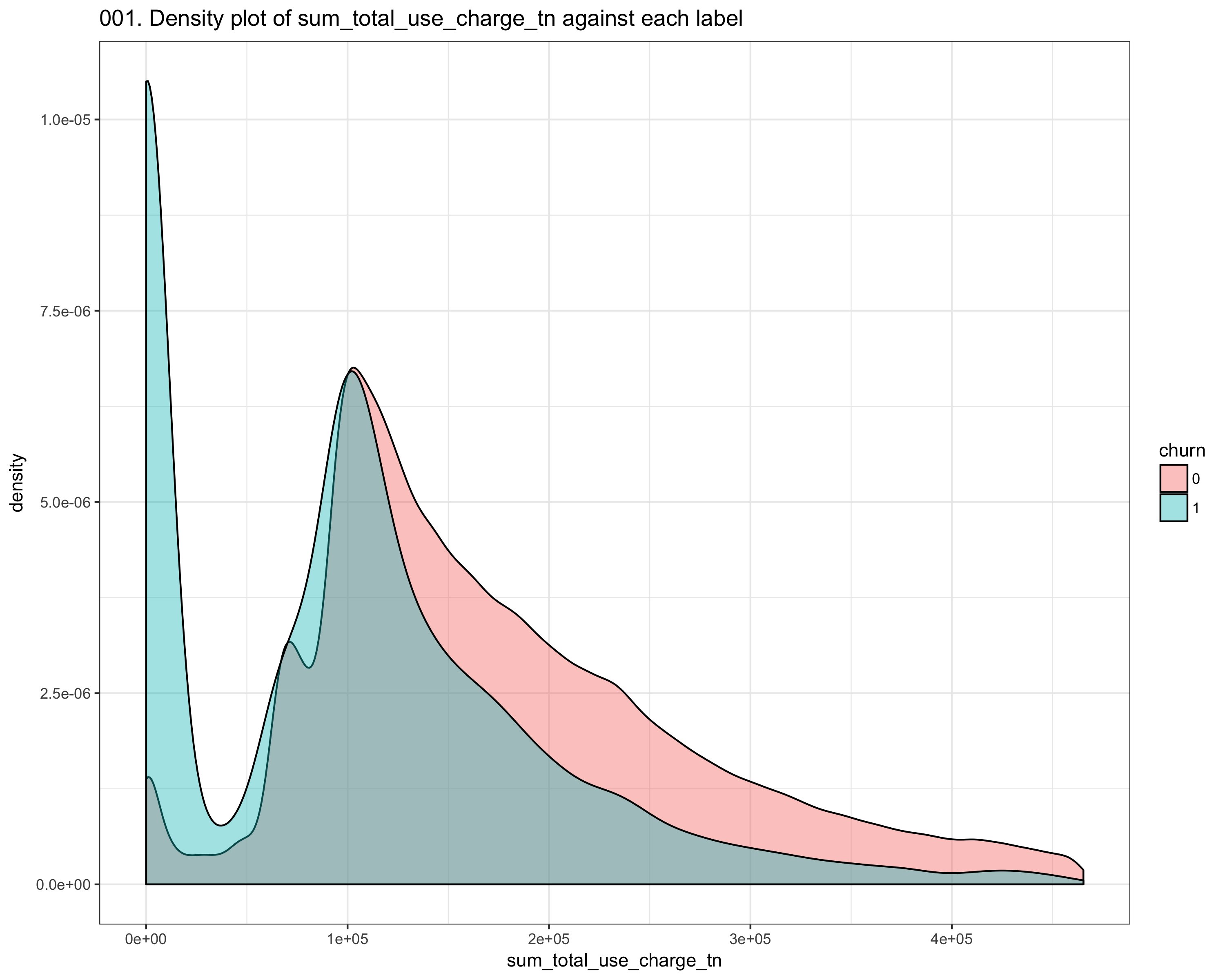
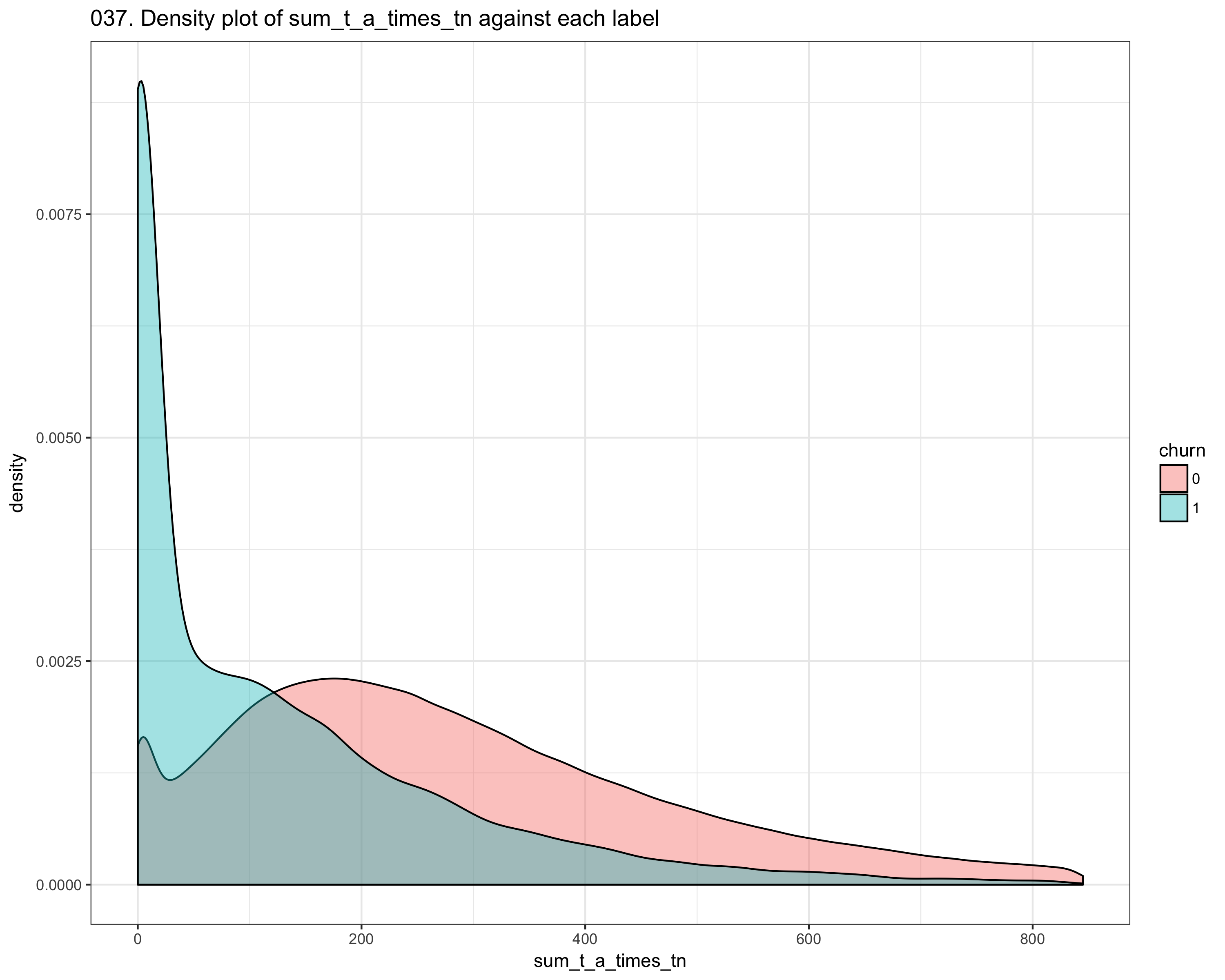
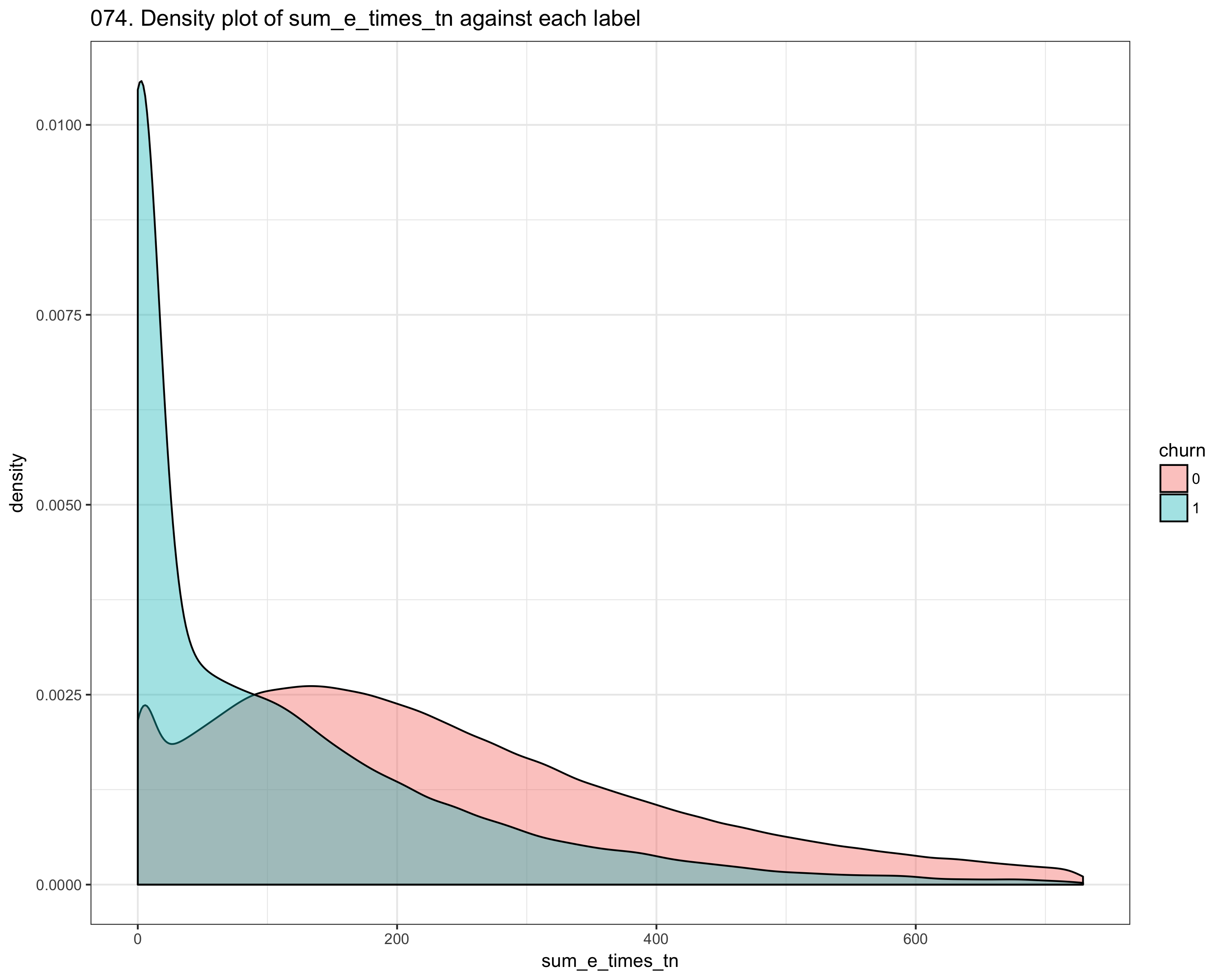
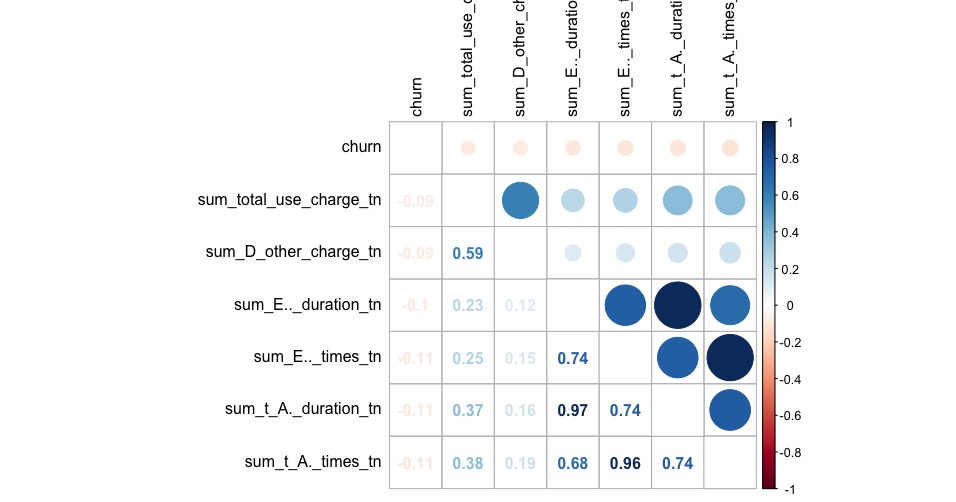
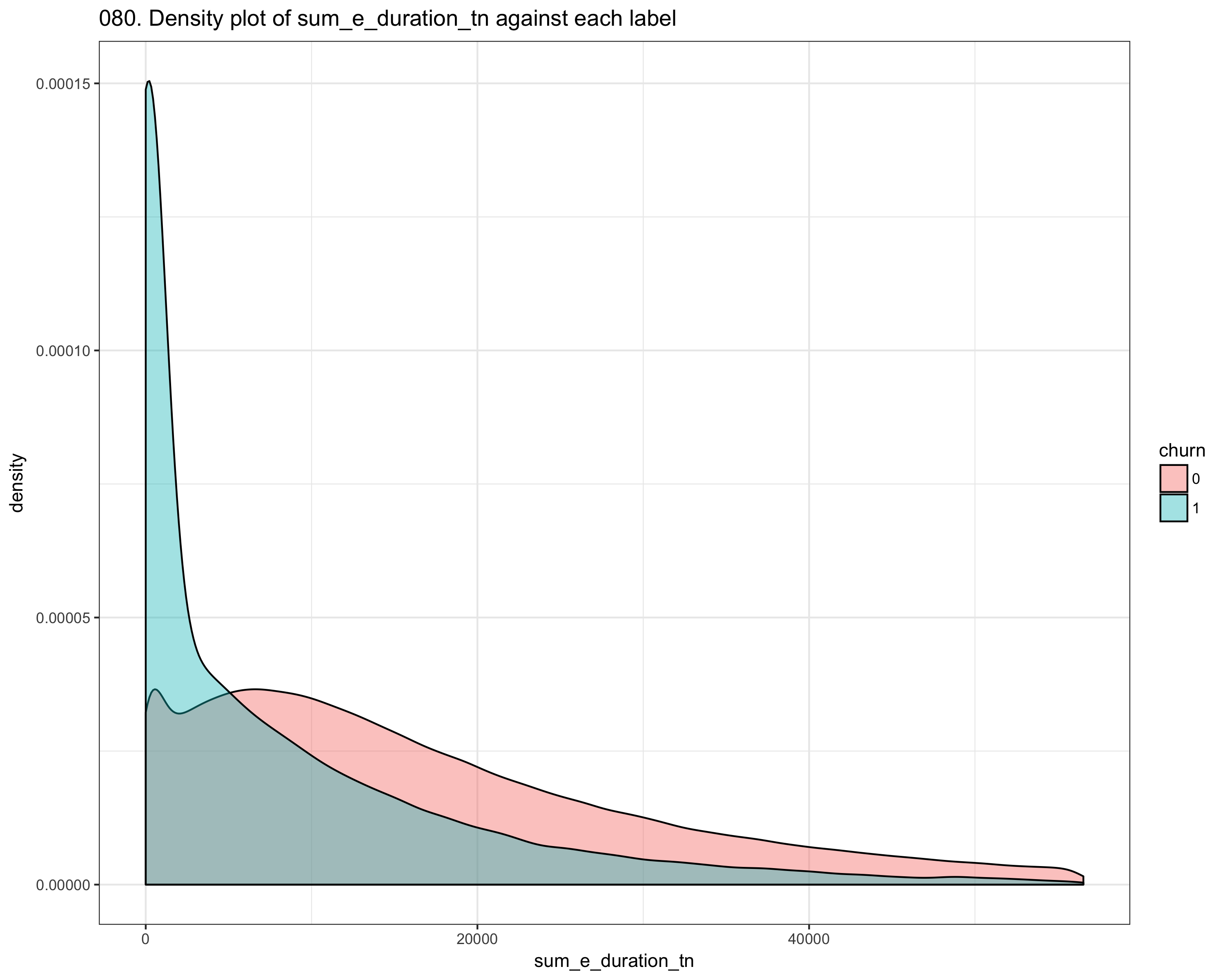
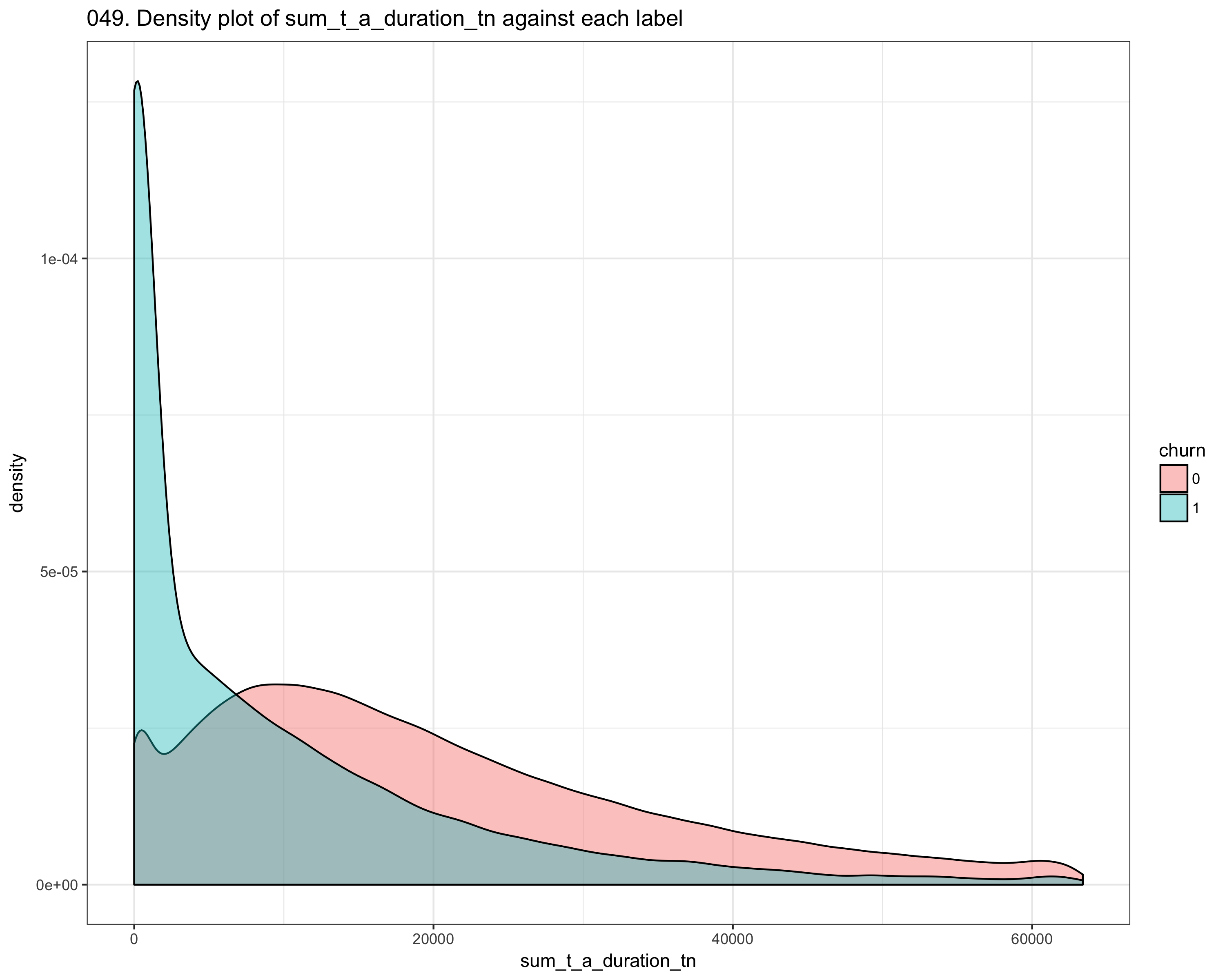
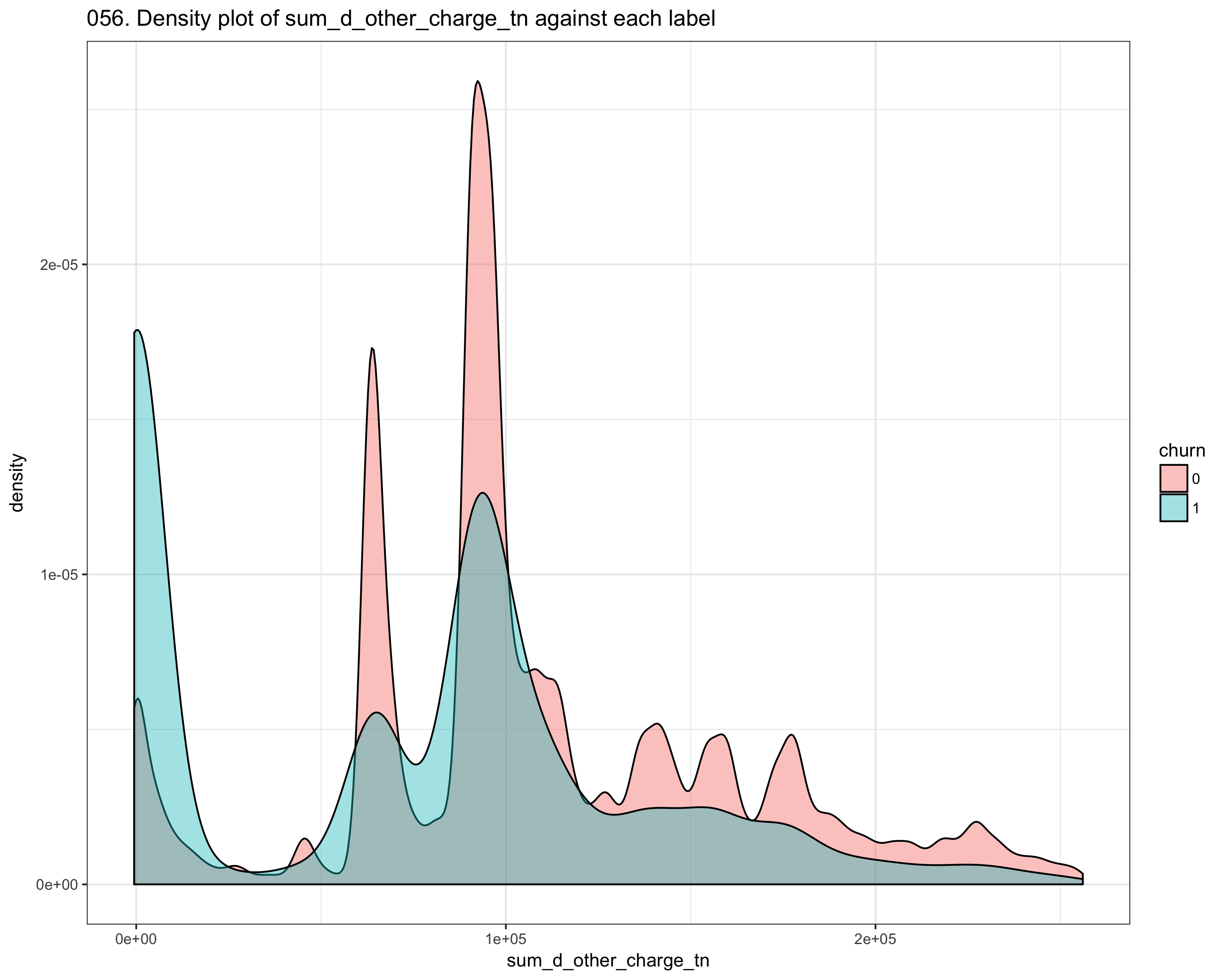
We performed intensive dataset exploration, like check if dataset has missing values, number of columns, which features are most correlated to the churn. After the first step, we performed feature engineering Since the dataset consists of time_series features, we compute the mean_difference, the std_difference of values between two consecutive points (like t_i, t_i_1) We also computer other statistics like skewness, kurtosis, and autocorrelation
After the second step, we have around 189 features
Modeling: We proposed to use XGBoost as a fast, scalable, widely-used framework for datascience
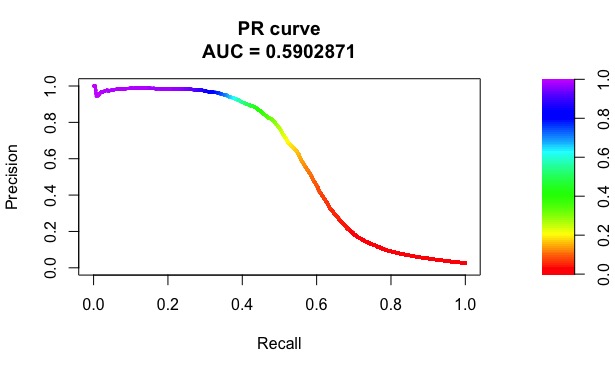
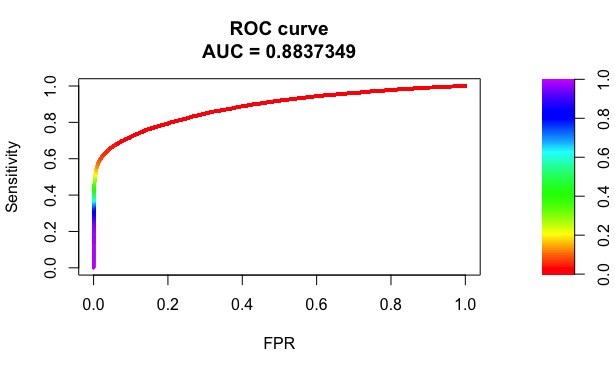
The AUC we obtained on validation set: 0.92
Slides for more information
https://docs.google.com/presentation/d/1gD8hXPdThcSAIq5T-MeJmVOez3HnDnerHspOyfpR_RA/edit?usp=sharing
Log in or sign up for Devpost to join the conversation.