-

Basic example of good movies it recommends.
-
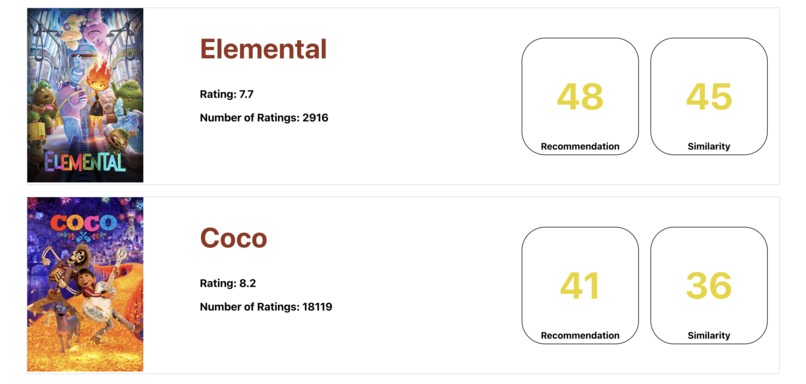
Lower movies on the list for the same input as the last.
-

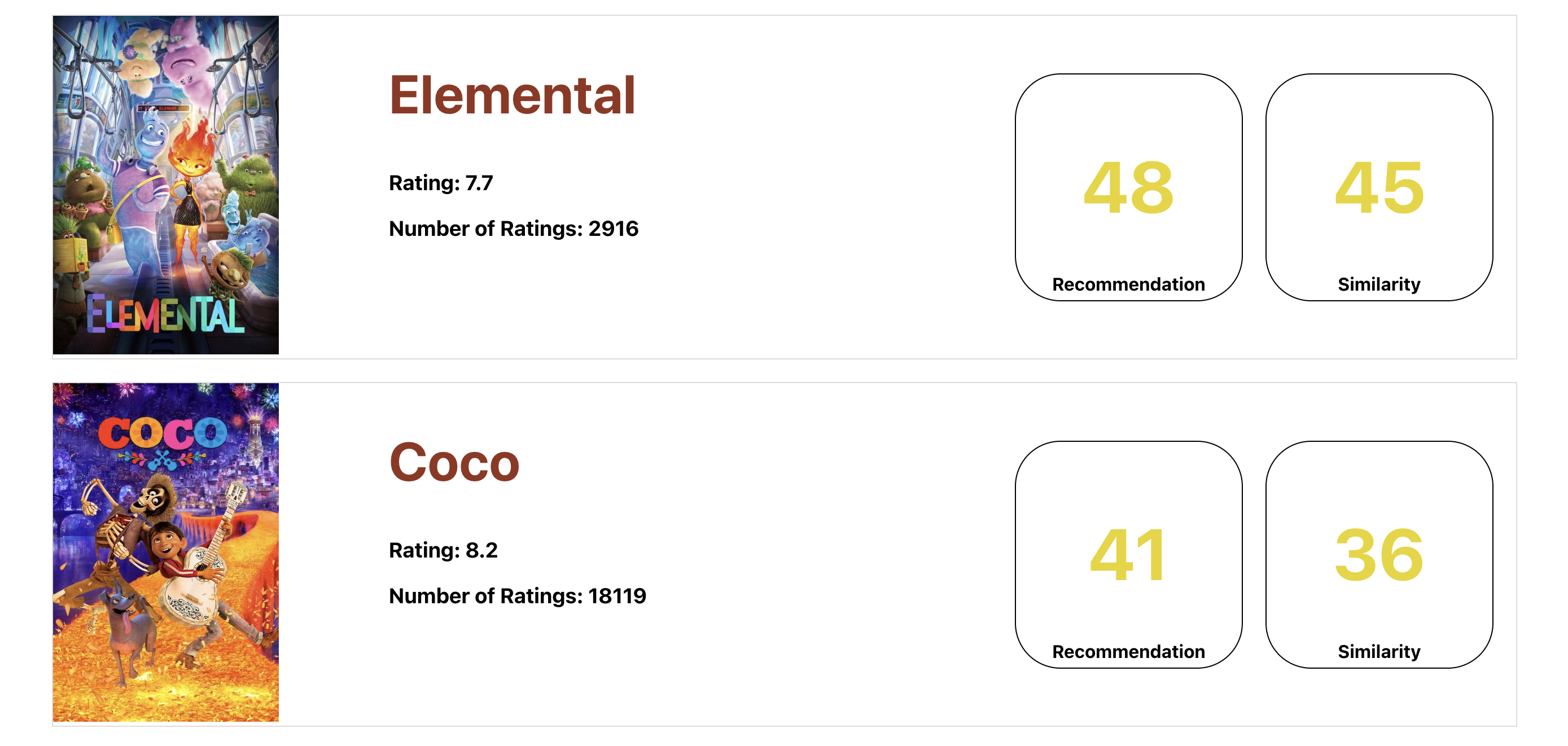
Very specific input gives back a very unique movie


Inspiration
We have all spent far too long scrolling on Netflix, not knowing what to watch. We figured it would be good if we just could describe the type of movie we wanted to watch, that way we take the guess work out of it.
What it does
Simply just type your description of what you want to watch and our code use natural language processing to give you a list of 50 movies it recommends you watch.
How we built it
We used a Python backend and JS/React front end. Our python backend uses TMDB API to retrieve movie data, including synopses, written reviews, and other important movie metrics. We then use self-implemented natural language processing code in order to find similarities between the user input and the movies we have access to. The code then returns a list of movies it recommends and our front end formats it all.
We hosted the final website on Github Pages and the backend REST service on PythonAnywhere.
Challenges we ran into
We had a lot of problems due to the fact that there is so much data for us to use and API calls and some of our algorithms were slow and inefficient to start. We leveraged the fact that we knew our NLP data would be a sparse matrix and therefore we could effectively decompose its data into a smaller size, which is easier and quicker to work with. This cut our number of computations down dramatically.
Another problem that is really relevant to our project was that to our knowledge, we don't think anybody has used NLP to solve a problem like this before. Because of that, we needed to "invent some math" and make some assumptions about our model in order for it to hopefully work correctly.
We struggled how our NLP algorithms actually determined similarity of words. There were issues with how different attributes were weighted and there were many times when our code return a couple movies that theoretically shouldn't have been considered similar to our input test.
We struggled a lot with deploying our website because this is the first time any of us had done that before. We were fine when we hosted the site locally, however, when we tried to use our domain name cinematch.tech to create and deploy our code online, it was far more in depth than we all imagined. We had some trouble configuring PythonAnywhere due to idiosyncrasies of its systems that caused our pre-existing code to malfunction. However, in the end, we deployed it successfully to Github Pages and PythonAnywhere, and the app is fully functional at either of the links in the links section.
Many of our troubles came from the fact that python let's you get away with a lot when it comes to syntax. We had many many bugs that were seemingly impossible to find because python just allowed it and it seemingly fit right in.
Accomplishments that we're proud of
Honestly, the thing we are most proud of is that we finished our project. We weren't sure coming into this that we would even get anywhere close to a finished product.
We are also proud of the fact that we didn't simply just use AI or made a wrapper around ChatGPT or some other large language model. Instead, we developed our own NLP model ourselves from scratch, which like we said above had many challenges to it.
We are also proud of how clean the site looks, given the time limit and the fact that none of us specialize in front-end development or React.
What we learned
We learned a lot of stuff about NLP. A lot of this project for all of us was very new to us. We came in with a general idea and a gut feeling about a path to follow and we took steps to get to the finish bit by bit.
What's next for CineMatch.tech
We would like to continue to polish our code and front-end in general. However, we specifically want to continue testing and improving our NLP methods. This is because we definitely see a general correlation between the input text we give and the list of movies it returns, however, there is definitely room for improvement for some of the recommendations it gives.
We also notice that our website can be a little slow when fetching the movie list from our large database. We have plans on how to speed up these computations by a couple of different means. One of which is using a technique to drastically reduce our sample size of movies we have to compare in our Vector Space. The other is that we understand that python isn't exactly the fastest programming language, so we plan to reprogram all of our code into a faster language so that user experience is better.





Log in or sign up for Devpost to join the conversation.