-
-

Personalised movie recommendation
-
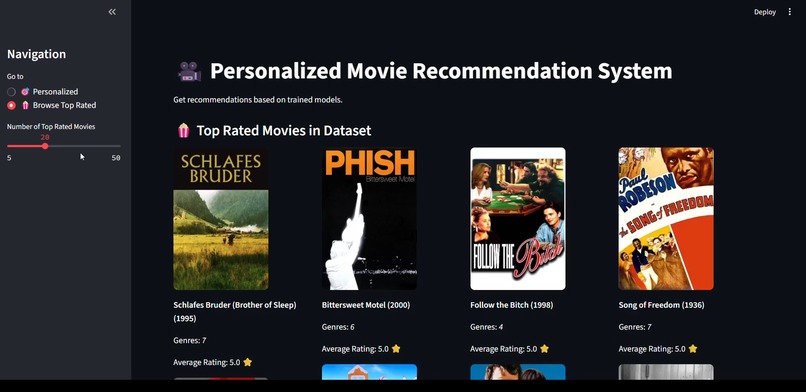
Top rated movie recommendation

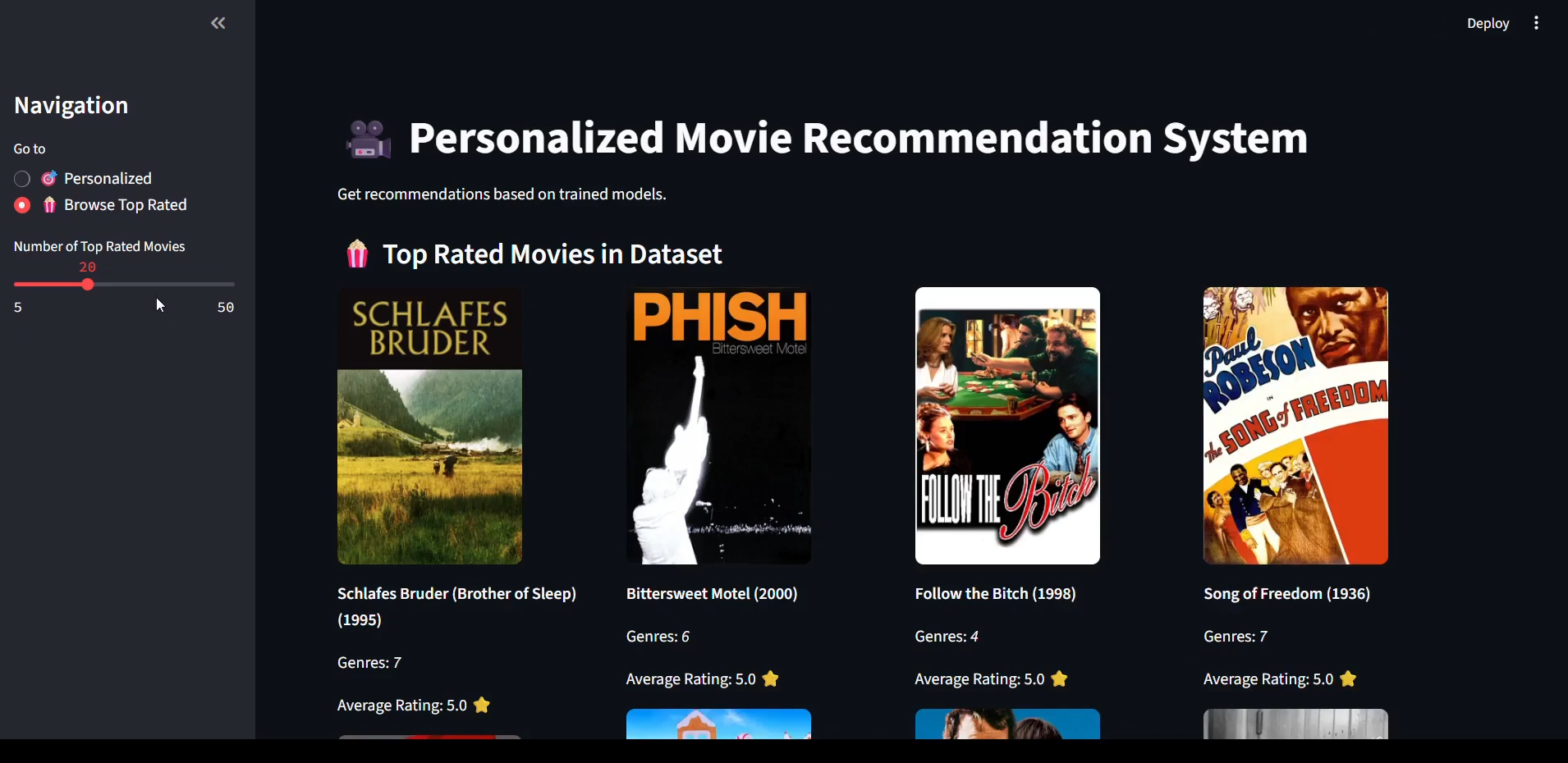
🎬 CinePick - Hybrid Movie Recommendation System
A personalized movie recommender that leverages Collaborative Filtering, Matrix Factorization (SVD & NMF), and Content-Based Filtering using movie genres. Built with Python, powered by Surprise, scikit-learn, and deployed using Streamlit.
📌 Inspiration
The sheer volume of movies available today makes it overwhelming for users to decide what to watch next. Our inspiration came from wanting to combine the best of multiple recommendation approaches into one system — CinePick — a platform that not only understands user preferences but also adapts dynamically to different viewing patterns.
💡 What it does
CinePick analyzes a user's past ratings, compares them with others, and recommends movies that align with their tastes.
It combines:
- Collaborative Filtering (User-Based & Item-Based)
- Matrix Factorization (SVD & NMF)
- Content-Based Filtering using movie genres and TF-IDF
- Hybrid Approach blending these models for optimal recommendations
It also provides:
- Predicted ratings for unseen movies
- Movie posters, genres, and key details
- Evaluation metrics like RMSE, MAE, and Precision@K
🛠️ How we built it
- Dataset — MovieLens dataset with movie metadata and user ratings
- EDA — Explored trends in ratings, genres, and user behavior
- Model Development
- Collaborative Filtering (User & Item-based) using Surprise
- Matrix Factorization (SVD, NMF)
- Content-Based Filtering with TF-IDF on genres
- Collaborative Filtering (User & Item-based) using Surprise
- Hybrid Model — Combined collaborative and content-based outputs
- UI — Interactive dashboard using Streamlit to browse recommendations
- Deployment — Packaged and made ready for local/online use
✅ Accomplishments that we're proud of
- Successfully fetched and mapped poster images for over 5,000+ movies
- Implemented resume functionality to avoid starting over on interruption
- Handled errors gracefully using fallback poster URLs
- Progress saved after every movie to ensure data integrity
⚠️ Challenges we ran into
- API rate limits and occasional TMDB search mismatches
- Handling movie title variations and special characters
- Notebook freezing due to long network waits or failed API calls
- Maintaining consistent format while resuming progress
📘 What we learned
- How to integrate and query external APIs (TMDB) using Python
- Using pandas efficiently for data handling and incremental CSV updates
- Error handling and retry logic for robust automation
- Importance of saving intermediate progress in large data tasks
🔮 What's next for CinePick
- Add filters for release year, genre, and minimum rating
- Integrate user authentication for personalized sessions
- Use deep learning-based recommendation models
- Deploy as a web app accessible globally
- Include real-time user feedback to improve recommendations
📁 Dataset
MovieLens Dataset
Includes user ratings, movie titles, genres, and timestamps.
movies.csv— movie_id, movie_title, movie_genres, poster_urlratings.csv— user_id, movie_id, user_rating, timestamp
Dataset Source: MovieLens
🛠️ Tools & Technologies Used
Languages & Frameworks:
Python, Streamlit
Libraries & Models:
- 📚 Pandas, NumPy, Scikit-learn
- 🎯 Surprise (SVD, NMF, KNNBasic)
- 🧾 TfidfVectorizer (for genre similarity)
- 📈 Seaborn, Matplotlib
Version Control:
Git, GitHub
Environment:
Jupyter Notebook, VS Code
📦 Installation
Clone the repository
git clone https://github.com/yourusername/movie-recommender.git cd movie-recommender
Create and activate virtual environment (optional but recommended)
python -m venv venv source venv/bin/activate # On Windows: venv\Scripts\activate
📌 Install required libraries
pip install -r requirements.txt
▶️ Running the App
streamlit run app.py Then, open the link provided by Streamlit in your browser.
🧪 Evaluation Metrics
Each model is evaluated using: RMSE (Root Mean Square Error) MAE (Mean Absolute Error) Precision@K (for top-N recommendations)
🔄 Recommendation Logic
Collaborative Filtering: Based on user-user or item-item similarity from historical ratings. Matrix Factorization: Learns latent features using SVD/NMF. Content-Based: TF-IDF vectorization of genres and cosine similarity. Hybrid: SVD predictions + fallback to content similarity if needed.
🤝 Contributors
Indu M Gopika Gokulanadh Ardra Pradeepkumar S. Rajalakshmi
Built With
- csv
- git
- github
- matplotlib
- movielens-dataset
- nmf
- numpy
- os
- pandas
- python
- random
- scikit-learn
- seaborn
- streamlit
- surprise
- svd
- time
- tmdb-api
- tqdm
- visual-studio
- vscode


Log in or sign up for Devpost to join the conversation.