-
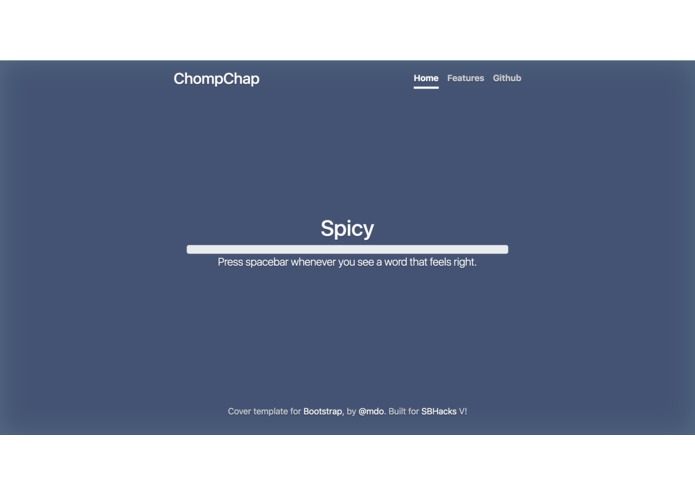
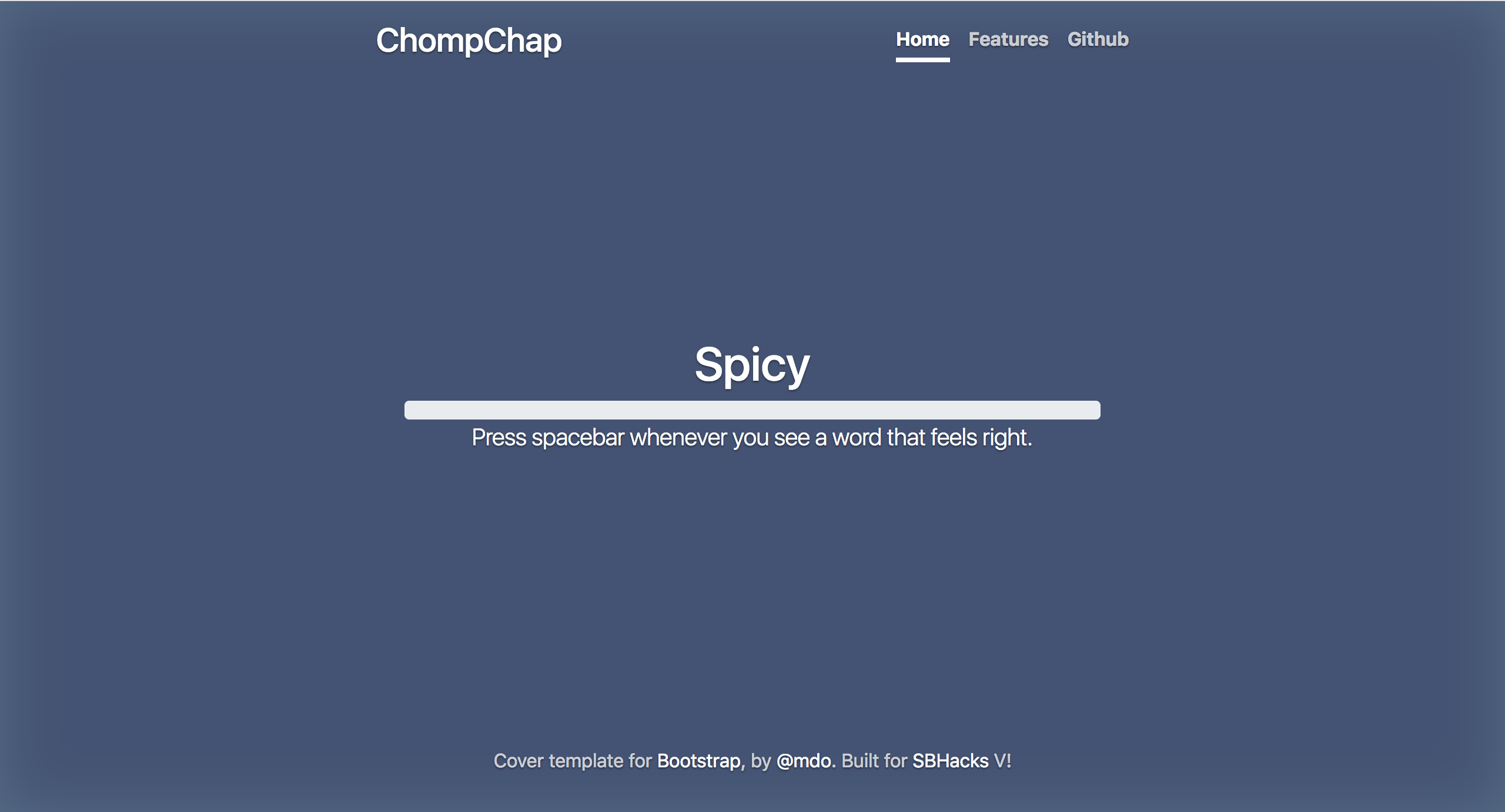
Main page
-
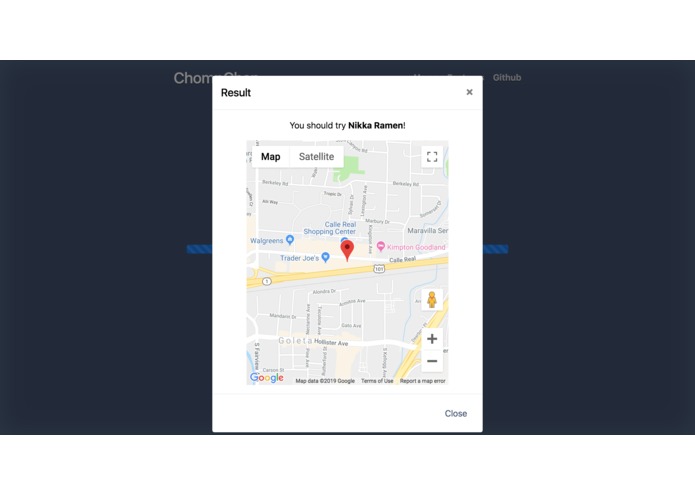
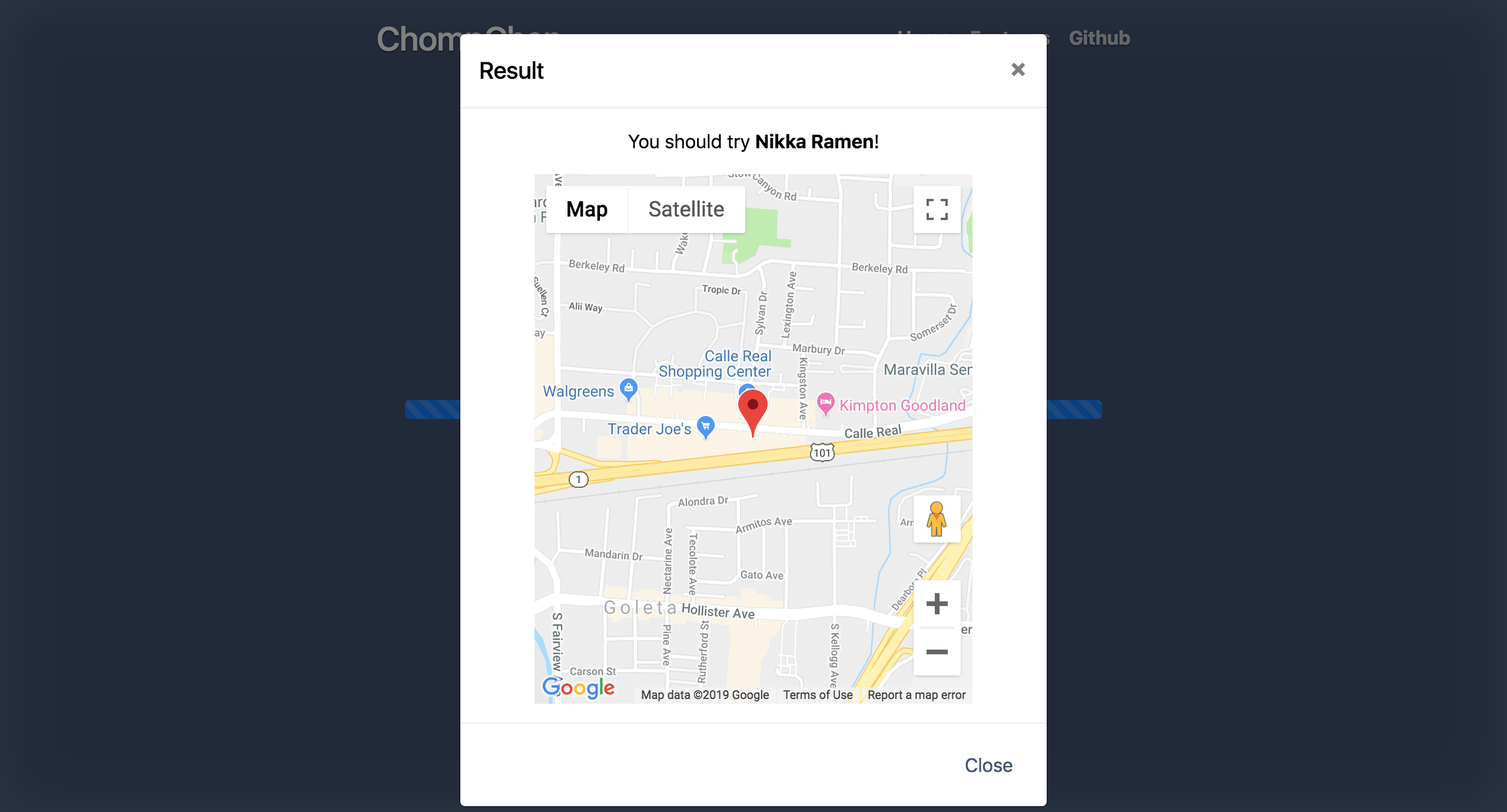
Result
-

Technologies used
ChompChap
Inspiration
In this age of millennial indecision, who could possibly decide on where eat? Many available applications offer too many choices: they are user driven services, so the weight and ultimate challenge of choosing a restaurant is still an issue. Motivated by algorithms like automated ad servers or shopping suggestions, we aimed to bring that same machine-learning-driven predictive and analytical power to the first-world’s greatest plight.
What it does
ChompChap embraces the university student’s technology-driven, commitment-avoiding lifestyle by deciding where you actually want to eat, foregoing the user-driven nightmare of endlessly scrolling through Yelp or Google. It does this by first flashing a list of taste-related words on the screen. The user is immediately prompted to press the spacebar whenever they see a word that they find appealing in that moment. This saves the current word on the screen and prompts the words to flash by faster. Six words which theoretically describe the user’s subconscious profile are selected in this way and are then considered by our algorithm which returns a restaurant that it thinks is suitable.
How we built it
Using the Yelp business details and reviews datasets, we matched business attributes to user reviews. Each review was cleaned, tokenized, and converted into a fixed word count feature vector. These features were then used to predict which of 11 “meta-categories” (instead of 300+ unique categories) the business was associated with. We used a 10-dimensional embedding layer to convert lists of categories for each business (e.g., “American (new)”, “Fast food”, “Breakfast”) into vectors in order to utilize k-means clustering to come up with the 11 thematically-similar meta-categories. Using a Long Short Term Memory (LSTM) network, which was chosen to allow input data to have arbitrary length, user-influenced/selected words are turned into a list of matching meta-categories, ultimately used to find the best place to eat. The network was trained in about 20 minutes on a V100 GPU provided by Google Cloud Platform.
ChompChap’s Javascript-jQuery webpage is served by a Flask-Celery application on a Redis server. It is powered by a python backend deployed with Tensorflow and Keras Machine Learning models for prediction on user input.
Challenges we ran into
Training machine learners is hard, but training a machine learner to make intelligent decisions is even harder. We ran into several challenges in classifying restaurants by taste-specific keywords. First, conflicting labels and categories for restaurants caused more overlap in the clustering. Most importantly, user-provided text reviews were filled with spelling errors, irrelevant information, and spam, which waas not fully mitigated even when cleaning common words and tokenizing the reviews.
There were also complications in tying the backend with Flask. While this should be made easy by the continuity in language, Flask has some particular issues that made directly incorporating our algorithm’s API difficult.
Embedding Google maps was much more difficult than it should have been, simply due to the highly-cryptic nature of the errors we faced. Many errors gave little or absolutely no explanation of what was happening, and thus vastly extended the time necessary to fix the problem. This was exacerbated by the extensive amount of versions of Google Maps from over the years, such that when trying to find solutions we found that the majority of them were outdated.
…Sleep deprivation.
Accomplishments that we're proud of
Despite the complications with such an unruly dataset, we achieved a robust neural network model architecture while minimizing the latency for prediction, so that the user is provided with a snappy recommendation. We also implemented a clean, simple interface along with an efficient and organized Flask server that can handle many users.
What's next for ChompChap
During the development process, we considered several appealing features and improvements that could easily be implemented in the future. For the algorithm, we would look to acquire more relevant datasets. Specifically, we could flash images instead of text, which would require a different model altogether. We also have plans to make the website look more modern with some subtle animations as well as to add more information to the result modal.





Log in or sign up for Devpost to join the conversation.