-
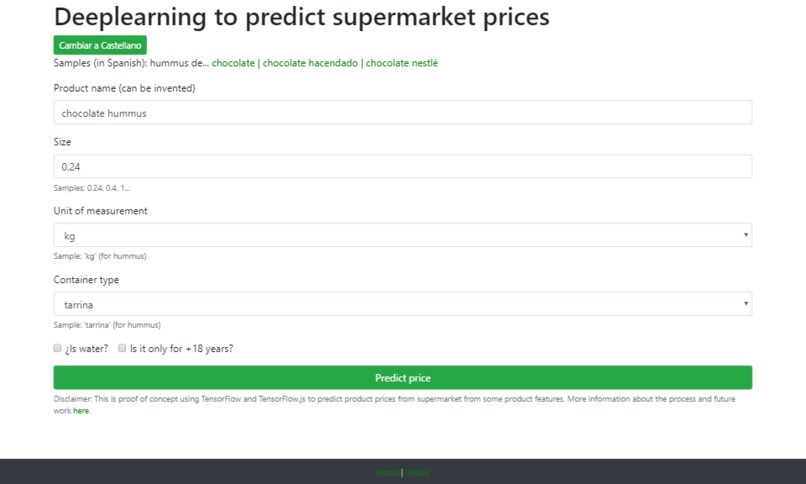
Web version using TensorFlow.js.
-
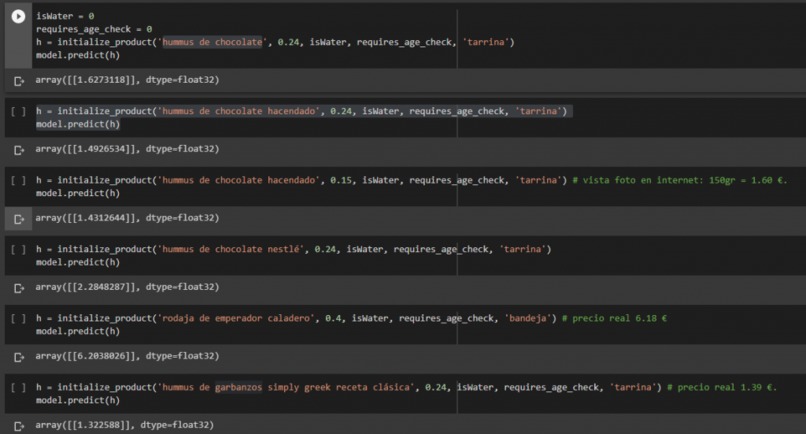
Predicting product process
-
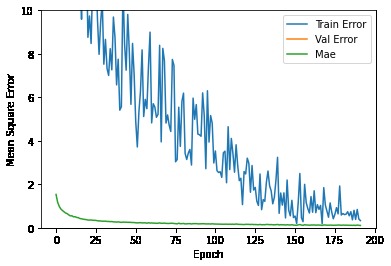
Training process
-
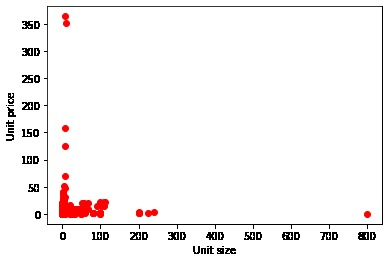
Product dataset
Inspiration
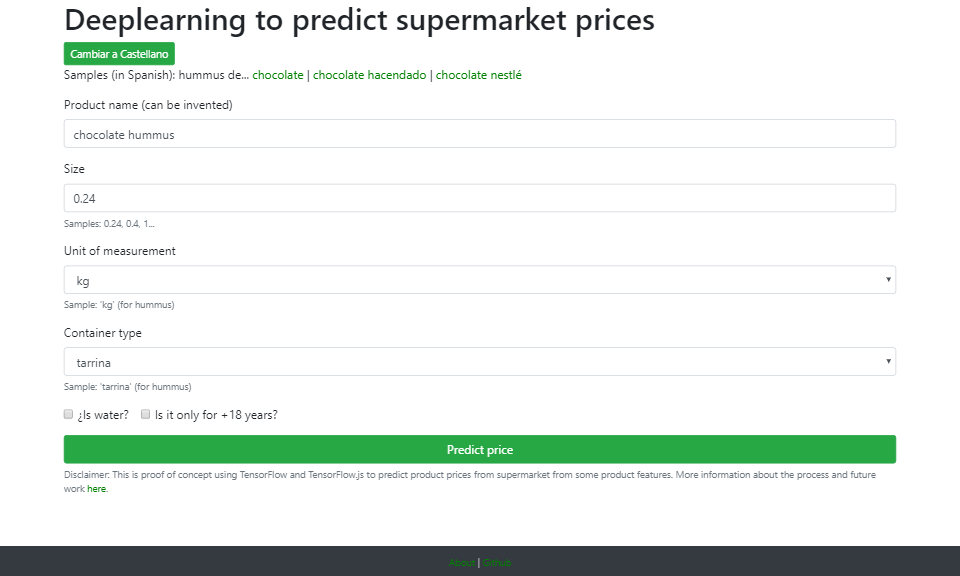
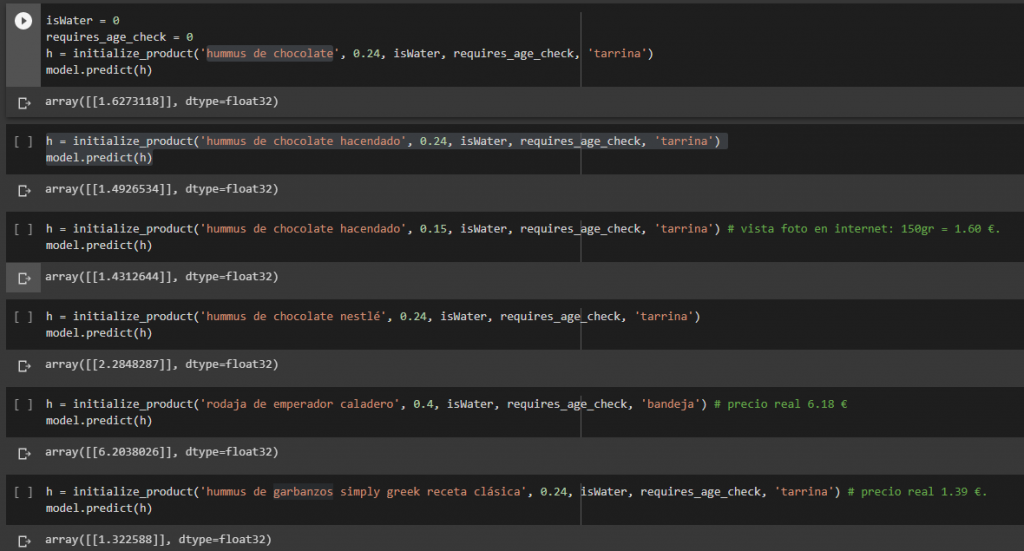
The idea was born out of curiosity to answer the following question: if we know how much hummus costs and how much does chocolate cost in a supermarket, how much would chocolate hummus cost? How good can a price prediction be for products not known to the neural network? Therefore, the name of the project comes from here.
If we are able to predict these prices, we could help create new cheaper products and detect unfair prices on existing products.
What it does
I have trained a model with tensorflow in python to be able to predict the price of new products based on their name, their weight and their type of packaging. The initial dataset contains information on 6000 real products from Spanish supermarkets.
Next, the price prediction can be obtained from the python script (I've published a jupyter notebook for google colab on github) or also from a web page, since I have exported the trained model of tensorflow to be used from a web with tensorflow.js.
The names of the products must be in Spanish, here are some examples that can be used:
- Hummus de chocolate
- Hummus de chocolate hacendado ('hacendado' is a brand known for its low prices)
- Hummus de cholocate nestlé
- Rodaja de emperador caladero (not cheap fish).
How I built it
The product database used for the training is from 2018 and has been obtained from the internet. It contains approximately 6,000 products from Spanish supermarkets.
The initial data is not as good as we would like, having only for training with only this info of each supermarket product:
- Product name.
- Price.
- Container type.
- Measurement (in kilograms, meters, liters or units).
- Whether it is water or not.
- If it is for +18 years.
There is no info on the ingredients of the products (beyond those that may appear in the name of the product), the manufacturing process, or place of origin... So that we can think that we are not going to achieve good results...
After importing the information, I had to delete a few anomalous data. In addition, I encoded the packaging type and unit of measurement information as one hot word encoding.
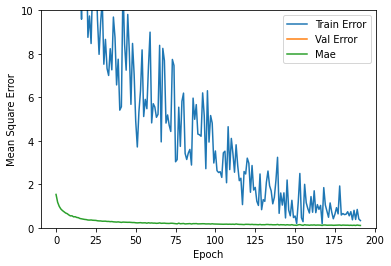
The model is built using keras in Tensorflow. I've tried different combinations and finally I've used 3 dense layers.
During training, I used EarlyStopping and RMSprop as optimizer.
At the time of sending this, the error during the training phase was 0.13 €, and during the test phase it was 0.6 €. I have to fix this overfitting as I explain in "What's next" section.
Finally, I've learned to export the trained model to be able to use it from the website with tensorflow.js: https://javiercampos.es/proyectos/deeplearning-supermercado/index_en.html
Challenges I ran into
The first challenge was to find real information about thousands of supermarket products.
Next, a small group of dataset products did not have information on their packaging type, so I created a new type of packaging called "other" to not discard those products from the training dataset.
The names of the products are in Spanish and this has been a limitation for their coding in training. I have not found a pre-trained model for word embedding in Spanish. So I have finally encoded the product names using one hot word encoding.
I have never worked with Google Colab nor TensorFlow nor Keras before, but finally I have used it to develop this project.
Accomplishments that I'm proud of
I have never worked with Google Colab, nor TensorFlow nor Keras before, but finally I have used it to develop this project and I have published the jupyter notebook on github so that other developers can learn and continue the work.
Also, I think the error obtained in the predictions is quite good. The initial dataset contains a little information. Moreover in future work I hope to improve this error.
What I learned
It is the first neural network that I do, surely there are many things that can be improved and I will continue learning. I've learned to use tensorflow for python, I've learned to export the trained model, I've learned to use tensorflow.js. Also, I have learned a very important part which is preprocessing the data before using it in training.
During this project, I have taken care not to collect personal information, I have avoided that the information is biased: all the products sold in a supermarket chain in Spain are used for training, without restriction. Using this AI is safe. It can be used by:
- sellers, to predict the price of a new product (disclamer: we know that the model does not yet take into account everything that influences the price of a product such as place of origin, manufacturing process, etc ... but we think it works as an approximate starting point).
- buyers to find out if the price of a product is close to what was expected.
- curious users to predict the price of a product that does not exist.
What's next for Chocolate Hummus
- Avoid overfitting the current version.
- Reduce the error obtained during the test phase.
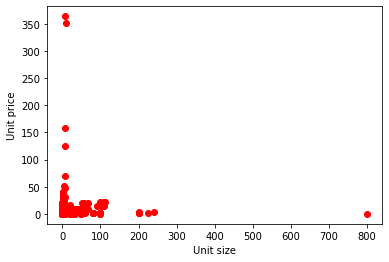
- Compare results eliminating the anomalous products that "come out" of the distribution graphs (chopsticks in boxes of 800 units, Serrano ham of 300 euros, etc ...). Update: this I have already done:

- Compare results by normalizing / not normalizing the input data.
- Compare results by preprocessing product names (ideas: remove numbers, remove words "from", "the"...).
- Make tests with different meta parameters of the neural network.
- Apply Data Augmentation to create derivative products in the training set (example: create "pack" products with greater weight and higher price).
- Take into account the semantics of the words in the product name. Right now for example ‘casera’ (singular 'homemade') and ‘caseras’ (plural 'homemade') are 2 different words in the one-hot encoding encoding that I used. Idea: use the word embedding technique with a pre-trained network that knows the semantics of the words.
Built With
- googlecolab
- javascript
- keras
- python
- tensorflow
- tensorflow2

Log in or sign up for Devpost to join the conversation.