-
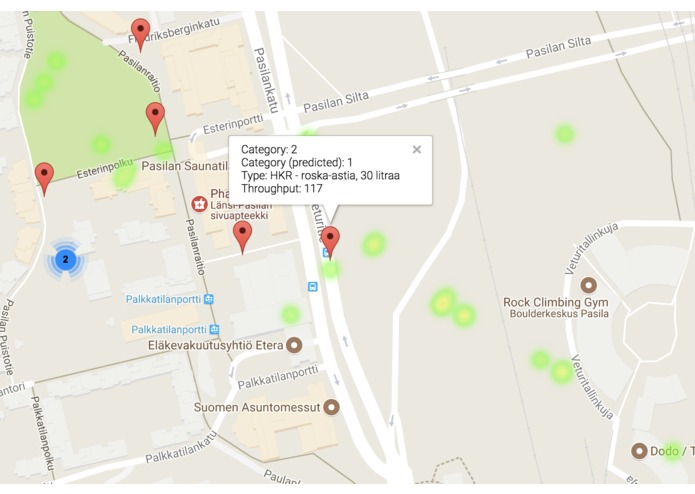
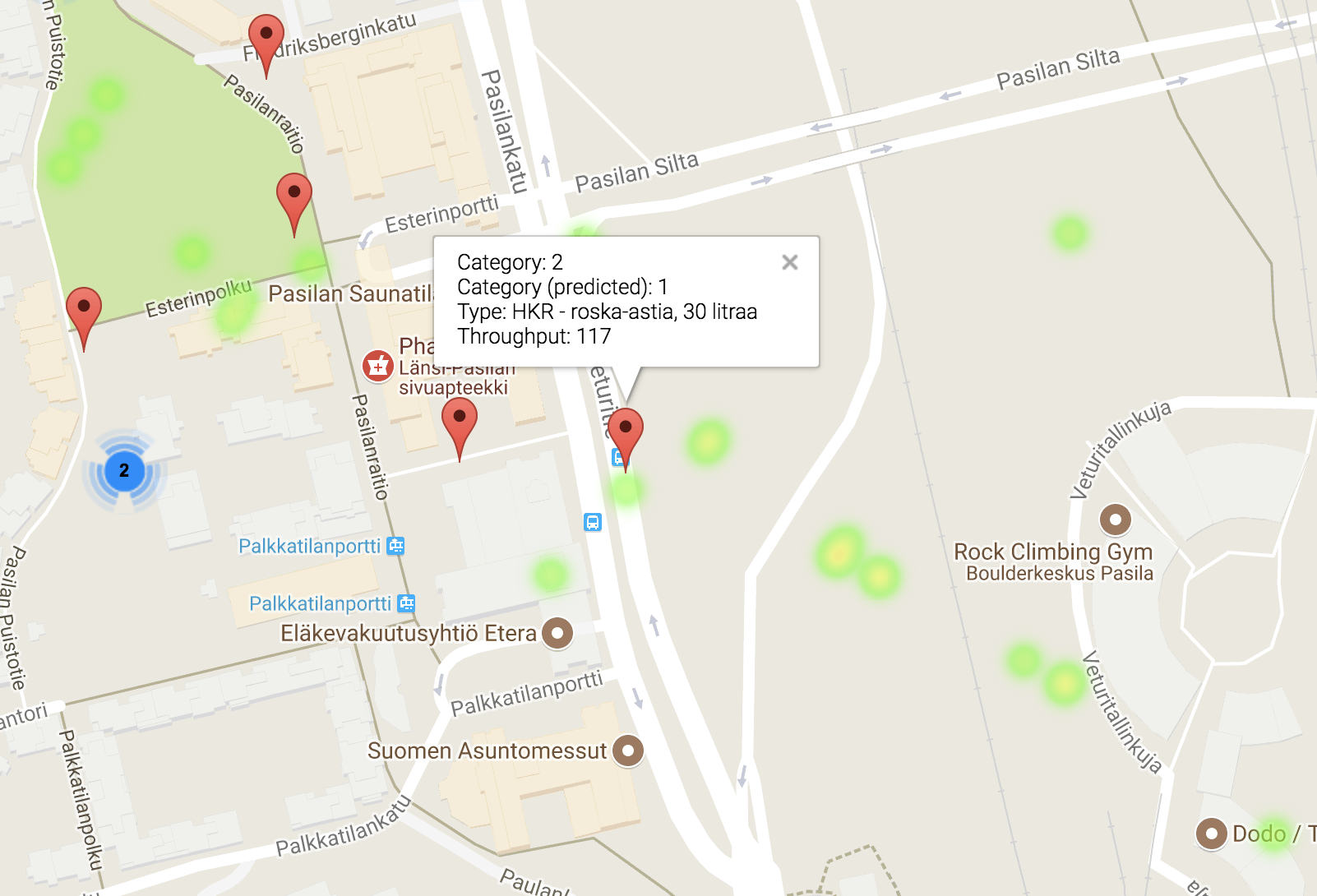
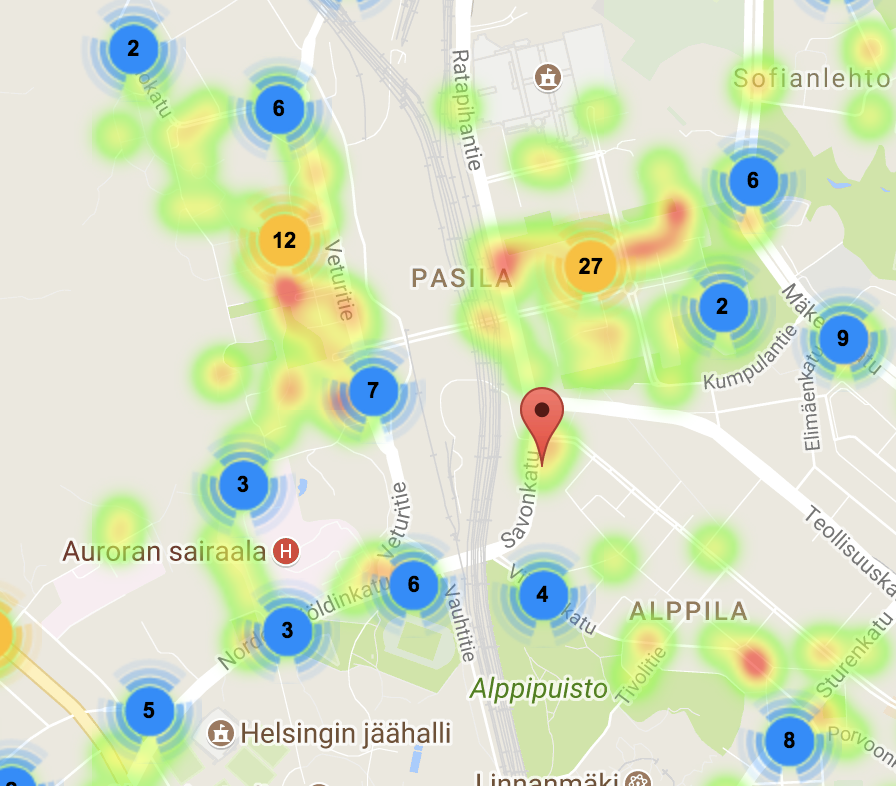
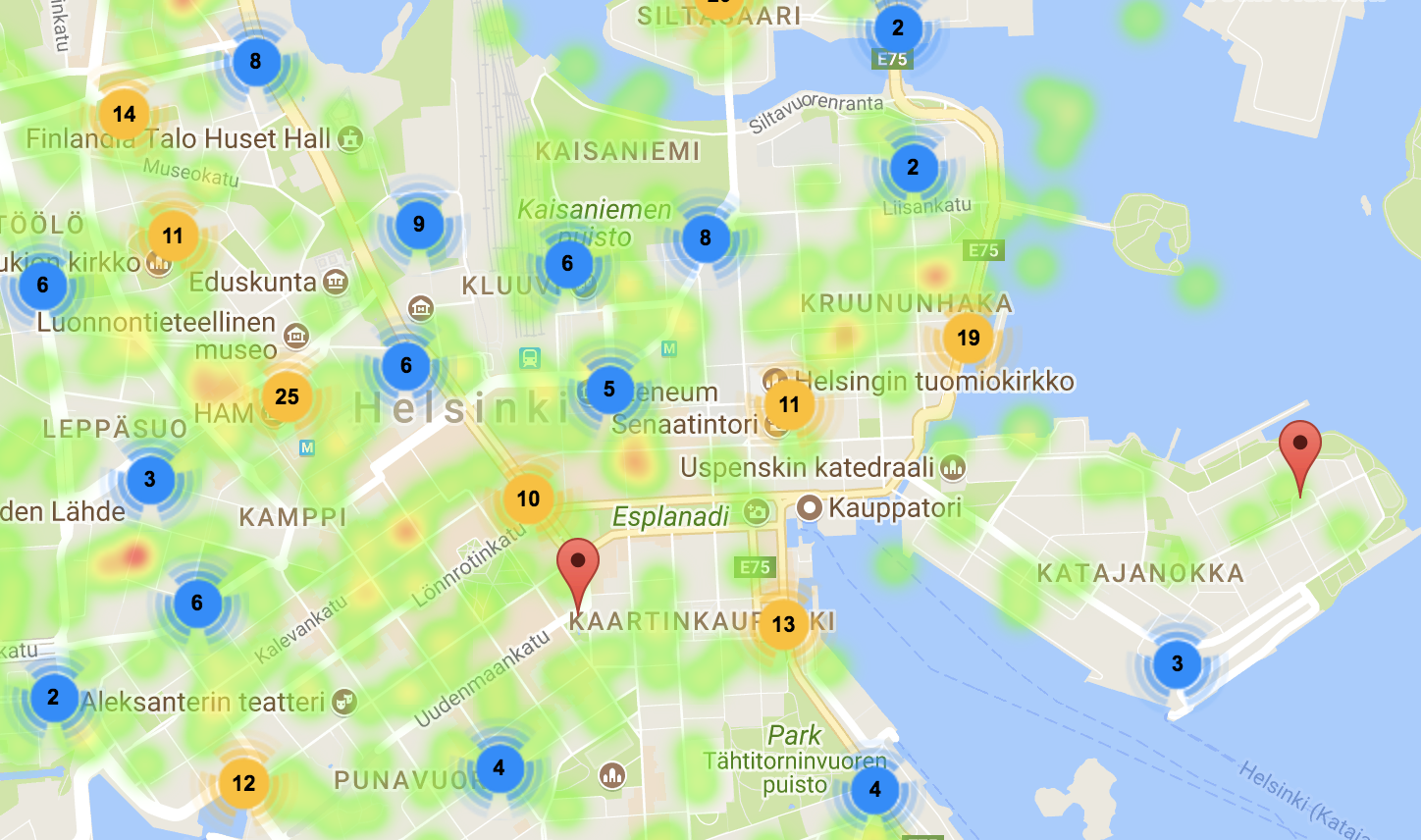
Markers represent bins location. A detailed information is presented on-click
-
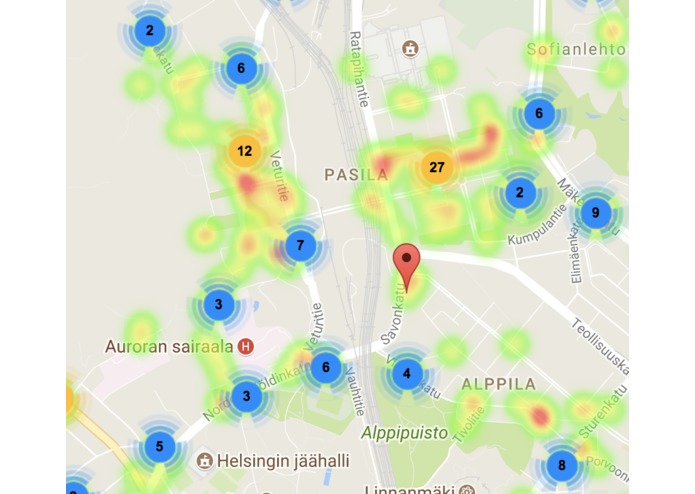
Users can switch between population density and trash bins density
-
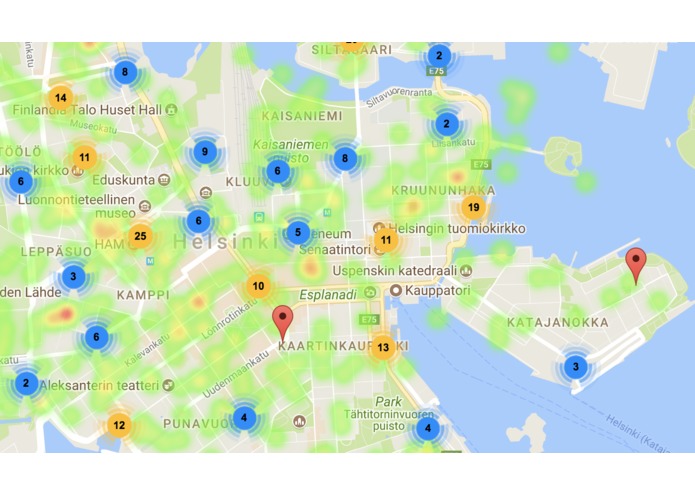
We represent population density over an area as a heatmap
Inspiration
This project started out as an desire to optimise travel routes of trash collectors for STARA BigData track. But as we dug dipper into the data, we discovered an underlying problem with trash bin classification and developed a general approach that estimates a demand based on the population density around a bin. The developed technology can also be applied to optimize public transportation and predict movement patterns within a city.
What it does
It takes elisa people flow dataset and converts it to tracks representation. The tracks are then used to estimate population density around a given point. This information can be used to dynamically predict demand on various city resources (such as trash, public transport etc.).
How we built it
We extensively collaborated with STARA to understand their needs. The development process was iterative - we started with a very blurry idea and absence of clear vision, but as we progressed through the data, various available APIs and customer needs, the final shape of the project started to appear and developed into a conceptual vision.
Challenges we ran into
There were numerous challenges that we encountered:
- Handling large amounts of data (126Gb of compressed text files) using Hadoop and Google Cloud platform
- Uploading and storage of large amounts of data
- The location data of the trash bins was in EUREF-FIN coordinates system, which is significantly different from GPS and conversion is not straight-forward
- Studying and discovering various APIs that were provided by the organizers
- Data processing to transform data into uniform representation
Accomplishments that we're proud of
- We handled all aforementioned challenges and were able to develop our ideas into a core technology - population density estimation software
- We applied our core technology to propose a solution for dynamic class estimation of trash bins, which should significantly improve performance of trash collection
What we learned
- An extensive collaboration with the customer allowed us to better understand their needs and provide a better solution. We also got valuable insights into the data, easing the process of discovering relations
- Distributed computing uses different algorithms for familiar tasks (some tasks are not trivial to implement in a MapReduce job)
What's next for CityFlow
So far we managed to implement the basic functionality, but we are far from completion.
The next step would be to use flow data to predict movement patterns. Having done so, we will be able to introduce predictive element into our estimation (for example, in the trash class estimation, we would not only account for current density, but could also understand how the demand will change based on movement patterns).
After that, we could develop a prioritisation model to assign more resources to areas with higher demand and dynamically allocate more resources to these areas.
Helsinki also uses a network of smart trash bins that can estimate their filling level. We will gather historical data on filling rates for the smart bins and see if there are correlations between population density and how fast the bin fills. Having developed the regressive model for smart trash bin filling rates, we will extrapolate these models and 'dump' (ordinary) bins, reducing the demand for smart bins and cutting costs.
In addition, having these datasets we will be able to provide recommendations about trash bins placement (in case if we need to move some or add more in crowded places)

Log in or sign up for Devpost to join the conversation.