-
-
Landing
-
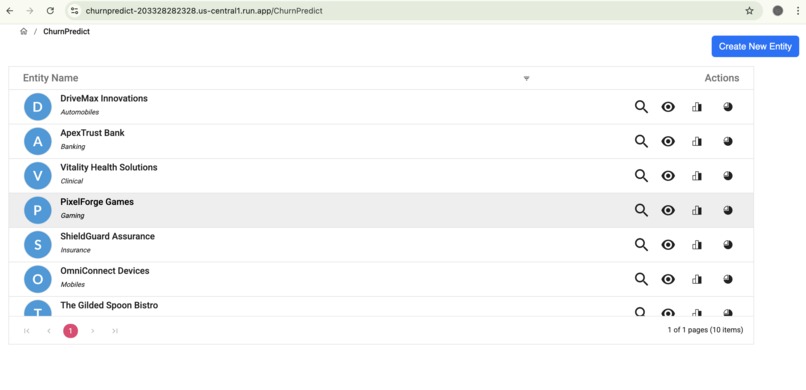
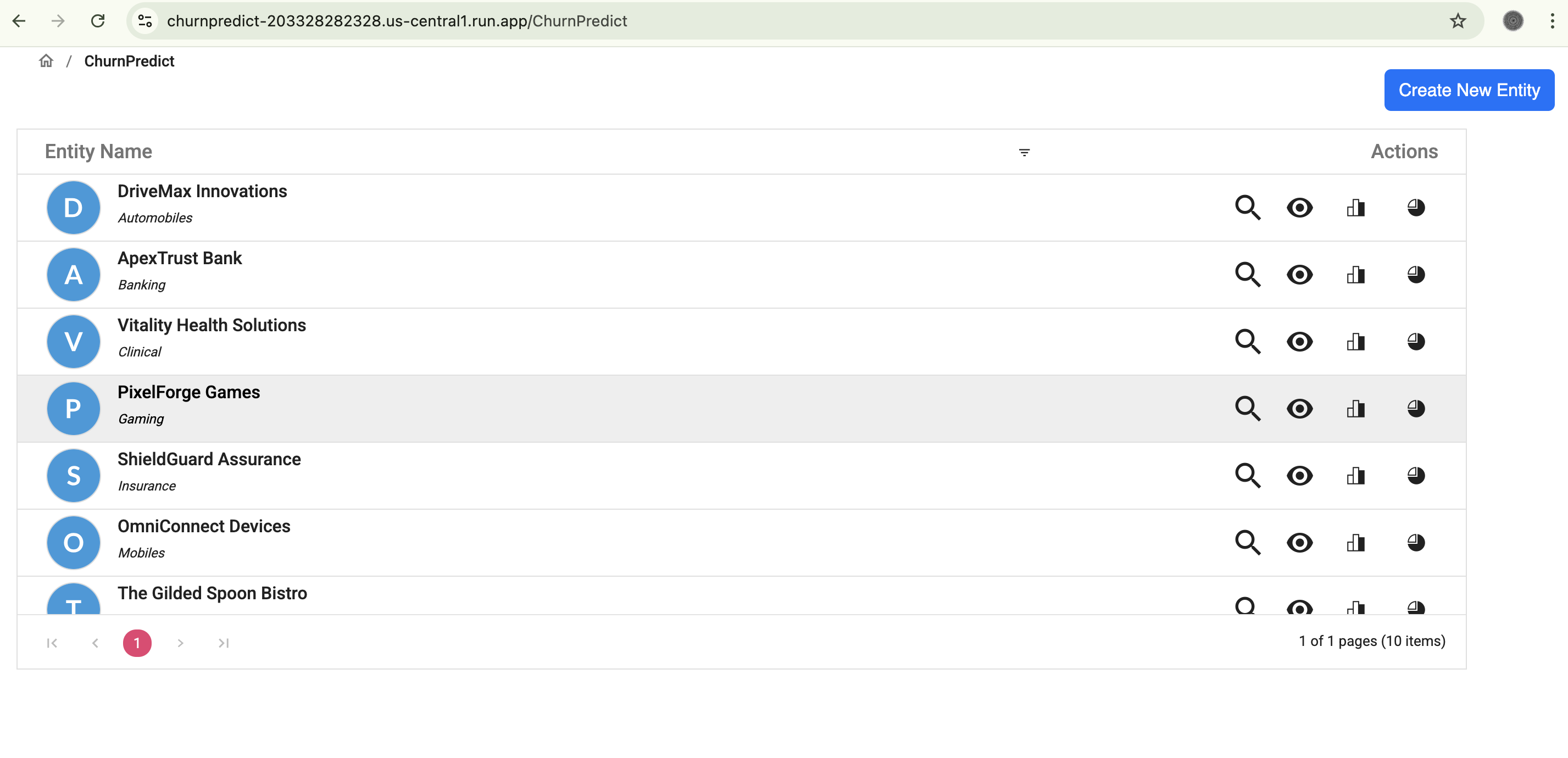
Entities List from Mongo DB
-
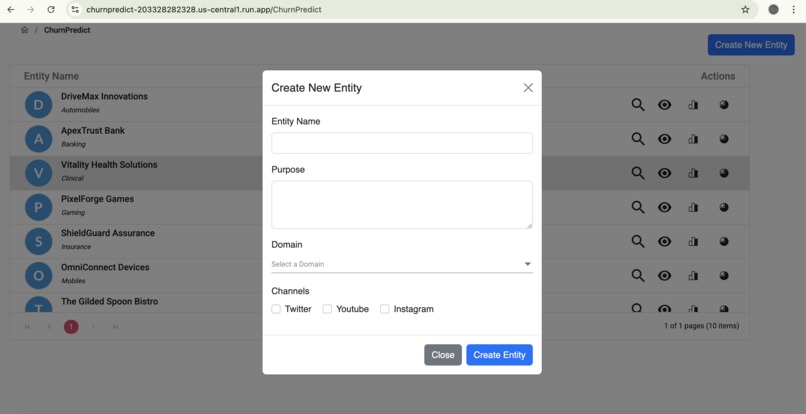
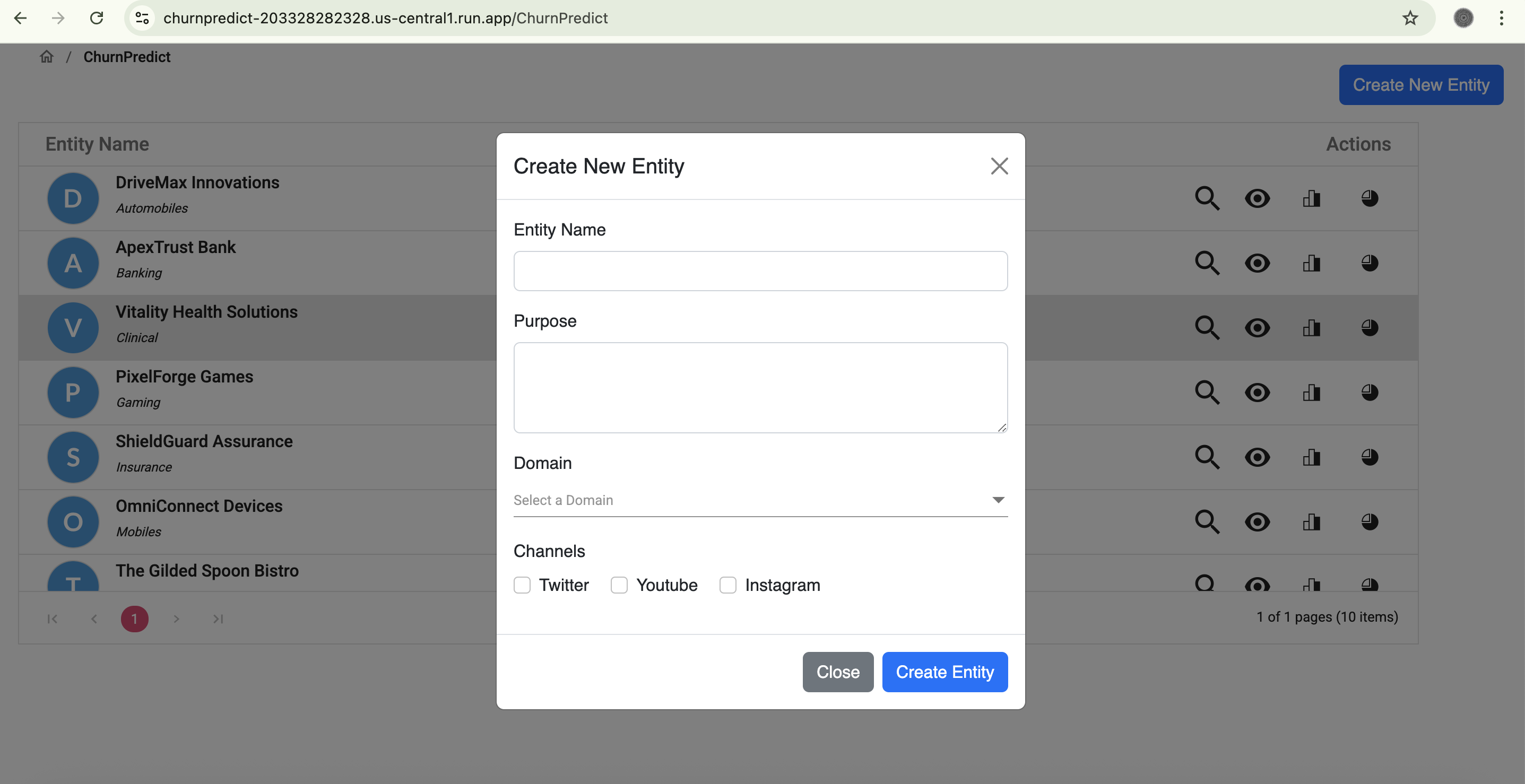
New Entity Registration
-
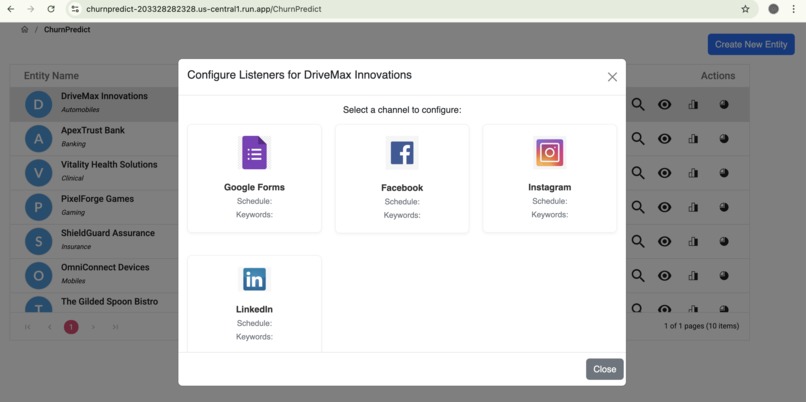
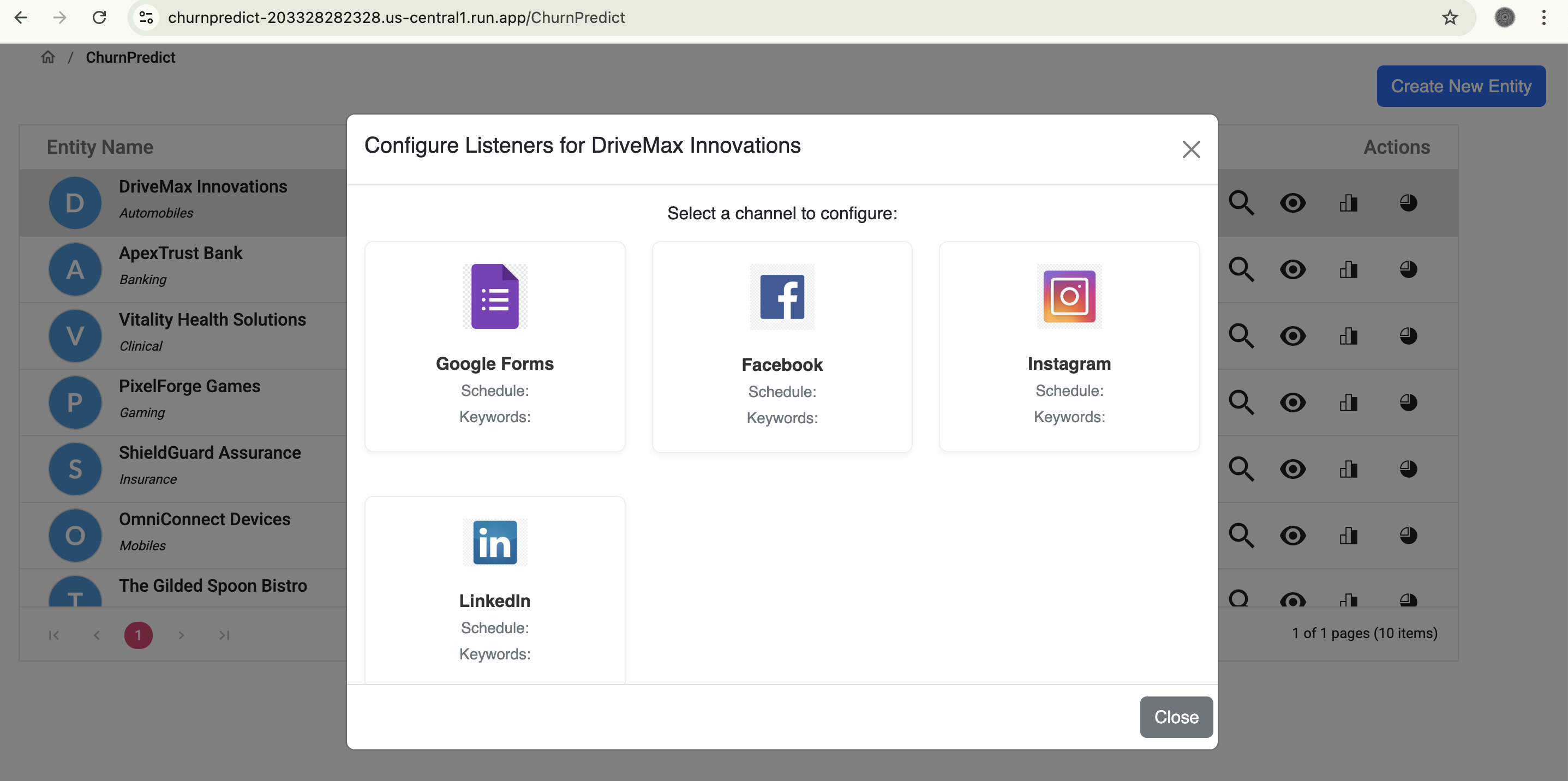
View Channel Selection
-
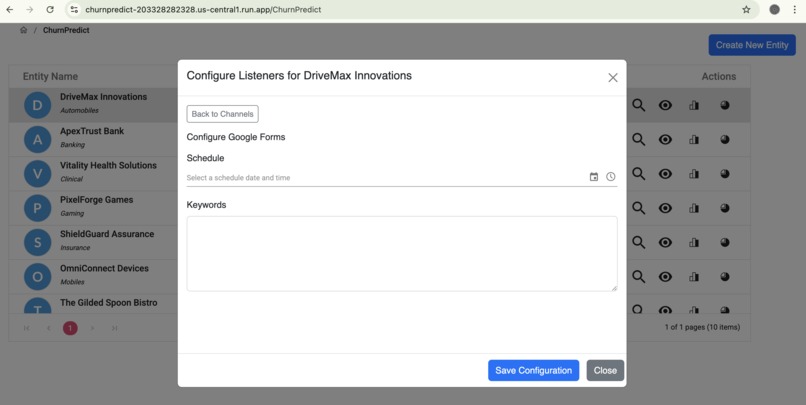
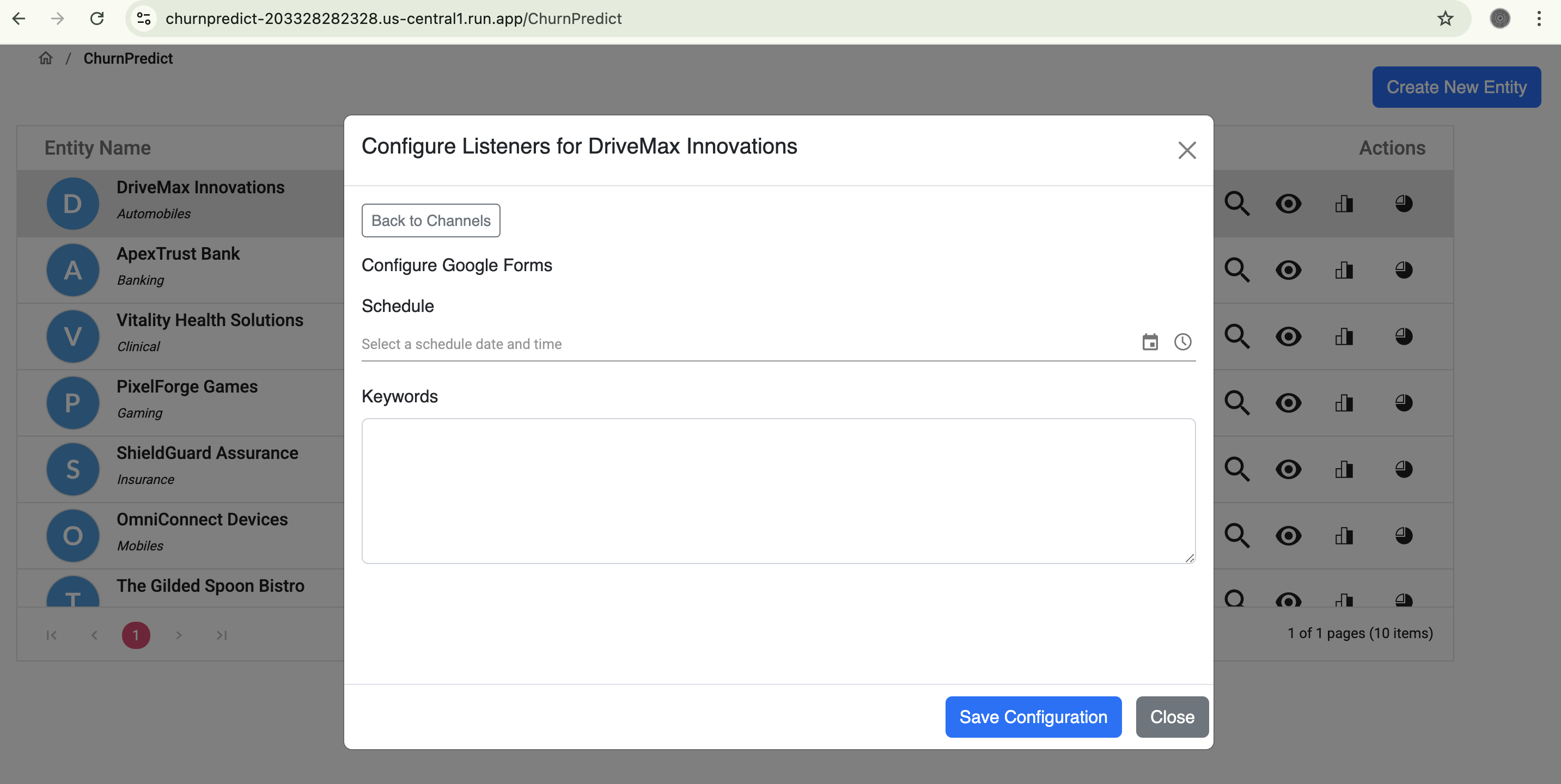
Channel Schedule Configuration
-
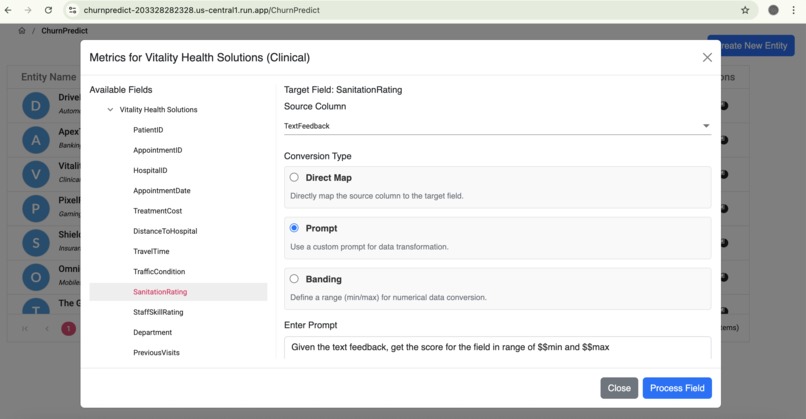
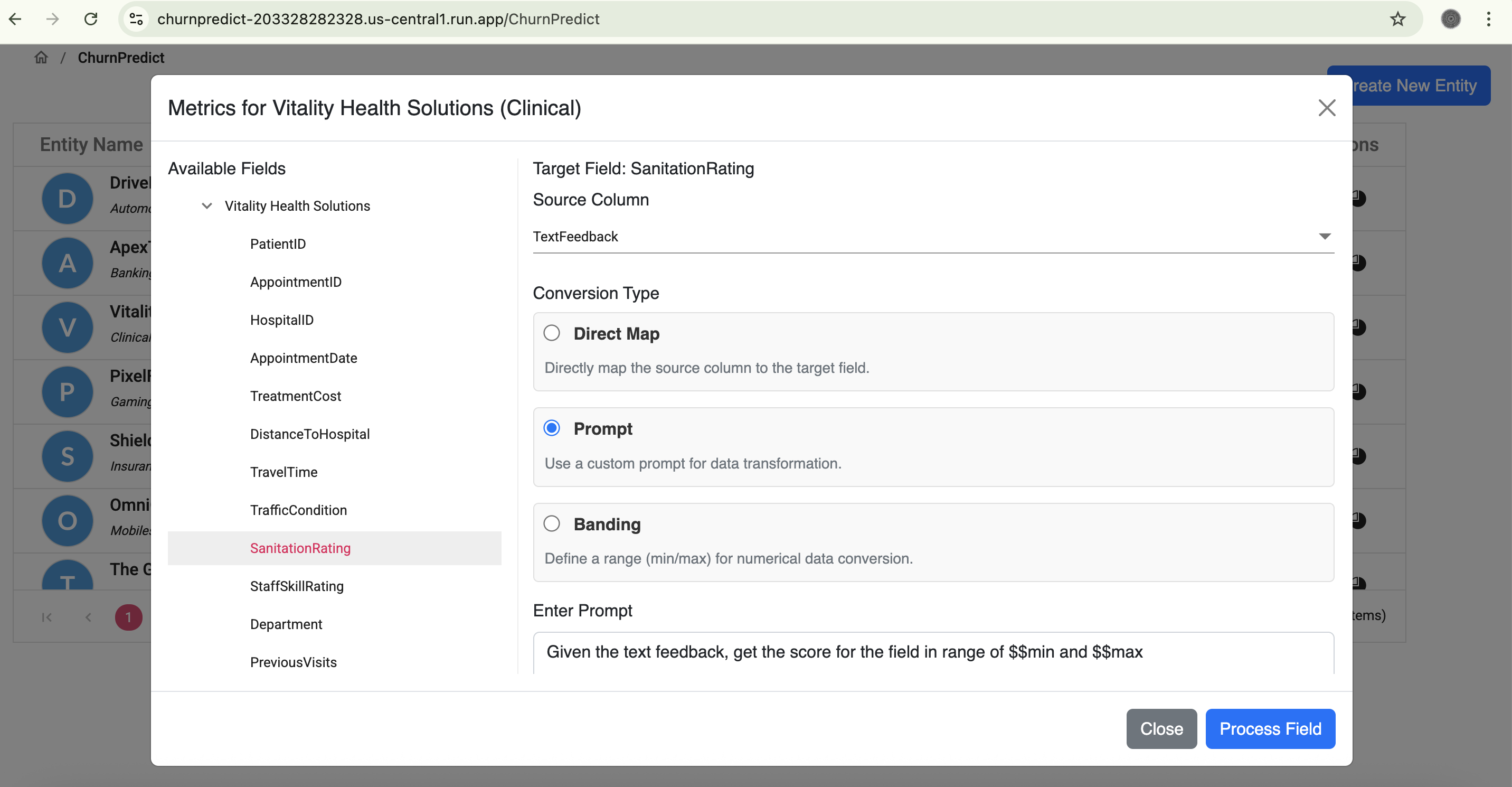
Data Normalisation from text feedback
-
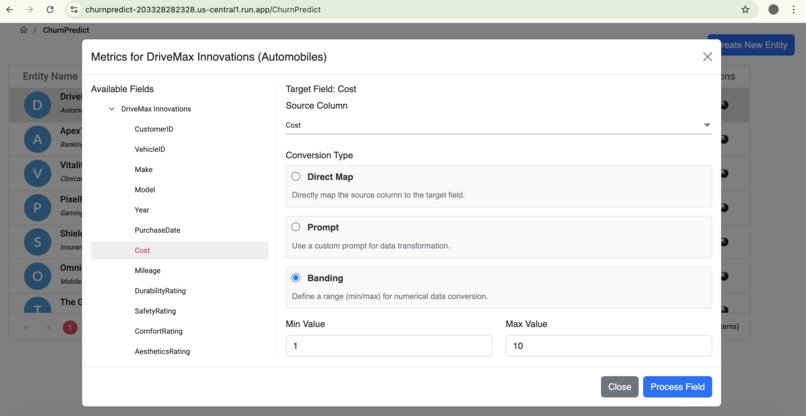
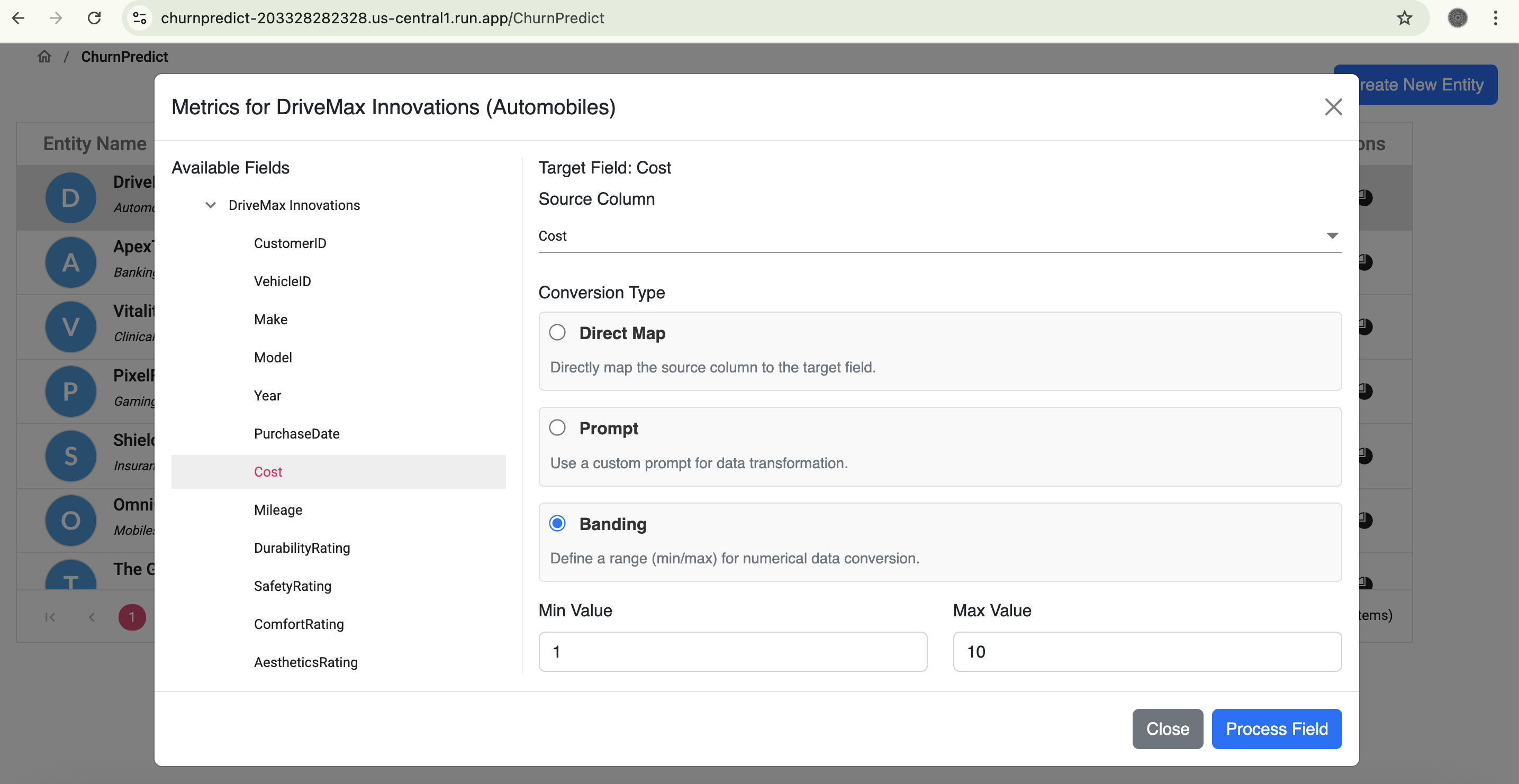
Data Normalisation from range
-
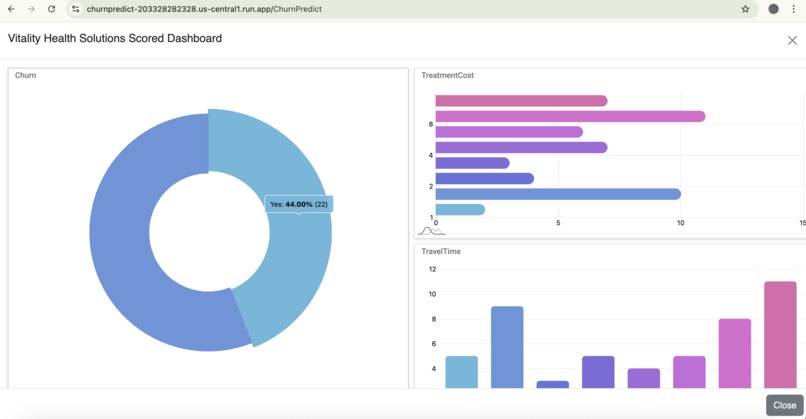
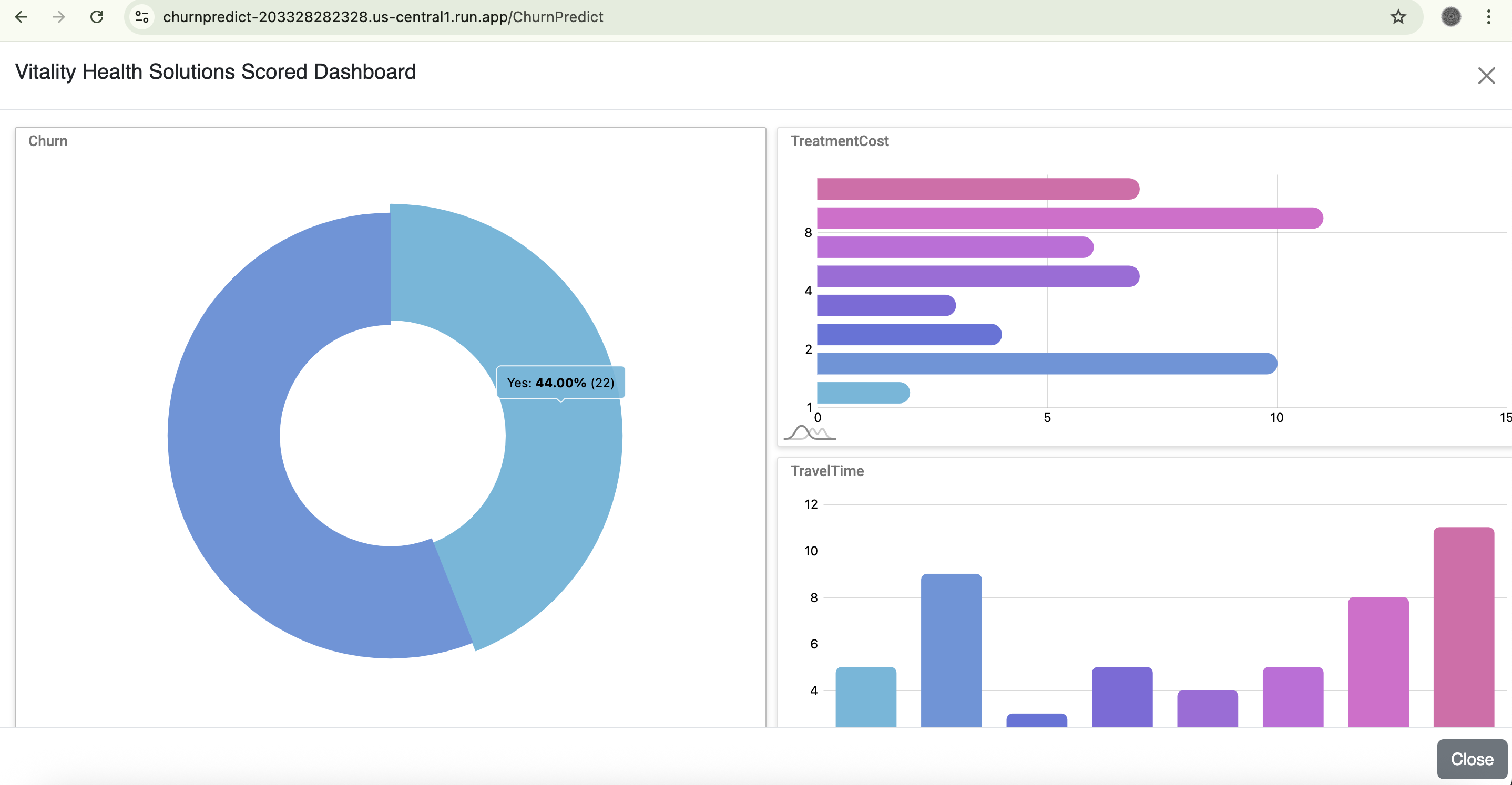
Churn Insights Dashboard
-
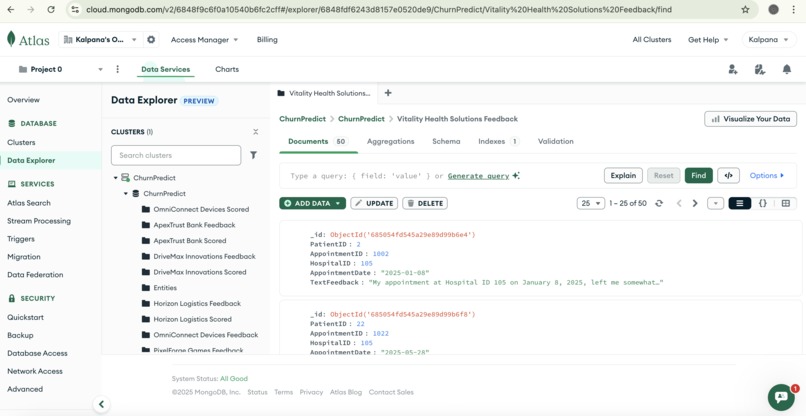
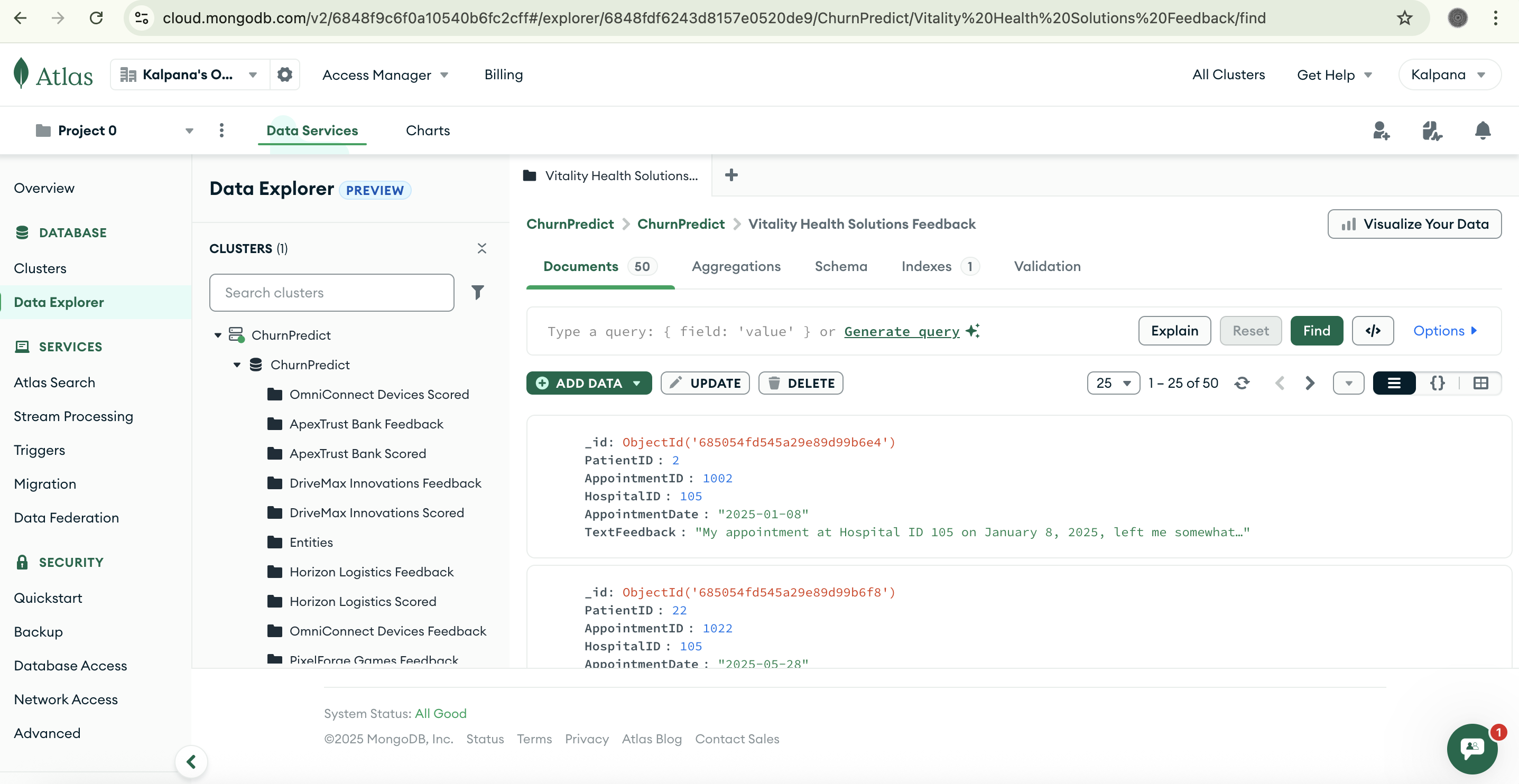
Data stored in Mongo DB
💡 Inspiration
In today's competitive landscape, customer churn is a critical challenge across all industries. Businesses often struggle to understand why customers leave, especially with the explosion of unstructured feedback like reviews, social media comments, and support tickets. We were inspired to build a universal solution that could tap into this rich, often-ignored data source, providing actionable insights for proactive customer retention and engagement, regardless of the domain.
⚙️ What it does
ChurnPredict is a domain-agnostic platform designed to predict customer churn and customer propensity for various behaviors. It streamlines the entire process from data ingestion to actionable insights:
- Flexible Data Ingestion: Upon registration, entities or businesses can easily configure and connect to multiple data channels (e.g., Google Forms, Twitter, YouTube, Facebook). Users define collection schedules (daily, weekly, etc.) and specify keywords for our engine to search and collect relevant feedback.
- Transparent Data Management: All collected raw feedback data is securely stored in MongoDB. Users gain full visibility through a data preview UI, allowing them to inspect the incoming information.
- Intelligent Data Normalization & Mapping: We transform raw feedback into a normalized dataset, critical for accurate predictions. For each domain, we provide a set of predefined target columns. A dedicated mapping screen allows users to connect source data to these targets using three flexible methods:
- Direct Map: For straight value transfers.
- Banding: For scaling data into defined min/max ranges.
- Prompt (Gemini-powered): Leveraging the Gemini LLM, we generate a nuanced score within a configured min/max range based on the sentiment and content of text feedback, uncovering deeper context.
- Machine Learning for Churn Prediction: The core of our predictive power lies here. We leverage this rich, normalized dataset to train a Logistic Regression machine learning model specifically for churn prediction. This trained model is then used to forecast the likelihood of customer churn, providing vital proactive insights.
- Actionable Insight Dashboards: The platform culminates in a comprehensive dashboard. This dashboard clearly presents churn predictions from our ML models, current churn rates, and various statistical insights, enabling businesses to understand trends and make informed decisions to retain customers and drive desired actions.
By leveraging the advanced capabilities of Google's Gemini LLM and robust ML models like Logistic Regression, ChurnPredict uncovers deep insights into customer sentiment, satisfaction, and pain points, effectively explaining the "why" behind their behavior.
🏗️ How we built it
Our core technology stack is robust and scalable, deployed entirely on Google Cloud:
- Backend: Developed with Python and Flask, providing a powerful and flexible API for managing channel integrations, scheduling data collection, performing data transformations (including mapping logic), serving the Logistic Regression machine learning model, and interacting with the frontend.
- Data Storage: MongoDB serves as our primary database, ideally suited for handling diverse raw and normalized unstructured customer data. It efficiently stores raw feedback, mapped datasets, and prediction results.
- Data Ingestion & Scheduling: Custom Python modules manage API integrations with various social media and survey platforms, allowing configurable scheduling and keyword-based data pulls.
- Unstructured Data Processing & Scoring: The Gemini LLM is integrated via Flask. It's central to evaluating feedback, especially for the "Prompt" mapping method, where it generates scores from text, extracting sentiment and nuanced insights. This feeds into our normalization process.
- Data Normalization & Mapping Engine: A sophisticated data pipeline in Python handles the transformation from raw to normalized datasets, implementing "direct map," "banding," and the "Prompt" (Gemini-driven) scoring logic. The mapping screen is built into the frontend, interacting with this backend logic.
- Machine Learning Pipeline: We developed a dedicated ML pipeline using Python libraries (e.g., scikit-learn) to train, evaluate, and fine-tune our Logistic Regression model on the normalized dataset. This model is then exposed via Flask APIs for real-time or batch churn predictions.
- Frontend: A user-friendly web interface is built to allow businesses to register, configure channels, define keywords, preview data, manage data mappings, and visualize churn probabilities from our Logistic Regression model, current churn, and various statistical insights on interactive dashboards.
- Deployment: The entire application is containerized and deployed on Google Cloud Run, providing exceptional scalability, cost-effectiveness, and operational simplicity. This ensures ChurnPredict can handle varying workloads efficiently without manual server management.
🗺️ Architecture Diagram
Below is a high-level representation of ChurnPredict's architecture, illustrating the flow of data and interaction between its core components.

⚠️ Challenges we ran into
Developing ChurnPredict presented several exciting challenges:
- Diverse Channel Integration & Scheduling: Building robust, reliable connectors to various external platforms (Twitter, Facebook, Google Forms etc.) with flexible scheduling and keyword filtering proved complex due to API rate limits, data format variations, and authentication flows.
- Handling Diverse Unstructured Data: Normalizing and extracting meaningful features from vastly different unstructured data types (restaurant reviews, medical complaints, telecom satisfaction notes, images) was complex. Gemini's flexibility was key here, but ensuring consistent scoring across varied contexts was a significant task.
- Domain Agnosticism & Flexible Mapping: Designing a data normalization engine that could genuinely adapt to distinct industry vocabularies, churn definitions, and data nuances through the "direct map," "banding," and "Prompt" methods required careful architectural planning and a highly flexible mapping screen in the UI.
- Integrating Gemini LLM at Scale for Scoring: Ensuring efficient and performant communication with the Gemini LLM for real-time text-to-score generation within the Flask environment for the "Prompt" mapping method, while maintaining accuracy, required careful optimization.
- Building Robust & Accurate ML Models: While Logistic Regression offers good interpretability, selecting and fine-tuning it to perform consistently and accurately across diverse domains, especially when leveraging features derived from highly unstructured data processed by an LLM, presented specific challenges in feature engineering and model validation.
- Dashboarding & Insight Generation: Presenting complex churn predictions, current churn, and diverse statistical insights in a clear, intuitive, and actionable dashboard format that caters to various business users.
✨ Accomplishments that we're proud of
We are immensely proud of several key accomplishments:
- Robust Multi-Channel Data Ingestion: Successfully implemented a flexible system allowing businesses to connect and schedule data collection from diverse sources like Google Forms, Twitter, YouTube, and Facebook using configurable keywords.
- Intelligent Data Normalization & Mapping: Developed a sophisticated data normalization pipeline with a user-friendly mapping interface, enabling "direct map," "banding," and Gemini-powered "Prompt" scoring for tailored, domain-specific datasets.
- Successful Gemini LLM Integration for Deeper Insights: Seamlessly integrated Gemini to process and derive valuable scores and insights from highly unstructured data (text and images), directly contributing to our normalized dataset and the "why" behind customer behavior.
- Accurate & Adaptable ML-Powered Churn Prediction: Successfully built and deployed a Logistic Regression model that leverages our normalized, LLM-enriched data to provide highly accurate and adaptable churn predictions across various domains.
- True Domain Agnosticism: Building a flexible data ingestion, processing, and analysis pipeline that genuinely adapts across diverse domains like Medical, Transport, and Education.
- Comprehensive & Actionable Dashboards: Delivering insightful dashboards showing churn prediction, present churn, and various statistical insights, providing immediate value to businesses.
- Scalable Google Cloud Deployment: Deploying the entire solution on Cloud Run demonstrates our ability to build and deploy highly scalable, cost-effective, and low-maintenance applications.
📚 What we learned
This project provided invaluable learning experiences:
- The Power of Configurable Ingestion: We learned the critical importance of giving users control over data sources, schedules, and keywords for truly flexible and relevant data collection.
- Importance of Flexible Data Transformation: Understanding that raw data needs intelligent, configurable normalization (like our "direct map," "banding," and "Prompt" methods) to be truly useful for predictive modeling across domains.
- Deep Value of LLMs in Feature Engineering: We gained a deeper appreciation for how large language models like Gemini can revolutionize the way businesses process and derive numerical scores and features from previously inaccessible unstructured text data for machine learning.
- Effective Use of Logistic Regression for Churn: We gained valuable insights into optimizing Logistic Regression models for churn prediction on diverse datasets, particularly when incorporating LLM-derived features, balancing its interpretability with predictive power.
- Managing Data Lifecycle in MongoDB: The nuances of storing, previewing, and transforming both raw and processed data efficiently within MongoDB for a complex application.
- Google Cloud Ecosystem for End-to-End Solutions: We solidified our expertise in leveraging various Google Cloud services for optimal performance, scalability, and developer experience, from ingestion to deployment.
🚀 What's next for ChurnPredict
The future of ChurnPredict is exciting! Our next steps include:
- Expanding "Prompt" Mapping Capabilities: Enhancing Gemini's role in data mapping to include more complex entity extraction, relationship identification, and multi-modal scoring (e.g., combining text and image analysis for a single score).
- Predictive Action Recommendations: Developing a recommendation engine that suggests specific, automated actions or interventions based on predicted churn or propensity scores, linked directly to the channels used for feedback.
- Advanced Explainability in Dashboards: Enhancing the explainability of our ML models (including Logistic Regression's coefficients and feature importance) and dashboard insights, providing users with clearer, interactive breakdowns of which factors (including insights from unstructured data) are most influencing churn and propensity predictions.
- ML Model Customization & Exploration: While Logistic Regression is our current core, we plan to explore and potentially integrate other advanced ML models to offer more options or higher performance for specific complex scenarios, or even allow enterprises to fine-tune existing models.
- Two-Way Channel Integration: Beyond just reading data, exploring options to push targeted messages or offers back through connected channels based on ChurnPredict's insights (e.g., sending a retention offer via Facebook Messenger to an at-risk customer).
- Real-time Stream Processing: Investigating the adoption of real-time data streaming (e.g., via Pub/Sub or Kafka) for near-instantaneous feedback processing and churn updates.
Built With
- amcharts
- cloud-run
- flask
- gemini
- google-cloud
- html5
- javascript
- machine-learning
- mongodb
- python



Log in or sign up for Devpost to join the conversation.