-
-

Take a look at the website's home page!
-
-

Behind the scenes into our graphic design process. Logos don't make themselves!

Inspiration
When first exploring a new field, one can easily become lost in the sea of papers. Increasingly, we see K-12 students stumbling upon the academic world out of personal interest or for advanced classes. But without prior experience, navigating between different papers can quickly come a nightmare. What if there was a utility made to connect related papers and illustrate how citations are related to each other? Our application mitigates the challenge of getting into the research world through an intuitive display combining data science and visualization.
Combine and Choose From Different Sources

When putting in a topic or original paper you want to build off of, Citation Scholar provides a variety of selections. In our first implementation, these sources can include arxiv, google scholar, acm, and ieee. Once selected, Citation Scholar looks for paper citations from the original source in each of these respective databases.
View Your Citation Network From Different Angles

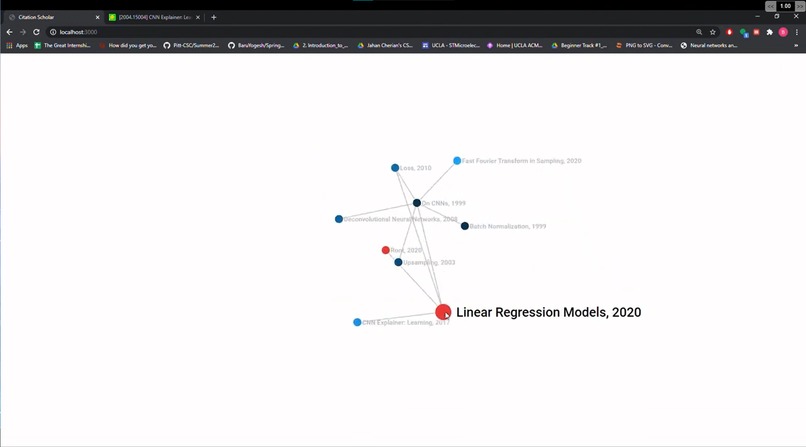
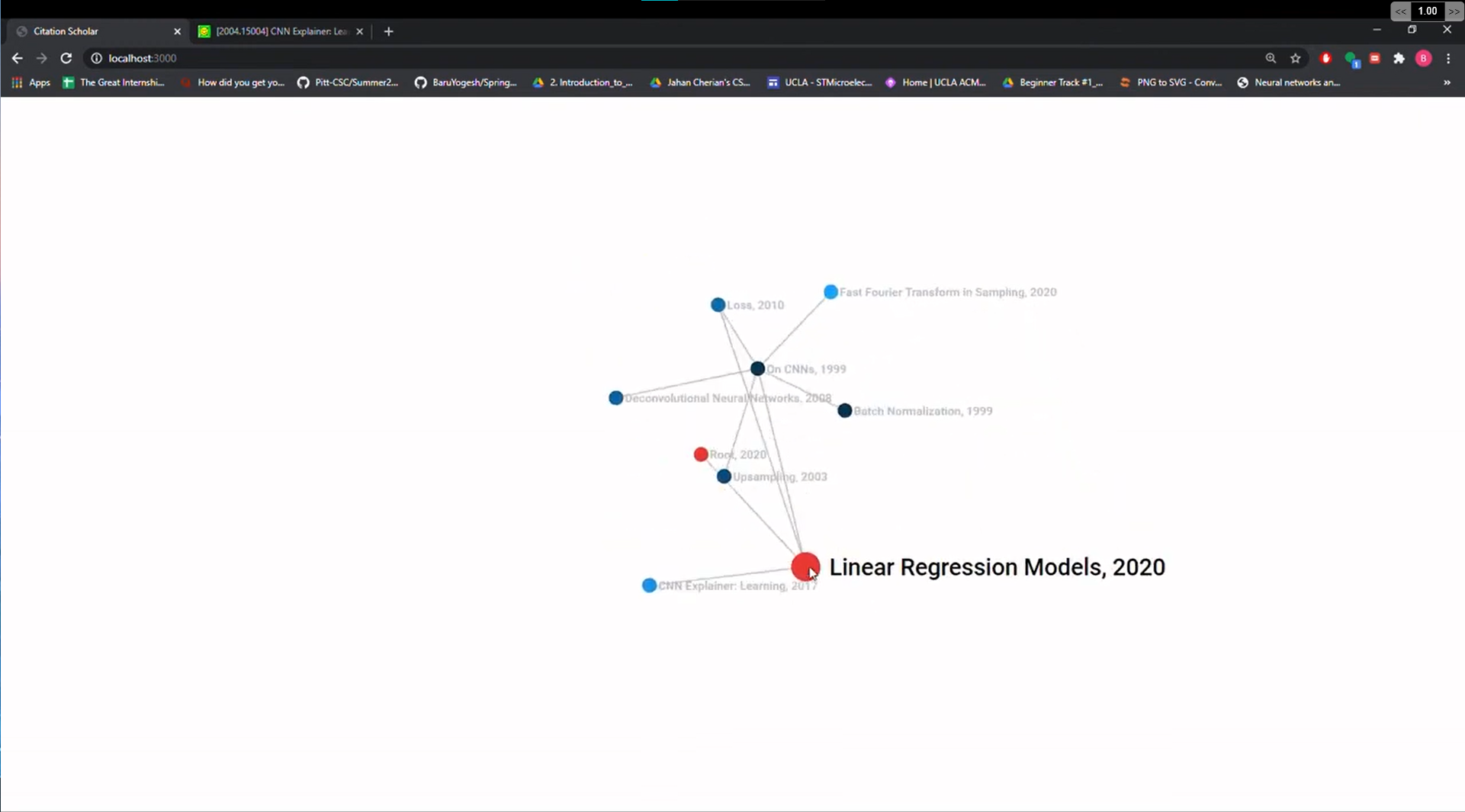
Sometimes a change of perspective can paint research in an entirely new light! By using a dynamic force graph, Citation Scholar makes it easy to view research. We utilized D3.js and a force graph to allow for manipulation of the graph structure while keeping edges intact. Notably, the shade of each node highlights its date. The older the paper is, the darker its shade: a useful visual indicator when trying to find papers of related topics.
The red node shows the starting origin of the inputted research paper. Once hovering over a node, the selection boldens and zooms to provide visual clarity. Double clicking brings you to the research paper featuring that title. And voila, we have a force graph visualization of the world of academia!
How We Built the Frontend
We used React and D3.js as a graph building library to build the citation network based on the data sent to us by our backend. While waiting for the backend to process, React updates the virtual DOM with a loading icon written using CSS. After retrieving the data, React updates the page to the generated force graph. Each node in D3.js is its own unique circle class with a respective shade and hover properties.
How We Built the Backend
The backend (a Flask server) commmunicates with the frontend via Flask endpoints. Once it receives search parameters from the frontend:
First, it tries to resolve these search parameters using the "scraper modules" available to it. A "scraper module" is a python module with a defined interface that will scrape Paper data from a database. Due to time constraints, we have only added a arXiv scraper -- more can be quickly written up as plugins.
Once a "scraper" has found the text of a paper, we look through the paper to get a list of its citations. Our original plan was to do this entirely via semantic analysis of the paper PDF contents; due to a low accuracy rate, we now query citation databases directly (interpreting the PDF directly as a fallback in case the given citation database doesn't include our paper).
Once we have a list of citations, we recursively find their citations via the same process.
The end result is a directed graph of citation information from several different websites, along with article information + links to the article contents.
Challenges We Ran Into
Web scraping is a task that's very easy to dismiss as "trivial" or a "small part of the project". This is usually never true.
When writing plugins for scraping Google Scholar, we ran into a number of issues. Google Scholar doesn't provide an API, and presents numerous Capchas to prevent automated scraping (such as what we need now). We worked around most of these issues, but in the process spent enough time that we put the rest of our project in jeopardy.
Accomplishments that we're proud of
Brandon's frontend graph is beautiful.
What's next for Citation Scholar
Our code is designed to scrape papers from multiple websites and aggregate the results. To add new functionality, all we have to do is add new "scraper" modules to the scrapers directory.
Because of time constraints, our current prototype only interfaces with arXiv.org. We have setup a plug-in system to add GoogleScholar and other features in the future. We also aim to improve our algorithms to create a reference list that ranks based on the relevance of each paper (i.e., number of times cited by other papers).
Additionally, D3.js supports weighted graphs. When analyzing recursive citations, we can prioritize citations with stronger correlations in content and make the edges connecting between them darker. The current approach works using breadth first search which could be improved dramatically with a algorithm based on correlation.



Log in or sign up for Devpost to join the conversation.