-
Preliminary Ideation
-
Model Architecture
-
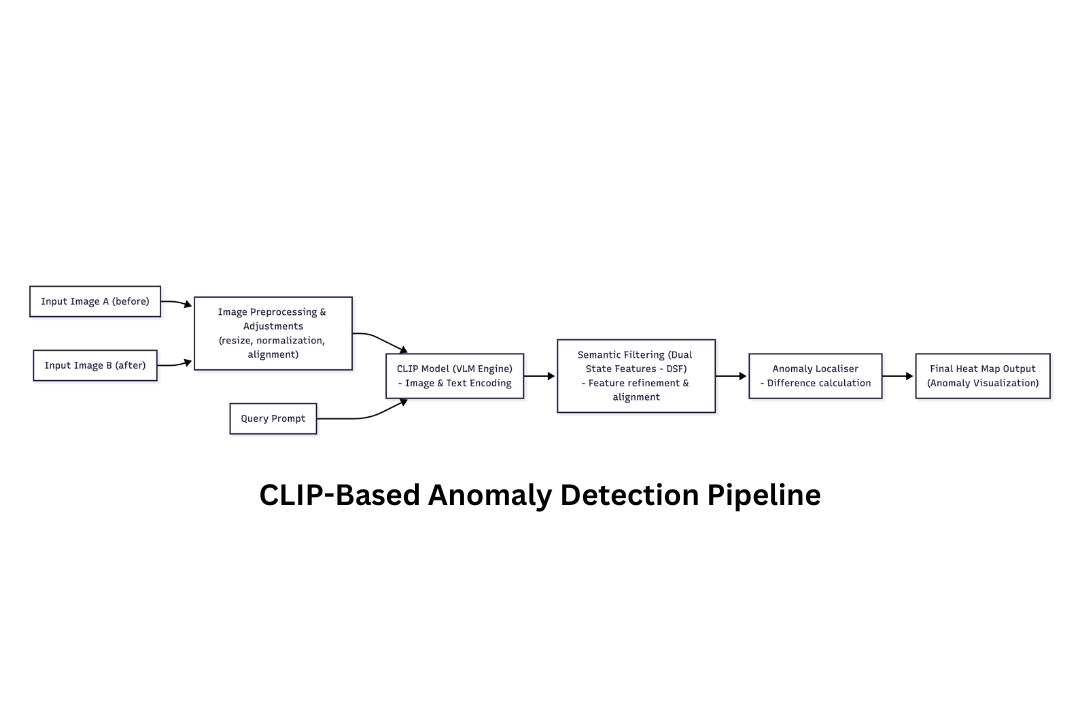
Model Pipeline
-

Use Case Analysis

Project Resources: Google Drive - Documentation & Dataset
Inspiration
At the 2024 Monaco Grand Prix, both Haas cars were disqualified from qualifying and sent to the back of the grid. The reason? A new rear wing design was non-compliant. The gap at the edges of the wing flap was fractionally larger than the 85mm allowed by FIA rules: an "inadvertent error" in assembly that their mechanics hadn't been trained to spot. A Visual Difference Engine, queried to "confirm FIA compliance against the final CAD," would have caught this devastating, race-ruining error in seconds, before the car ever left the garage.
Argus: Named after the 100-eyed giant in Greek mythology, it is the all-seeing sentinel for data. It vigilantly watches every pixel, ensuring that the exact change you query for, no matter how small, is instantly found.
Manufacturing facilities capture thousands of inspection photos daily, but reviewing them requires trained specialists who manually compare "before" and "after" images looking for specific defects, missing components, or compliance violations. Traditional computer vision systems either flag every pixel difference, overwhelming users with lighting changes and moved objects or require expensive custom training for each detection scenario.
We realized the problem wasn't detection itself, but the lack of semantic understanding. Human inspectors naturally filter irrelevant changes based on their inspection goal. We asked: could we give machines this contextual intelligence using natural language?
What it does
Argus is a general-purpose, semantic visual difference engine. The model takes history and current image pairs as input, referred to as dual-state images and produces a heat-map of predicted abnormal regions.
It takes two time-series images and a natural language Change-Query (e.g., "a missing item", "a new crack", "surface corrosion"). Leveraging the power of Vision-Language Models (VLMs) like CLIP, it performs a cross-modal, fine-grained semantic comparison.
The output is a highly localized heatmap, precisely highlighting only the regions where the visual change aligns with the user’s query, effectively filtering out irrelevant noise like lighting variations or camera jitter.
It utilizes the differences between history and current images of the same position to achieve anomaly localization, while addressing nonanomalous changes interference caused by the environment.
This enables highly specific anomaly detection and classification without needing explicit training for every possible defect. It eliminates the need for multiple encoding and discriminative postprocessing.
Applications
- Manufacturing QA: Detect missing components, misaligned parts or defects without custom model training
- Brand Compliance: Verify logo placement, color accuracy and packaging standards across retail locations
- Infrastructure Monitoring: Track crack propagation, corrosion and degradation in bridges, buildings and pipelines
- Compliance Audits: Identify unauthorized signage, safety violations or regulatory non-compliance
How we built it
Inspired by the binary zero-shot anomaly detection frame-work, we propose employing the comprehensive representation of the CLIP model to capture anomalies.
The global CLIP pretrained image features are semantically aligned at a local fine-grained level with text features, yielding Dual State Features (DSF) with generalized abnormal concepts and positional discrimination associated with the image. Additionally, we introduce the Difference Calculation module to facilitate anomaly-specific mutual information learning between DSFs.
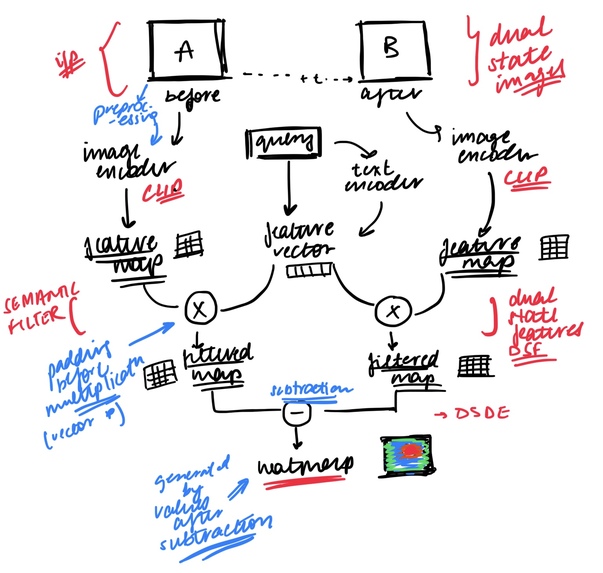
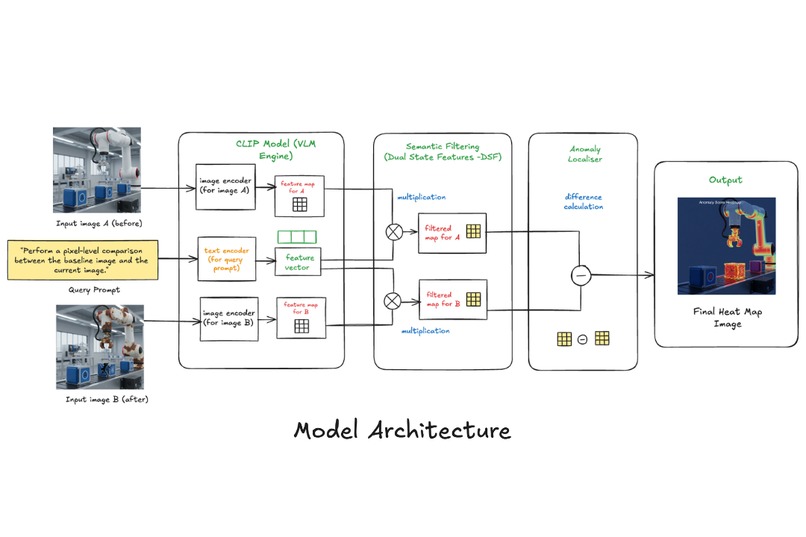
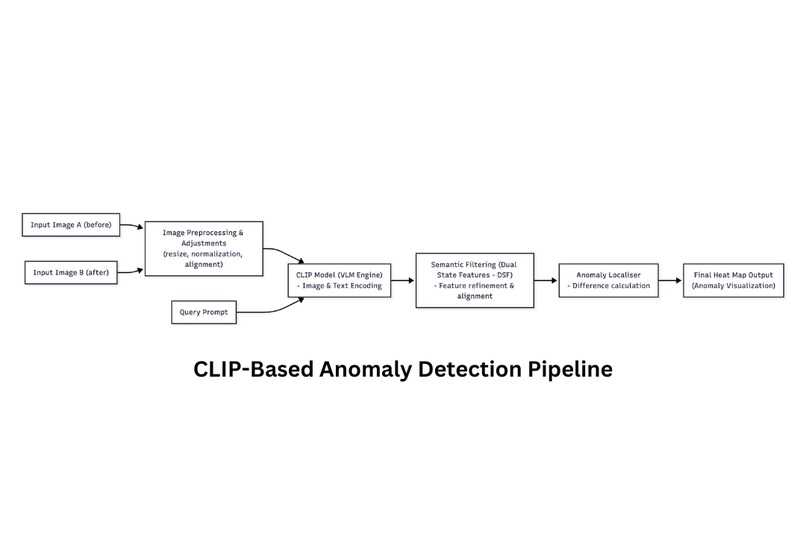
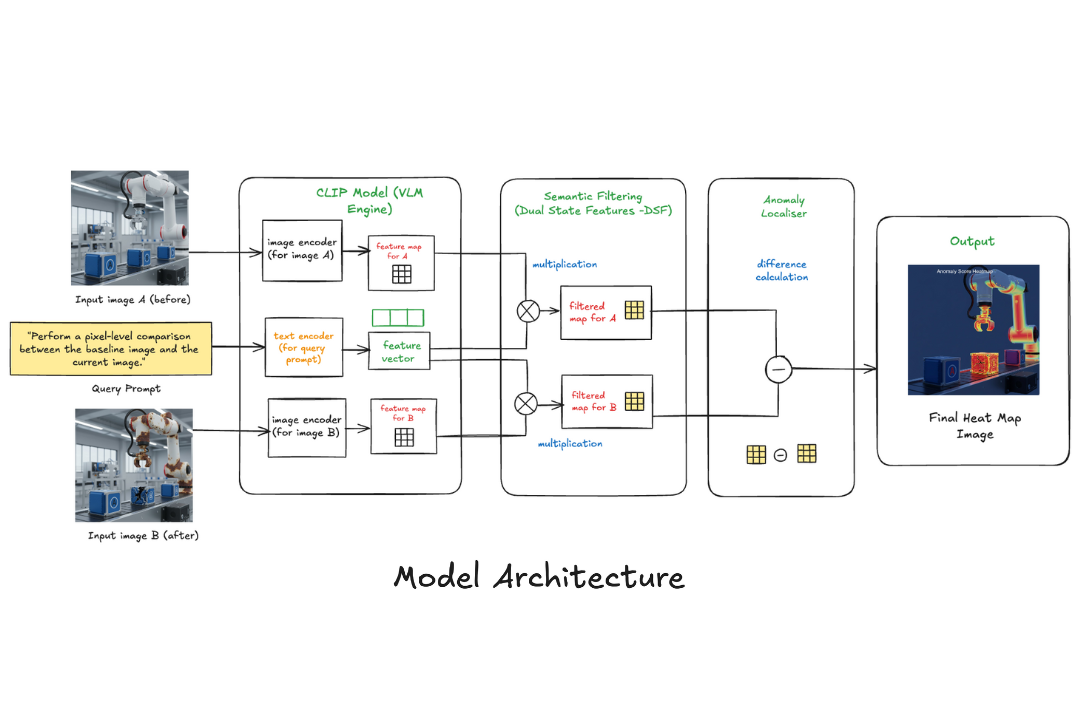
Key Components (refer model architecture diagram)
Dual Image Encoding:
CLIP is a contrast-learning-based image-text co-embedding model that trains the visual and text encoders by maximizing the similarity of positive instances (images and texts with same meanings) and minimizing the similarity of negative instances (images and texts with different meanings). Both input images pass through CLIP's image encoder, generating dense spatial feature maps rather than single embeddings.Query Encoding:
The natural language "change query" processes through CLIP's text encoder, creating a semantic feature vector.Semantic Filtering:
The DSF obtained from the CLIP pretrained model encompass integrated information of both normal and abnormal states. However, these features remain somewhat ambiguous for the fine-grained segmentation and localization of anomalies, and it is necessary to further exploit the mutual information of DSF to increase the precision of anomaly localization. We compute filtered maps by projecting the text embedding onto each image's spatial features by multiplying the feature vector with the feature maps for each image, creating before and after semantic feature maps that highlight query-relevant regions.Anomaly Localiser:
The final heatmap emerges from comparing these filtered semantic maps, isolating only the changes that align with the user's query through difference calculation of these image-filtered maps to further enhance the precise segmentation capability.
This approach requires no task-specific training, leveraging CLIP's pre-training on 400M+ image-text pairs for out-of-the-box semantic understanding.
Dataset
To support our visual engine, we explored multiple datasets containing time-series or dual-state imagery with anomaly or defect annotations.
AnomalyCD Dataset: Provides multi-temporal remote sensing imagery with annotated change regions. Though domain-specific (satellite), its time-series change detection structure aligns with our “before–after anomaly localization” framework.
Analog & Multi-Modal Manufacturing Dataset: Contains sequential manufacturing imagery coupled with analog sensor data. Suitable for simulating progressive visual states in industrial inspection scenarios.
Defect Spectrum: A large scale industrial defect dataset enriched with semantic and visual annotations for defect classification and language vision alignment.
Challenges we ran into
Adapting Global Models for Local Detection:
Since VLM features are often too coarse, our primary challenge was translating the global (image-level) understanding of VLMs like CLIP to precise local (pixel-level) anomaly detection. This requires us to experiment with new methods for fine-grained feature aggregation and cross-modal attention.Robustness to Environmental Noise:
We needed to ensure our "Difference Calculation" was robust and didn't trigger false positives from minor environmental changes like shadows or slight camera shifts.Optimizing for Real-Time Performance:
We had to balance accuracy with speed. The model would've been useless in the real-world if it was slow. Performing inference on dense, high-resolution feature maps is computationally expensive. We addressed this by using frozen VLM encoders and focusing on highly lightweight (but effective) difference calculation operations.
Accomplishments that we're proud of
We are incredibly proud of Argus's ability to interpret and localize anomalies based solely on a natural language query. This "query-driven" paradigm is a significant leap beyond traditional methods. Achieving precise, pixel-level heatmap generation for diverse anomaly types without any specific training for those anomalies, is a testament to the VLM's power. Furthermore, the intuitive user experience, simply typing what you're looking for- democratizes advanced visual inspection, making it accessible to non-ML experts.
- Query-driven anomaly detection: Argus can interpret and localize anomalies solely based on a natural language query.
- Zero-shot precision: Pixel-level heatmaps for diverse anomaly types without any task specific training.
- Accessibility: Users simply type what they’re looking for, making advanced visual inspection intuitive and accessible even to non-ML experts.
What we learned
- Pre-trained VLMs transfer remarkably well to industrial inspection contexts.
- The same visual difference can be critical or irrelevant depending on intent, confirming that general-purpose change detection must be query-driven.
- Robustness comes from handling edge cases: subtle shifts, partial occlusions, and perspective variations define real-world quality.
What's next for Argus
Our immediate next steps include building out a robust, containerized deployment for scalable inference. We plan to explore temporal consistency modules to enhance change tracking across longer video sequences. Future iterations will focus on expanding to 3D data and integrating with robotic systems for autonomous inspection. Argus is poised to revolutionize visual inspection, moving from reactive detection to proactive, intelligent anomaly classification.
We aim to:
- Containerize for scalable inference and deploy efficiently.
- Develop temporal consistency modules for longer time-series and video analysis.
- Integrate user feedback loops to fine-tune query understanding.
- Expand toward 3D data and robotic system integration for autonomous inspection.
Argus is set to revolutionize visual inspection, moving from reactive detection to proactive, intelligent anomaly classification powered by semantic understanding.
References
- K. Lei and Z. Qi, "A Dual-State-Based Surface Anomaly Detection Model for Rail Transit Trains Using Vision-Language Model,"
IEEE Transactions on Instrumentation and Measurement, vol. 74, pp. 1–13, 2025,
Art no. 3509113, doi: 10.1109/TIM.2025.3534228.
Keywords: Anomaly detection; Feature extraction; Training; Rails; History; Interference; Accuracy; Visualization; Semantics; Location awareness; Dual-state features (DSFs); rail transit train; surface anomaly detection; vision-language model; visual inspection.
- W. Lu, E. Zhang, N. Li, J. Li, J. Du, and X. Zhang, "Unsupervised Cigarette Packaging Defect Detection Method Based on Multi-Scale Feature Matching,"
2024 China Automation Congress (CAC), Qingdao, China, 2024, pp. 5938–5943,
doi: 10.1109/CAC63892.2024.10865052.
Keywords: Training; Printing; Location awareness; Uncertainty; Production; Packaging; Inspection; Feature extraction; Defect detection; Testing; cigarette packaging defect detection; unsupervised object detection; computer vision; deep learning.
- Radford, Alec, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger and Ilya Sutskever, "Learning Transferable Visual Models From Natural Language Supervision,"
2021 International Conference on Machine Learning,2021,
doi: arXiv:2103.00020.
- Q. Zhang, F. Lin, and H. S. Seah, "Detecting and Imaging Irregularities in Time-Series Data,"
2018 International Workshop on Advanced Image Technology (IWAIT), Chiang Mai, Thailand, 2018, pp. 1–4,
doi: 10.1109/IWAIT.2018.8369784.
Keywords: Standards; Time series analysis; Fuels; Visual analytics; Imaging; Anomaly detection; imaging and visual analytics; multimedia system; timestamp alignment; irregularity detection; time-series.
Built With
- amazon-web-services
- fastapi
- openclip
- opencv
- python
- pytorch
- scikit-learn
- tensorflow


Log in or sign up for Devpost to join the conversation.