-
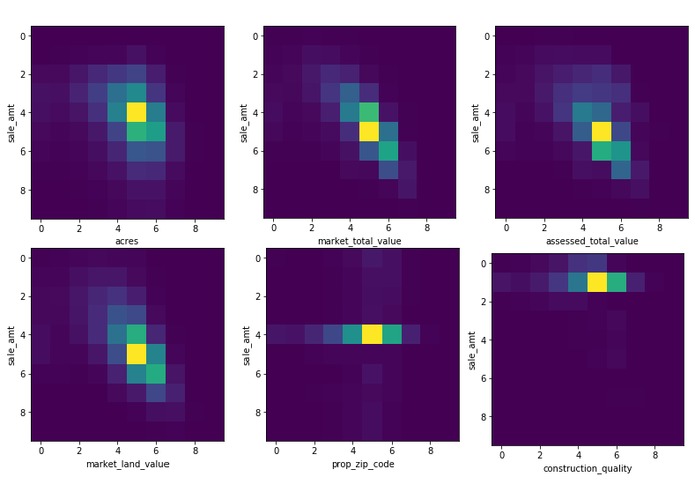
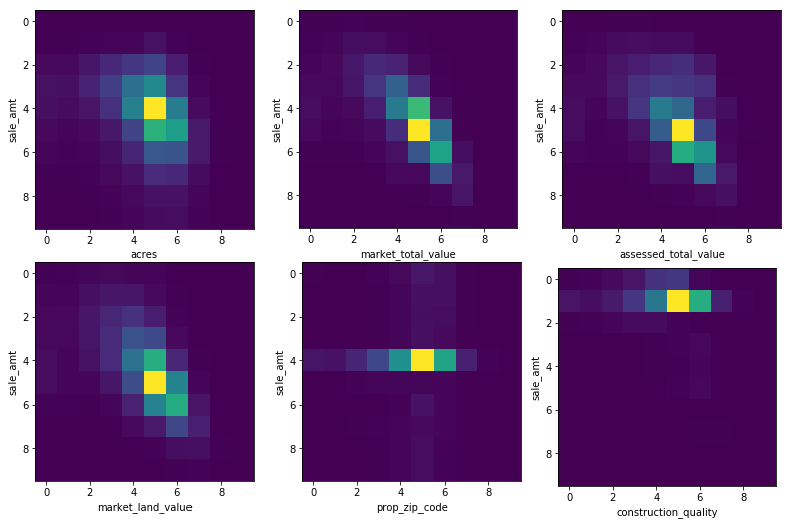
Heat Map
Inspiration
The house price is always interesting to us! However, we have no idea if the purchase price is reasonable or not when we buy it. Searching and model/learn the previous data, we can have better idea how much we should pay. That's awesome to everyone!
What it does
We used the data from Citizens database, which includes many possible features that may affect the final sale price. We first did a thorough data analysis to find out the features we finally want to apply to our model, and then built various models to test the accuracy.
How I built it
Finally, we used 7 features from the database to build the model. Different models include Random Forest, K Nearest Neighbors (KNN), Light Gradient Boosting Machine(LGB), and Support Vector Machine(SVM) are used to predict the accuracy.
Challenges I ran into
One challenge we faced is to extract the feature space. The features included in the database is large, there are information that is not related to our sale price, and also some features are correlated that we should only conserve only one. Another challenge is the modeling cost. Some models are pretty costly such as SVM and KNN with larger number of neighbors. Both time and memory complexity are some limitations at some point.
Accomplishments that I'm proud of
We can accurately predict the sale price and the percentage of predictions with 10% error is above 83.6%!
What I learned
We learned a lot of data analysis skills and modeling types. Through large data analysis, we can clearly understand the computational cost between different models.
What's next for Citizens
The database is not complete, the percentage of NaNs are too high, that makes a lot of features biased when modeling and predicting.

Log in or sign up for Devpost to join the conversation.