-
-
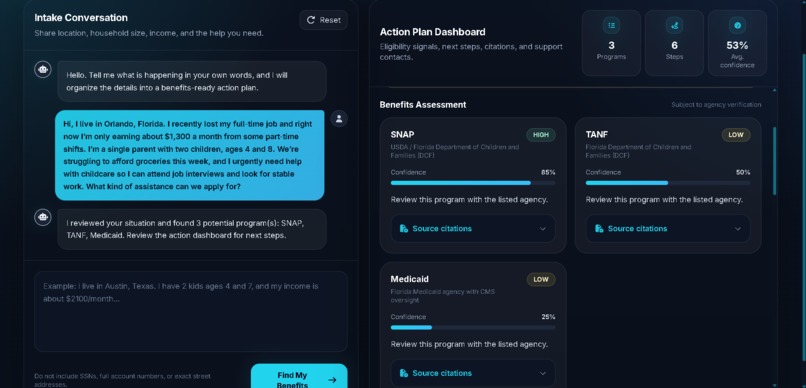
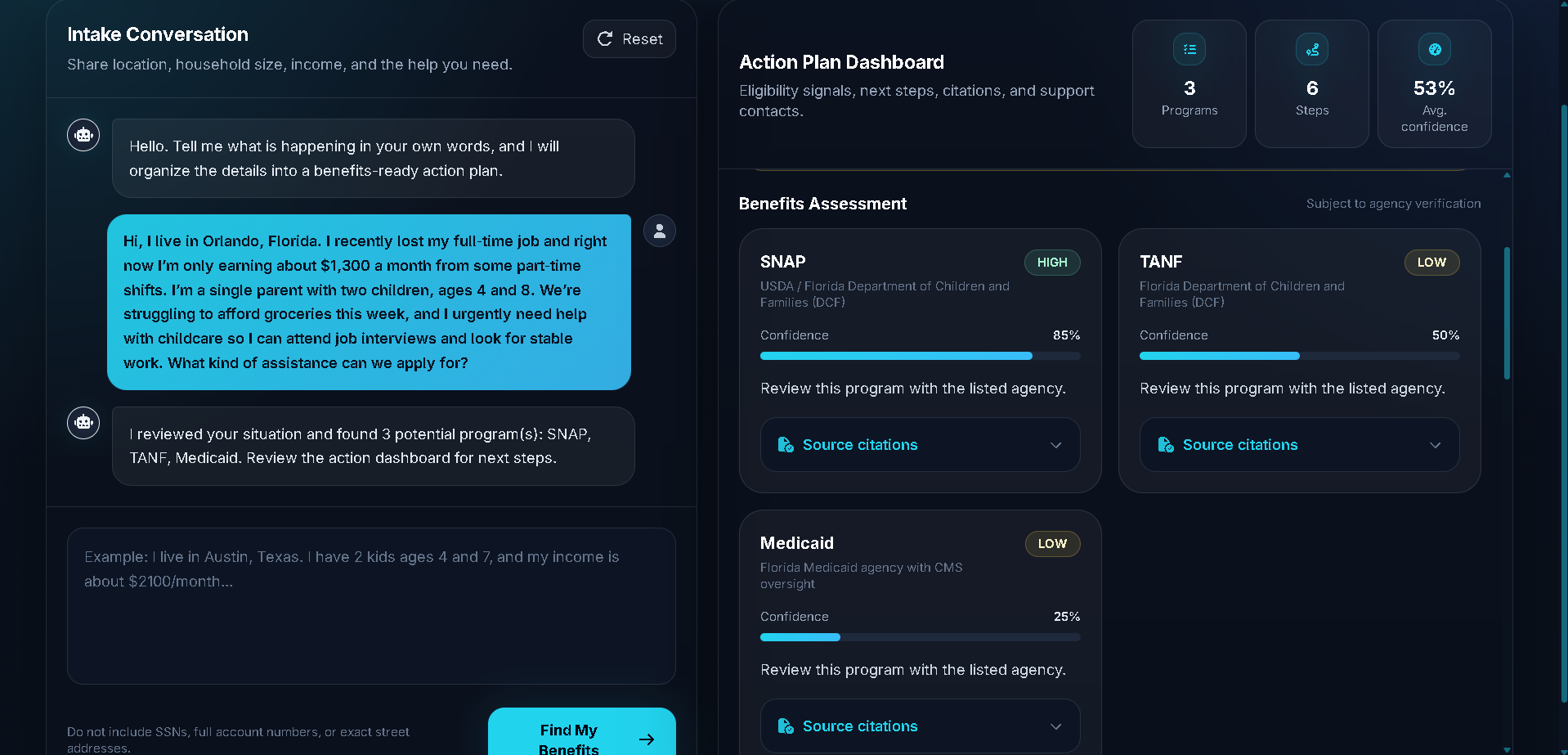
The CivicEase AI dashboard: Conversational chat maps directly to a benefit roadmap, checklists, and localized contacts.
-
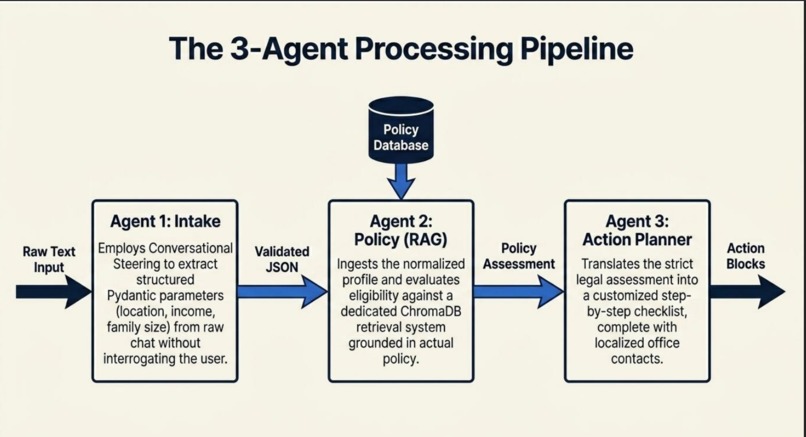
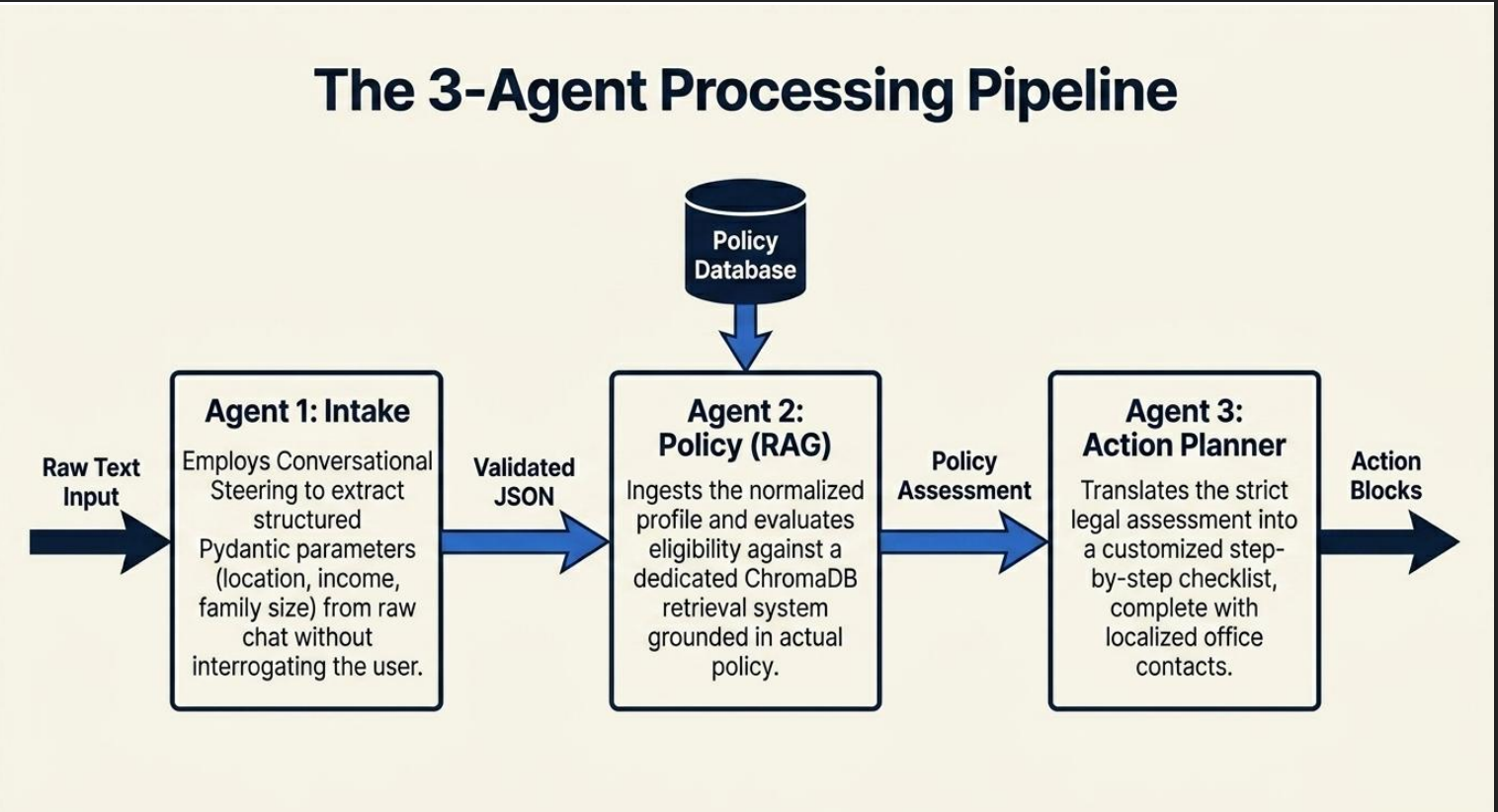
The 3-Agent Pipeline: Sequential Intake parsing, state-filtered ChromaDB Policy RAG retrieval, and Action Plan compilation.
-
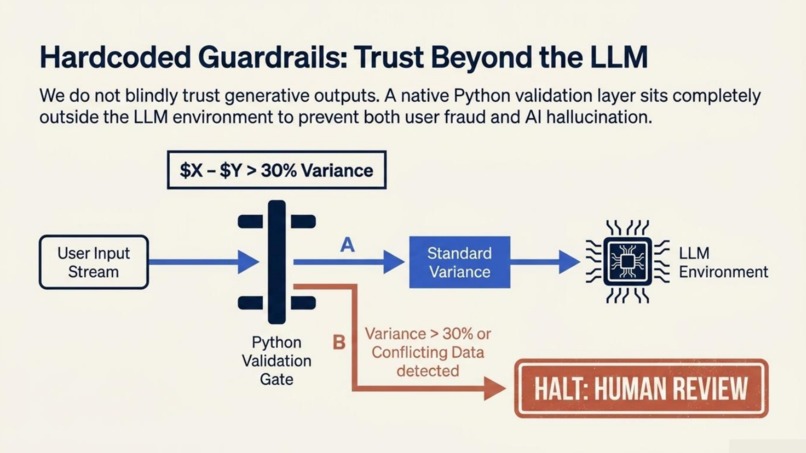
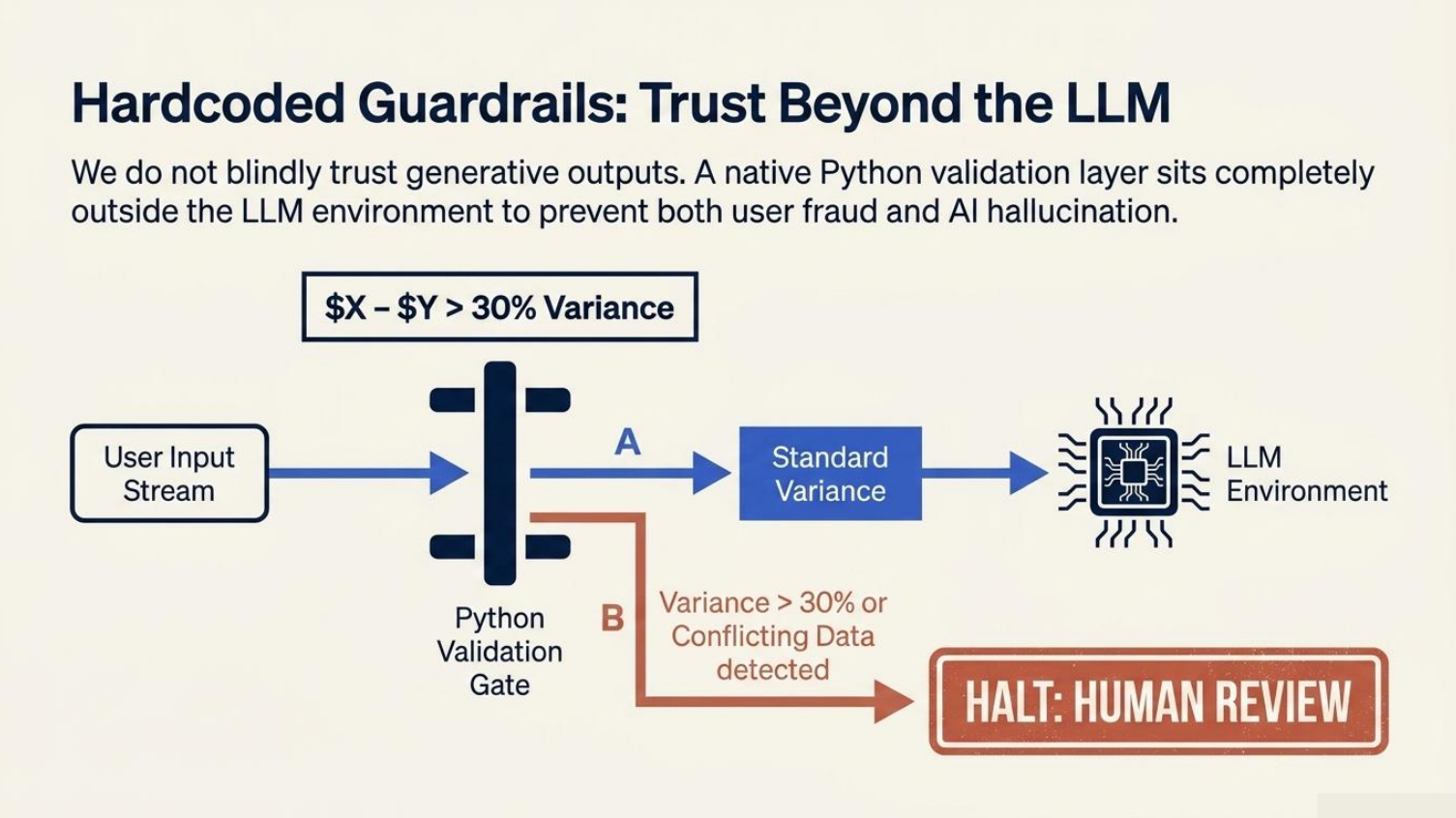
Hardcoded Guardrails: A Python validation layer enforcing data constraints and routing input anomalies to human review.
Inspiration
Every year, billions of dollars in public benefits go unclaimed because eligibility systems are fragmented across dense legal documents, state-specific rules, confusing agency websites, and inaccessible application workflows. We built CivicEase AI for families, students, seniors, single parents, and low-income households who may qualify for support but do not know where to start.
Our goal was to create a reliable AI benefits navigator that feels like an empathetic digital caseworker while preserving the rigor expected from legal and financial policy systems.
What it does
CivicEase AI transforms a user's plain-language situation into a localized benefits roadmap. A user can describe their household, income, location, and needs conversationally. The system extracts eligibility variables, asks clarification questions when critical information is missing, retrieves relevant state policy context, evaluates likely eligibility, and generates a practical action dashboard.
The final output includes likely benefit matches, confidence scores, reasoning grounded in retrieved policy documents, checklist tasks, required documents, local agency contacts, and cautious next-best actions.
How we built it
CivicEase AI is a Flask-based multi-agent platform built with Python, LangChain, ChromaDB, Pydantic v2, Groq's Llama-3.1-8b-instant model, and HuggingFace sentence-transformer embeddings. The runtime uses three sequential agents. The Intake Agent extracts structured eligibility variables from natural-language input and validates them with Pydantic v2, asking a clarification question if critical details are missing. The Policy Agent performs state-aware semantic retrieval from ChromaDB and evaluates likely eligibility using a structured four-step Chain-of-Thought reasoning protocol. The Action Agent converts verified policy matches into a user-facing application roadmap with checklist tasks, documents, and local agency contacts. For the production upgrade, we moved from basic RAG indexing to a manifest-based incremental sync pipeline. Each source document is tracked using MD5 content hashes, file size, last-modified metadata, and chunk configuration. We use LangChain's RecursiveCharacterTextSplitter with chunk_size=800 and chunk_overlap=150 to preserve dense legal and financial context across chunk boundaries. Each chunk receives a deterministic SHA-256 ID derived from source metadata and content. ChromaDB native upsert then updates existing vectors or inserts new ones without wiping the database. This prevents duplicate vectors, keeps retrieval clean, and allows changed policy documents to be refreshed without a full rebuild. We also added an APScheduler background ingestion worker so policy updates can run without interrupting the main Flask API.
Challenges we ran into
The biggest challenge was reliability. Small LLMs can produce valid-looking but incorrect benefit recommendations, especially when eligibility math is involved. We solved this with four layered guardrails. The Retrieval Guard restricts the LLM to verified policy chunks from ChromaDB. The Schema Guard validates all LLM outputs with Pydantic v2 models. The Self-Consistency Guard removes any benefit match where the model's own Chain-of-Thought reasoning contradicts its final conclusion. URL sanitization prevents unsafe or hallucinated links from being shown to users.
The second major challenge was keeping the policy database fresh without rebuilding everything on every update. Our manifest-based incremental sync now detects changed files using MD5 hashes and reprocesses only the affected source document, leaving all unchanged vectors intact.
Accomplishments that we're proud of
We are proud that CivicEase AI evolved from a prototype benefits chatbot into a reliability-focused, production-style AI system. The platform now combines a three-agent workflow, policy-grounded RAG retrieval, strict Pydantic validation, and deterministic ingestion infrastructure to produce benefit guidance that is both useful and auditable. A major accomplishment was achieving strong validation results across our evaluation suite: 100.0% intake extraction accuracy, 100.0% structured reasoning completeness, a 51.2% system F1-score, and 0% verified hallucinations. These results show that the system can extract user circumstances, retrieve relevant policy context, and produce cautious benefit recommendations without inventing unsupported claims. We are especially proud of the production RAG upgrade. CivicEase AI now uses manifest-based incremental sync, SHA-256 deterministic chunk IDs, RecursiveCharacterTextSplitter with 800/150 chunking, and ChromaDB native upsert. This means the system can refresh changed policy files without wiping or rebuilding the entire vector database.
What we learned
We learned that production-grade AI systems require more than prompt engineering. The core engineering work is in contracts, validation, observability, data freshness, and failure handling. The project reinforced that Responsible AI is architectural: if policy data is stale, duplicated, or unverified, the model cannot be trusted. By combining deterministic ingestion, RAG grounding, schema validation, and cautious final messaging, CivicEase AI reduces over-reliance and keeps users oriented toward official benefit channels.
What's next for CivicEase AI
Next, we plan to add multilingual intake, voice-based accessibility for elderly and visually impaired users, official state API integrations, and a production deployment where the ingestion worker runs as a dedicated scheduled cloud job. We also prepared an MCP roadmap so future agents can access ChromaDB and external policy APIs through standardized, auditable tool contracts.



Log in or sign up for Devpost to join the conversation.