-
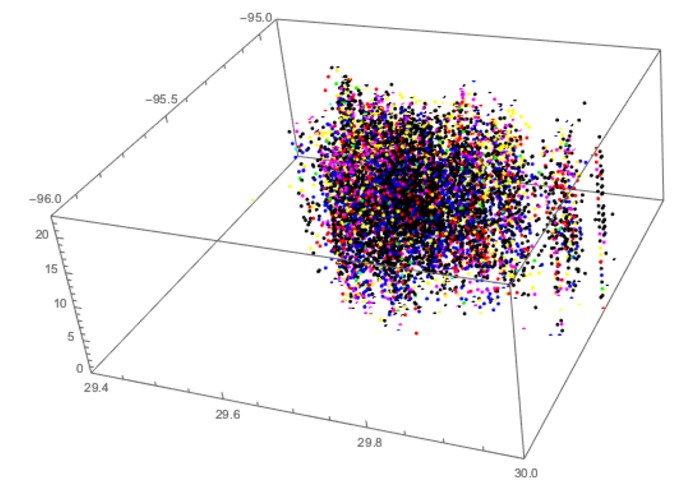
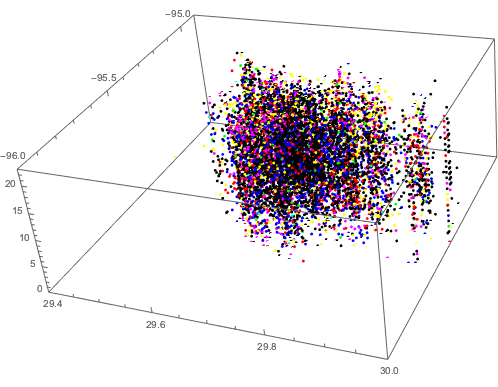
6 clusters of Houston crime data, marked by the different colors of the plotted points
-
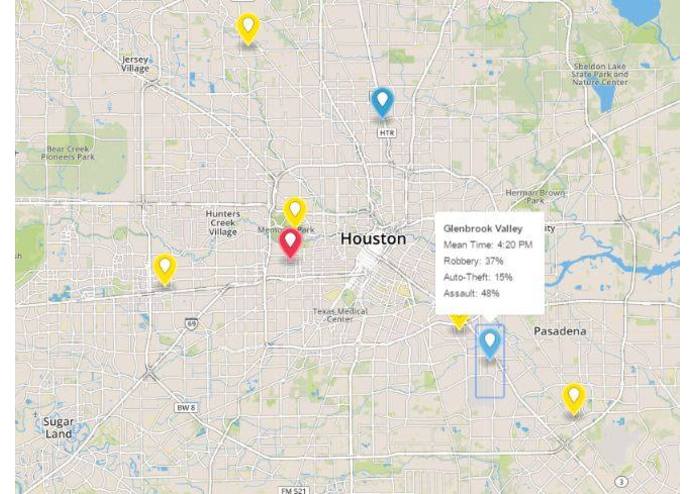
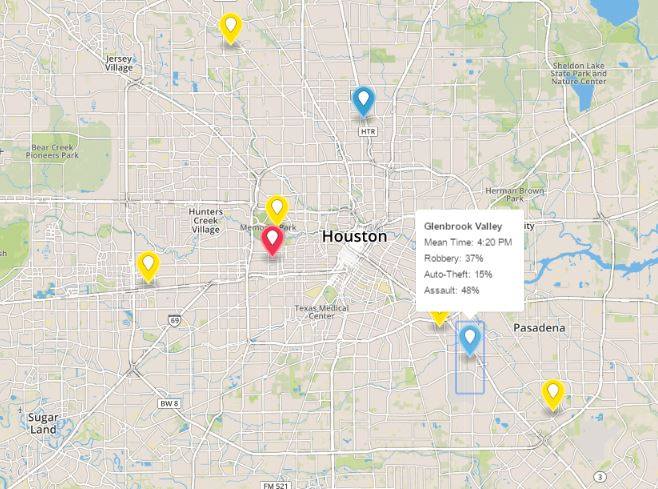
A still visualization of our clustering algorithm's end product
Inspiration
Heat maps are the most conventional form of crime tracking and monitoring, but they exhibit several flaws in their algorithmic accuracy and visualization. For example, their interpretation can be quite easily misunderstood, and their ability to tap into the temporal aspect of crime study is usually not as legitimate due to the extrapolation methods that those algorithms employ. In order to create a more accurate and visually helpful map visualization, we strove to work on a K-means cluster-based approach.
What it does
The K-means algorithm is an unsupervised machine learning algorithm that strives to cluster together data points based on their similarities. While most K-means-based approaches would try to cluster crime data on longitude and latitude data alone, our approach recognized the possibility for temporal relationships between crimes and tried to cluster based on time as well. This led to clusters very distinct from the normal two-dimensional clustering method's results--evidence of the dependency of crime upon time. The lack of independence there helps to show that this method's theoretical underpinnings are robust and that it may be able to spark a new form of conceptual thought about Houston crime previously unheard of.
How I built it
The machine learning side of the project was conducted mostly in Python, R, and Mathematica, and the visualization interface was designed in Javascript. Various APIs were used for geocoding.
Challenges I ran into
Various bugs in the customized K-means algorithm and issues with animations in Mathematica were a bit limiting at first, but over the course of the 24+ hours, we managed to get through most of these concerns.
Accomplishments that I'm proud of
The clustering algorithm was completely built manually and implemented modern initialization techniques meant to optimize convergence of the algorithm. Though difficult due to a variety of bugs that appeared early on and the lack of clean longitude and latitude data, the algorithm eventually worked out through our careful use of various APIs for geocoding and debugging methods. The lack of independence between crime and time also revealed that our model was very much along the right path.
What I learned
There is an interesting relationship/set of relationships between crime and time that need to be examined more fully in the future. Hopefully, in the short and immediate term, this visualization will endow law enforcement with the ability to predict crime patterns more accurately and temporally and promote preventative law enforcement responses.
What's next for Chronological Crime Clustering
The next steps for us include getting an interactive webpage operational and adding optionality for multiple types of maps/displays as well as a real-time nature of the cluster visualizations.

Log in or sign up for Devpost to join the conversation.