Inspiration
890 search and rescue workers die every year in the US alone not from disasters, but from going in blind. And on the survivor side, the math is unforgiving:
$$P(\text{survival} \mid t) = P_0 \cdot e^{-\lambda t}$$
Survival probability starts at $$P_0 \approx 0.90$$ in hour one and collapses to $$0.20$$ by hour 24. Every minute rescuers spend searching the wrong location is a life that curve swallows.
The worst part: the technology to fix this already existed. Computer vision. Depth estimation. On-device language models. Nobody had built a system that ran all of it where it was actually needed — in the rubble, with no signal, on battery power. That gap is why we built CIPHER.
What it does
CIPHER turns a single laptop and webcam into a complete disaster response intelligence system. Four tabs. One pipeline. Zero cloud.
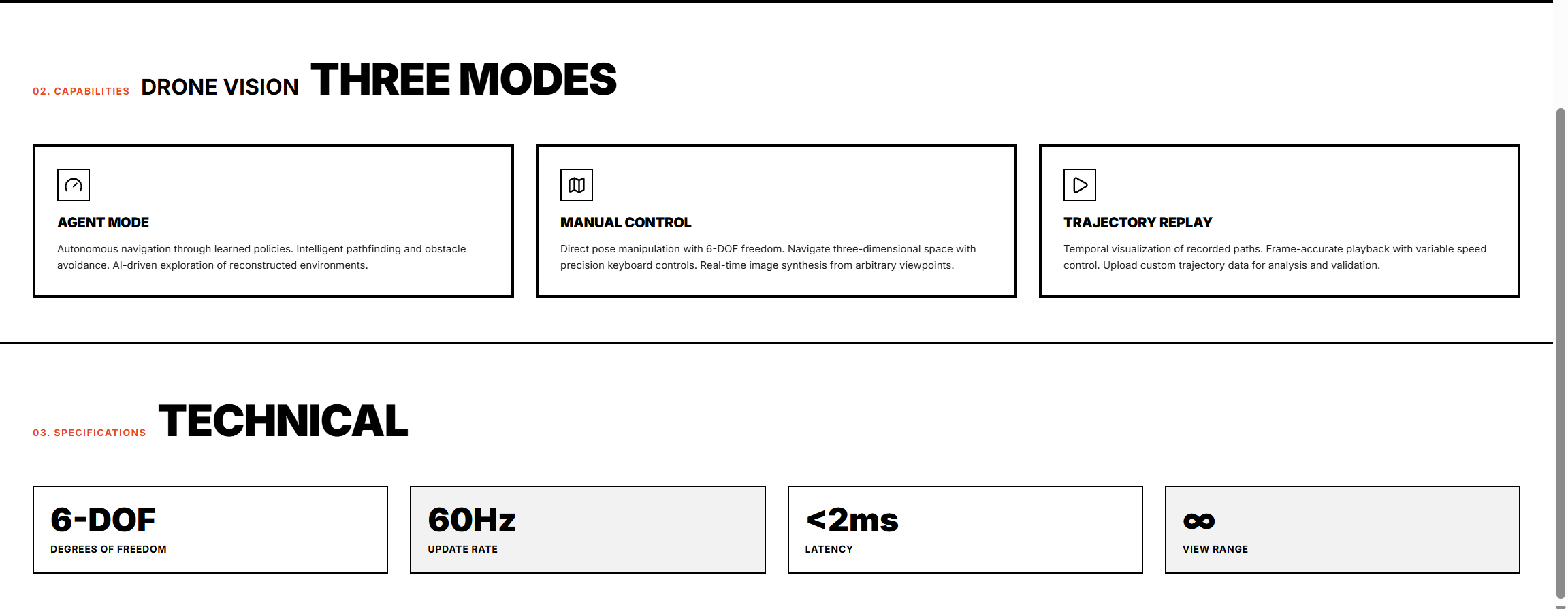
Manual — Live camera with real-time YOLO detection and a semantic overhead map updating as the drone moves. Every survivor, hazard, and structural risk appears on the map the moment it is detected.
3D World — Navigate the recorded space in first person. A live RGB point cloud, a 2D overhead map, and arrow-key navigation through every stored frame. Click any node to jump to it instantly.
Replay — Chronological mission playback with scrubber and speed control for full after-action review.
Agent — Talk to the map. Ask "Where are the survivors?" or "Is it safe to enter the east corridor?" and get an answer grounded in what the drone actually saw — not a prediction, a fact extracted from the live world graph.
Everything runs locally. The footage, the detections, the queries — none of it ever leaves the device.
How we built it
Four models running simultaneously on the Qualcomm Snapdragon X Elite Hexagon
NPU via QNNExecutionProvider:
| Model | Purpose | NPU Latency |
|---|---|---|
| YOLOv8n-det | Persons, hazards, exits | ~35ms |
| DepthAnything | Metric depth per detection | ~28ms |
| YOLOv8n-seg | Pixel-level crack segmentation | ~35ms (every 10th frame) |
| Whisper-Base-En | Voice query transcription | ~600ms |
$$L_{\text{NPU}} \approx 47\text{ms} \quad \text{vs} \quad L_{\text{CPU}} \approx 380\text{ms} \qquad \text{speedup} = 8.1\times$$
Every detection gets written into a world graph — nodes are physical locations storing the camera frame, depth map, semantic labels, and pose. Edges connect nodes where CLIP cosine similarity satisfies $0.30 \leq \cos\theta \leq 0.95$.
Structural risk is scored continuously:
$$R = A_{\text{crack}} \times C_{\text{seg}} \times \sigma^2_{\text{depth}}$$
$$R < 0.30 \Rightarrow \textbf{STABLE} \quad R \in [0.30,\, 0.70) \Rightarrow \textbf{COMPROMISED} \quad R \geq 0.70 \Rightarrow \textbf{CRITICAL}$$
The agent layer runs Whisper for voice input, CLIP for semantic graph search, ChromaDB for local retrieval over emergency manuals, and Llama 3.2 3B via Qualcomm Genie SDK for synthesis. Every answer cites real node IDs from the real map.
Challenges we ran into
Camera crashing under dual-model inference. Running YOLO and DepthAnything simultaneously caused the camera to die within seconds — three threads competing for the same NPU memory bus, the camera buffer overflowing at 30fps while inference took 65ms, and frame buffers passed to both models without copying causing memory corruption. Fixed with three isolated threads connected by bounded queues of depth 2. Camera thread never waits for inference again.
Frame bleeding during video import. Intermediate processing frames were flashing through the navigator mid-import. Fixed by making the frame viewer accept only atomically completed world graph nodes — a node either exists fully or not at all, nothing partial ever reaches the UI.
Silent NPU fallback. The crack segmentation model was not pre-compiled for
Hexagon and silently fell back to CPUExecutionProvider, creating an $$8\times$$
timing mismatch that broke the entire pipeline. Fixed with explicit provider
assertions at startup that fail loudly rather than degrade silently.
Accomplishments that we're proud of
Running four AI models simultaneously on a single NPU at under 50ms combined latency with zero cloud dependency is something we did not know was possible on day one of this hackathon.
The agent grounding is what we are most proud of. It cannot hallucinate a location that does not exist in the world graph. Every answer it gives is traceable to a specific node ID from a specific moment in the mission. When it says a survivor is at Grid B3, there is a camera frame proving it.
And the structural risk formula — combining segmentation mask area, confidence, and depth variance into a single actionable score — means CIPHER tells rescuers which walls are about to fail before they walk past them. That is the feature that could save the 89.
What we learned
The hardest problem in disaster AI is not the models. It is the architecture that holds together when everything else fails. CIPHER was designed from the first line of code around one assumption: the network is down, the GPS is gone, the grid is dead — build accordingly.
We also learned that NPU is not a performance story. It is a power story:
$$T_{\text{battery}} \propto \frac{1}{P_{\text{draw}}} \qquad P_{\text{NPU}} \approx \frac{P_{\text{CPU}}}{3} \implies T_{\text{NPU}} \approx 3\,T_{\text{CPU}}$$
Three times the battery life. In a disaster, battery life is survival time.
What's next for CIPHER
The Snapdragon X Elite in our demo laptop carries a 45 TOPS Hexagon NPU. The Snapdragon Flight drone compute module runs the same Hexagon architecture at under 5 watts.
Every model in CIPHER — detection, depth, segmentation, voice, semantic search, language — can run natively onboard a drone. No laptop tether. No ground station. No video streaming to anything. The drone builds the world graph inside itself, the agent reasons inside itself, rescue teams query it directly over local mesh.
$$\text{Infrastructure required} = \emptyset$$
CIPHER on a drone. Complete autonomy. Complete intelligence. No signal required.
When the signal dies — CIPHER finds the living.
Built With
- css3
- fastapi
- html
- llama
- node.js
- ollama
- onnx
- opencv
- python
- qualcomm
- react
- react-native
- rest
- three.js
- typescript
- vite
- yolov8






Log in or sign up for Devpost to join the conversation.