in Austin with a beer garden." The system auto-classifies your business, retrieves relevant regulations from a curated knowledge base, and generates a personalized compliance risk dashboard. You see what permits you need, what might trip you up, and why—with every finding linked to the actual government source. Our signature feature, the Regulatory Diff Engine, shows you side-by-side what changes when you move cities or expand your business model. A weekly Compliance Pulse email monitors new ordinances and bills relevant to your business so you're never caught off-guard.
How we built it
Frontend: Next.js 14 with React and Tailwind CSS for a clean, responsive UI. Backend: NestJS with Express for scalable API endpoints. Database: PostgreSQL with pgvector for semantic search on regulatory documents. RAG Pipeline: We chunked public regulatory data (Texas Licenses & Permits Guide, TABC requirements, city ordinances, recent bills) and embedded them with OpenAI's text-embedding-3-small. When a user submits a business profile, we retrieve relevant chunks via vector search and pass them to Claude with a structured prompt that forces citations. Every finding returned must include a source URL—if we can't cite it, we don't return it. The Diff Engine uses pre-validated scenario templates (food truck to restaurant, salon expansion, etc.) with manually verified requirements to guarantee accuracy. Data ingestion and embedding runs in Python with LangChain.
Challenges we ran into
RAG hallucinations: LLMs are confident about things they don't know. We solved this by adding a citation validation step—any finding without a valid source link is rejected before reaching the user. Data complexity: Regulatory requirements vary wildly by city and industry. We could have tried to cover all of Texas, but instead we focused on a narrow set of high-regulation business types and cities, building an architecture that scales without expanding the scope of the MVP. Time pressure: We had 11 days. We ruthlessly prioritized: the RAG pipeline and one perfect demo scenario (food truck to Austin restaurant) took priority over multi-city support or additional business types. Accuracy verification: Every citation had to be manually spot-checked against real government sources before we showed it to judges. This was tedious but non-negotiable—one wrong permit requirement would destroy credibility.
Accomplishments we're proud of
Building a working RAG pipeline with enforced citations in 11 days. Most teams that attempted regulatory AI ended up with generic chatbots that hallucinate laws. We built something that actually grounds its output in real sources. The Regulatory Diff Engine is genuinely novel—we haven't seen this feature in other compliance platforms. It's technically simple but conceptually powerful: showing what changes when you move cities or expand is something a lawyer would charge $500 for, and we deliver it instantly. We also nailed the demo. Running it 15+ times before submission meant we caught edge cases, optimized for speed, and built confidence that it would work under pressure. The real business owner story we opened with—specific names, specific fine amounts, specific failure points—made the problem real in a way generic slides wouldn't. And we shipped a professional product in two weeks that actually solves a problem people have.
What we learned
LLMs are powerful but require guardrails. The instinct to "just ask the LLM everything" fails immediately in high-stakes domains like legal/regulatory work. You need citation validation, source grounding, and human spot-checking. Regulatory data is messier than we expected. Government websites use different terminology, update on different schedules, and sometimes contradict each other. Building against real-world fragmented data taught us more than using a cleaned dataset would have. Focus is everything in a hackathon. We said no to multi-state expansion, no to bill prediction, no to user accounts. That "no" let us say yes to polish, accuracy, and a memorable demo. And finally: civic tech problems are not solved by just adding AI. The value is in understanding the specific problem (fragmented regulations), choosing the right technical approach (RAG with citations), and building with the constraint that you can't be wrong about legal/regulatory guidance.
What's next for CivicLens
Implement actual email delivery for Compliance Pulse monitoring and add user authentication so businesses can save their profiles. Expand the Diff Engine from one validated scenario to three. Broaden to all Texas business types and launch a paid tier ($9.99–19.99/month) for ongoing monitoring and multi-location support. Partner with Small Business Development Centers and chambers of commerce to embed CivicLens as a member benefit. Expand to other states (California, New York, Texas model of fragmented state/local rules exists everywhere), build APIs for integration with accounting software and POS systems, and launch a mobile app. Long term, we want CivicLens to be the standard way small businesses navigate government compliance: not because they're forced to hire lawyers, but because they have access to the same information those lawyers use.
Built With
- 3
- actions
- autoprefixer
- beautiful-soup
- ci
- class-transformer
- class-validator
- compose
- concurrently
- css
- docker
- eslint
- express.js
- github
- gl
- gsap
- jest
- jsdom
- langchain
- library
- lucide
- maplibre
- nestjs
- next.js
- node.js
- npm
- openai
- pgvector
- platform
- postcss
- postgresql
- prettier
- prisma
- psycopg2
- python
- python-dotenv
- radix
- railway
- react
- requests
- rxjs
- sdk
- splitters
- supertest
- tailwind
- testing
- text
- typescript
- ui
- vercel



Log in or sign up for Devpost to join the conversation.