-
-

Sample Result
-
Fine tuned benchmarks

Inspiration
History is fading. Millions of legal, social, and cultural documents from the Early Modern period are currently locked in physical archives, effectively invisible to the digital world. While modern OCR works perfectly on printed text, it fails catastrophically on historical handwriting due to complex calligraphy, ink bleed-through, and archaic layouts.
I was inspired by the RenAIssance initiative (GSoC) and the challenge of Digital Heritage. I wanted to answer a specific question: Can I use Vision-Language Models to bridge the 500-year gap between a 1545 scribe and a 2025 researcher?
Standard models see these manuscripts as noise. I wanted to build a system that sees them as knowledge.
What it does
Chronos-VL is an end-to-end system I developed for the digitization and understanding of historical Spanish manuscripts.
- Visual Perception: It deciphers the Rodrigo Codex (c. 1545)—a difficult Gothic script—with near-perfect accuracy, handling complex ligatures and abbreviations.
- Visual Restoration (X-Ray): It generates a dynamic "X-Ray" overlay, projecting the predicted text back onto the original manuscript in neon green, allowing historians to verify the AI's work instantly.
- Semantic Modernization: It doesn't just transcribe; it translates time. The system automatically normalizes archaic 16th-century spelling (e.g., dixo --> dijo) into Modern Spanish.
How I built it
I built Chronos-VL using a Two-Stage Pipeline architecture:
Stage 1: The Neural Layer (Perception)
- I chose Baidu's PaddleOCR-VL-0.9B for its Vision-Language capabilities, specifically its ability to handle dynamic image resolutions via NaViT architecture.
- I utilized the ERNIEKit framework to fine-tune the model on the RODRIGO Corpus, a dataset of 9,000 lines of 16th-century handwriting.
- I conducted training on an NVIDIA A100 (40GB) to handle the high-resolution visual embeddings efficiently.
Stage 2: The Logic Layer (Chronos Engine)
- I developed a custom post-processing engine in Python.
- I implemented a dictionary-based normalization algorithm to map archaic Castilian vocabulary to modern equivalents.
- I integrated
deep-translatorto provide real-time English translation of the modernized text. - I built a Gradio interface to make the tool accessible via a web browser for immediate testing.
Challenges I ran into
- The "Hallucination" Problem: Being a VLM pre-trained on the web, the model initially tried to output HTML tags (
<div>,<img>) when it encountered damaged or empty sections of the manuscript. I had to implement a strict output filtering system to sanitize these hallucinations. - Dependency Conflicts: Getting the specific CUDA drivers to play nicely with PaddlePaddle and PyTorch within the same Colab environment was a significant engineering hurdle that required precise version pinning.
- Visual Complexity: The "Long S" (f vs s) ambiguity in 1545 script confused the base model entirely. Fine-tuning was the only way I could teach the model this specific historical context.
Accomplishments that I'm proud of
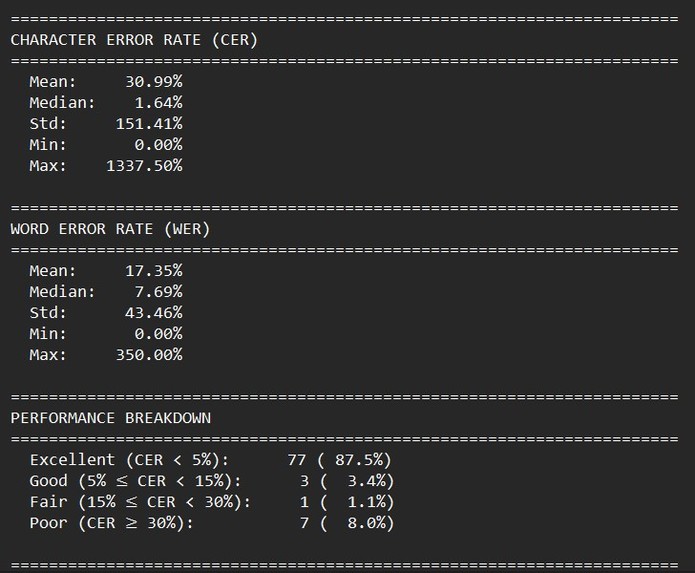
- The Metrics: I reduced the Median Character Error Rate (CER) from 19.82% (Baseline) down to 1.64%.
- The "Unusable" to "Usable" Jump: The baseline model produced "Excellent" (<5% error) predictions on only 1% of samples. My model achieved this on 77% of samples. That is a 76x improvement in usability.
- The System Design: I am proud that I didn't just stop at training a model; I built a full "Time Machine" product that makes the text searchable and understandable for modern users.
What I learned
- Architecture Matters: Standard CNN-based OCR is insufficient for historical documents. I learned that the Vision-Language approach (aligning visual tokens with language tokens) is essential for deciphering degraded ink.
- Data Hygiene: The importance of consistent line-level segmentation (converting PAGE-XML to JSONL) was critical for model convergence.
- Domain Expertise: AI cannot work in a vacuum. Integrating linguistic rules (for archaic spelling) improved the user experience far more than raw accuracy alone could.
What's next for Chronos-VL: The 1545 Resurrection Engine
- Expansion: I plan to incorporate the Esposalles Dataset to generalize the model across different centuries (17th and 18th century).






Log in or sign up for Devpost to join the conversation.