Inspiration
What it does
How we built it
Challenges we ran into
Accomplishments that we're proud of
What we learned
TypoDiffusion: Can Chinese Text Denoise Itself?
A 15-phase research journey into discrete text denoising — from hand-written confusion maps to context-aware masked language models.
The Spark: An Analogy That Wouldn't Let Go
In image generation, Diffusion models work by first adding noise to an image (forward process), then learning to remove it (reverse process). The beauty is in the simplicity: corrupt, then recover.
I kept asking myself: what would this look like for text?
Not for continuous embeddings — people already do that with diffusion language models. I mean for discrete Chinese characters. What if you took a correct sentence like:
$$\text{今天我们在音乐课上学习了节奏。}$$
and replaced a few characters with their homophones:
$$\text{今添我们在音棵上学习了节走。}$$
Could a model — or even a human — recover the original? And more importantly: does the noise type matter more than the noise amount?
That question became the seed of TypoDiffusion.
What I Built (and What I Learned)
Phase 1–3: The Noise Factory
I started with the simplest possible thing: 5 rule-based noise functions.
| Noise Type | What It Does | Example |
|---|---|---|
homophone |
Replace with same-pinyin character | 天 → 添 |
visual |
Replace with look-alike character | 师 → 帅 |
random_char |
Replace with random common character | 学 → 门 |
deletion |
Delete a character | 学习 → 学 |
shuffle |
Swap adjacent characters | 学习 → 习学 |
Each function takes a rate parameter (0.0–1.0) and a seed for reproducibility. Simple, deterministic, no GPU needed.
The first surprise came during calibration. I ran a sweep across 20 seed sentences and discovered that homophone at rate=0.30 only achieved actual_corruption_rate=0.045. Why? Because my confusion table only had 24 keys — if the sentence didn't contain those specific characters, nothing happened.
This led to a key insight:
$$\text{effective_noise} = \text{requested_rate} \times \text{coverage}$$
where $\text{coverage} = \frac{|{c \in \text{text} : c \in \text{confusion_map}}|}{|\text{non-punct chars}|}$
Phase 4–5: The Human Element
I generated 48 annotated samples and scored them myself on three dimensions:
- Readability (1–5): Can you read the noisy sentence?
- Recoverability (1–5): Can you restore the original?
- Ambiguity (1–5): How many valid originals could this be?
The results confirmed the core hypothesis:
$$\text{noise type} \gg \text{corruption rate}$$
At roughly the same corruption rate ($\sim 0.10$), readability ranged from 2.70 (random_char) to 4.25 (visual). The semantic nature of the noise, not just its quantity, determines human recoverability.
Phase 6–8: Teaching Machines to Denoise
I implemented a MaskedLMDenoiser using hfl/chinese-macbert-base — a pre-trained Chinese BERT model. The approach: mask a suspicious position, predict what should be there, and accept if confidence is high enough.
The first version (heuristic_mask_denoise) had the same over-correction problem as the rule-based approach. For example, the character "老" in "老师" happens to be a value in the reverse homophone map, so the rule-based denoiser would try to "correct" it — breaking perfectly good text.
The fix was sentence-level scoring using masked pseudo-likelihood:
$$\text{score}(x) = \frac{1}{|C|} \sum_{i \in C} \log P(x_i \mid x_{\setminus i})$$
where $C$ is the set of CJK character positions. Before accepting a change, I check:
$$\Delta = \text{score}(\hat{x}) - \text{score}(x) \geq \delta_{\min}$$
This conservative strategy improved homophone exact match from 0.30 to 0.40 and prevented the visual over-correction that plagued the greedy approach.
Phase 9–10: The Deletion Problem
Deletion noise is fundamentally different from substitution. You can't "replace back" a character that isn't there — you need to insert one. This is where the analogy to image diffusion breaks down: in images, you denoise by adjusting pixel values; in text, you sometimes need to invent new tokens.
I implemented an infilling approach: try inserting a [MASK] at every gap position, predict what should go there, and accept if it improves the sentence score. The result:
| Denoiser | deletion ca | homophone ca |
|---|---|---|
| copy (baseline) | 0.216 | 0.912 |
| infilling | 0.379 | 0.109 ← disaster |
| unified (replace + insert) | 0.332 | 0.897 |
Infilling alone improved deletion but destroyed homophone performance by inserting unnecessary characters. The solution: a unified edit denoiser where replace and insert candidates compete based on sentence-level score improvement. The best $\Delta$ wins.
Phase 11–12: Engineering for Speed
The unified denoiser was painfully slow — each candidate position required a full pseudo-likelihood computation. I implemented two optimizations:
- Candidate pruning:
rank_insertion_positions()filters insertion points by proximity to CJK characters, reducing from 20+ to 5 positions - Policy gate: route each noise type to the best strategy automatically
$$\pi(nt) = \begin{cases} \text{conservative} & \text{if } nt \in {\text{homophone, visual, mixed}} \ \text{unified_limited} & \text{if } nt = \text{deletion} \ \text{copy} & \text{if } nt = \text{random_char} \end{cases}$$
Phase 13–15: Scaling Up
The original 20 sentences were too small. I expanded to 200 sentences across 6 domains (music, art, school life, reading, science, classroom instruction), then ran into a wall: visual noise had only 4 eligible samples because the confusion table covered too few characters.
The fix: expand VISUAL_MAP from 85 to 243 keys. After expansion:
| Metric | Before | After |
|---|---|---|
| Visual coverage | 4% | 41% |
| Visual eligible samples | 4 | 451 |
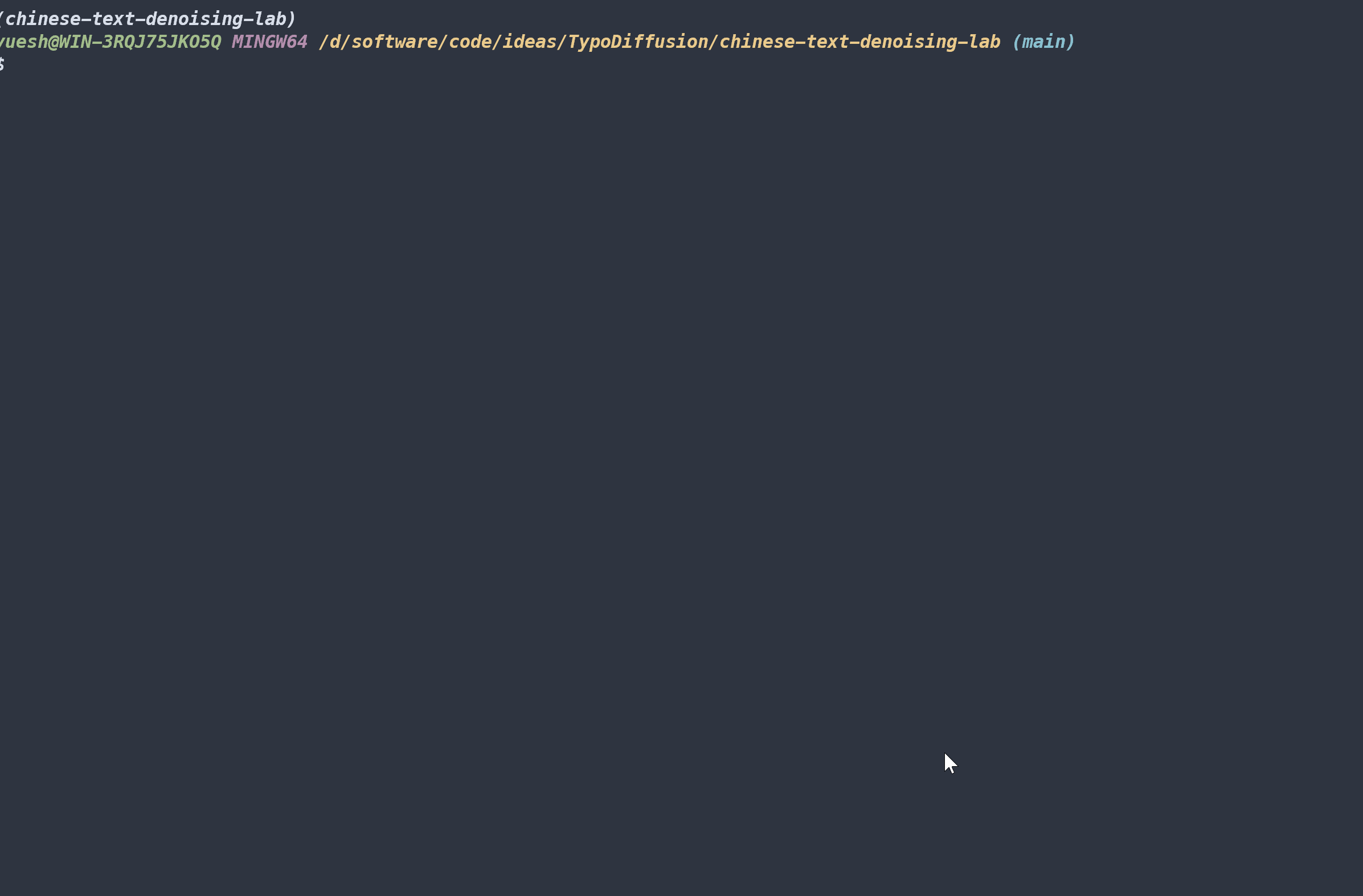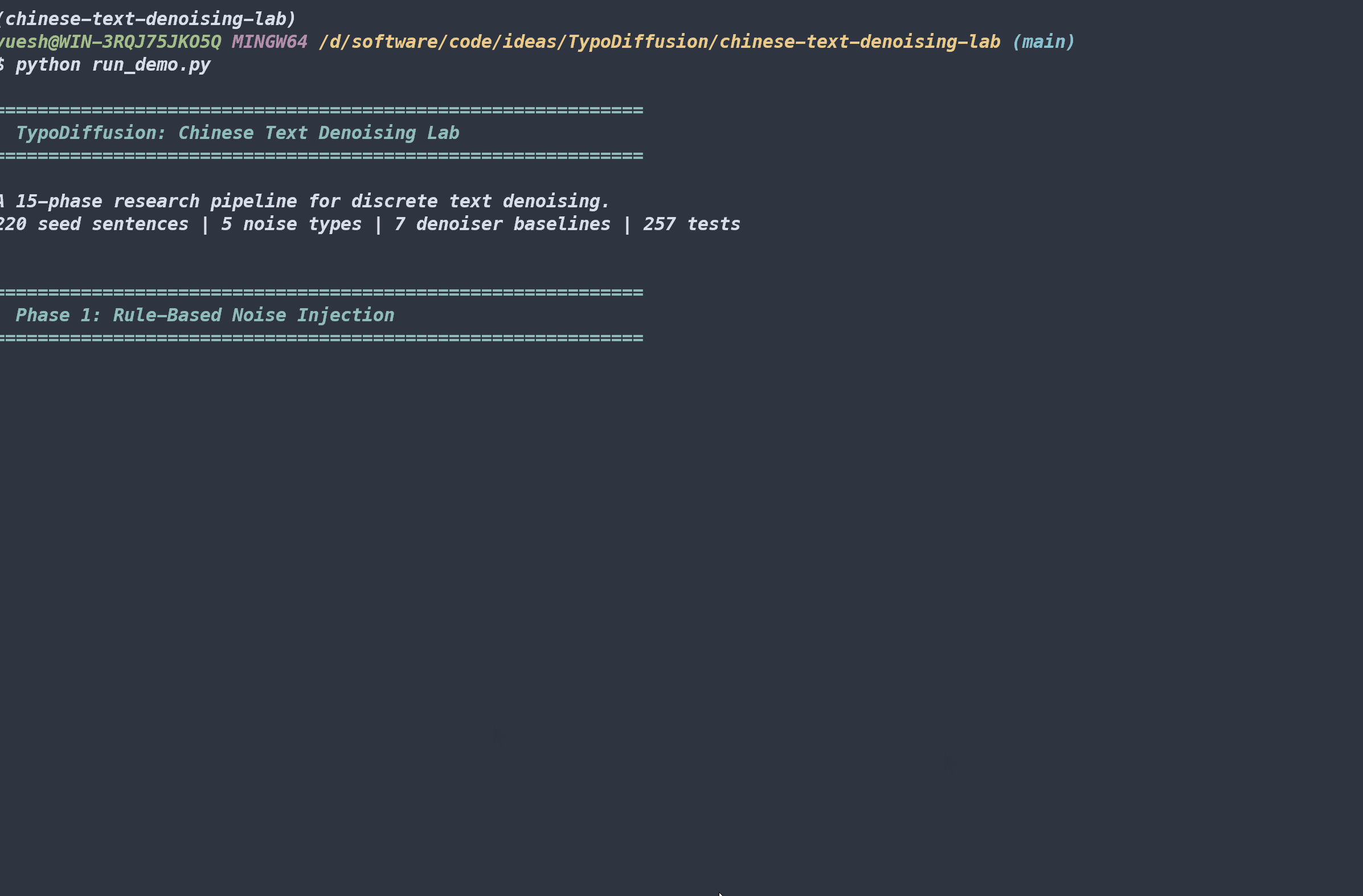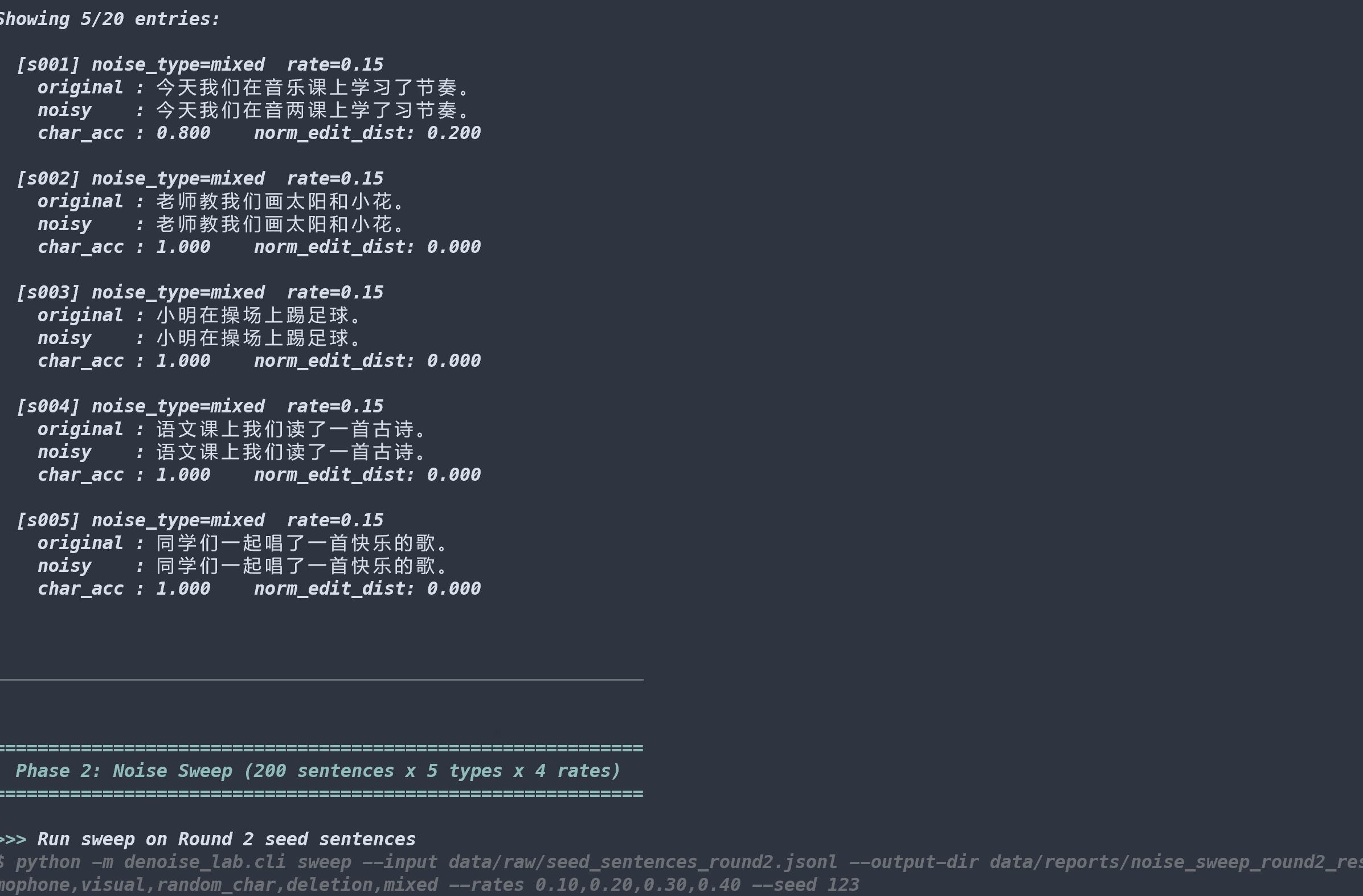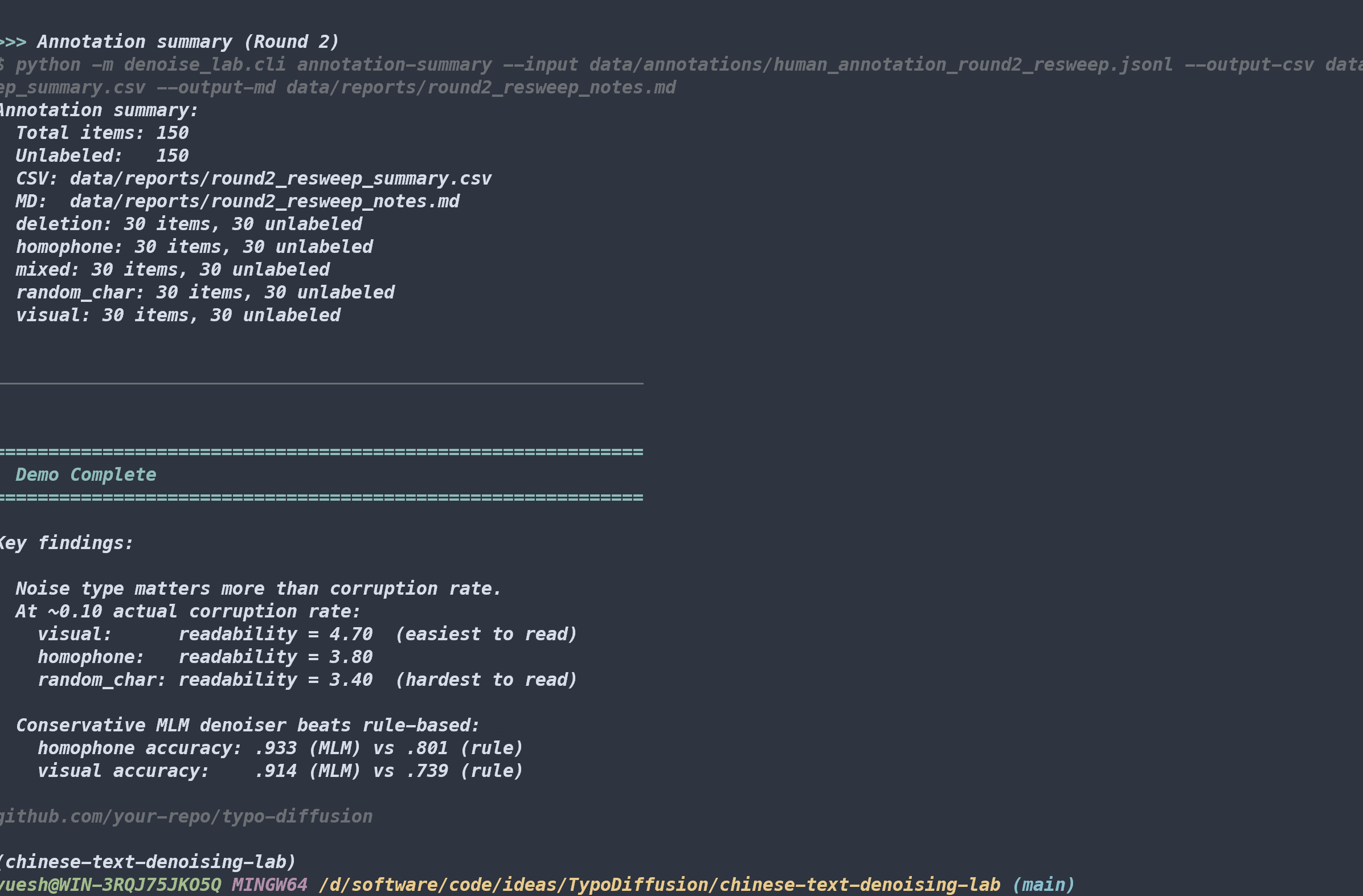
| Round 2 annotation size | 124 | 150 |
The Full Picture
After 15 phases, the complete comparison looks like this:
$$\begin{array}{lccccc} \textbf{Denoiser} & \text{homophone} & \text{visual} & \text{random} & \text{mixed} & \text{deletion} \ \hline \text{copy} & .912 & .927 & .897 & .646 & .216 \ \text{rule_based} & .801 \downarrow & .739 \downarrow & .897 & .429 \downarrow & .216 \ \text{mlm_conservative} & \mathbf{.933} \uparrow & \mathbf{.914} & .897 & \mathbf{.619} & .216 \ \text{oracle_map} & .992 & .985 & .928 & .668 & .216 \ \end{array}$$
The $\downarrow$ marks over-correction. The $\uparrow$ marks genuine improvement.
Challenges That Kept Me Up at Night
1. The Hash Randomization Bug
Python's built-in hash() is randomized across processes (security feature since 3.3). My sweep used hash(noise_type) % 10000 as part of the seed — meaning the same command produced different results each run. I switched to hashlib.md5() for deterministic seeding.
2. The Pseudo-Likelihood Bottleneck
Scoring one sentence requires $O(n)$ MLM forward passes (one per character position). For 48 items × 20 candidate positions × 3 rounds, that's ~3000 forward passes. On CPU, this took 10+ minutes. I couldn't parallelize without GPU, so I focused on pruning (reduce candidates) and policy gating (skip unnecessary denoising).
3. The Visual Coverage Blind Spot
For 13 phases, visual noise appeared to have zero effect. It wasn't a bug in the noise function — it was a data problem. The confusion table had 85 keys, but the 20 seed sentences barely contained any of those characters. The fix was expanding to 243 keys and growing the dataset to 200 sentences. This taught me to always check coverage before interpreting results.
4. The Over-Correction Paradox
More correction isn't always better. The rule-based denoiser and the infilling denoiser both demonstrated that aggressive correction can make things worse than doing nothing. The conservative strategy (accept only if sentence-level score improves) was the key innovation.
What's Next
This project established the infrastructure. The natural next steps:
- Real-world data: Replace hand-written confusion maps with statistics from NLPCC/LEAD Chinese Spelling Correction datasets
- Fine-tuned MLM: Train
chinese-macbert-baseon noise-corrupted pairs - True discrete diffusion: Implement a training objective where the model learns to denoise iteratively, analogous to $x_t \to x_{t-1} \to \cdots \to x_0$
- Scaling laws: How does denoising quality change with dataset size, model size, and number of denoising rounds?
The core question remains open: can we build a text diffusion model that denoises discrete characters the way DDPM denoises pixels? This project is the first step on that path.
Built with Python 3.12, pytest, and hfl/chinese-macbert-base. No training — all baselines use zero-shot inference. 257 tests, 15 phases, 0 GPU hours.
What's next for Chinese Text Denoising Lab
Built With
- 220
- all
- annotation-guidelines
- annotations
- argparse
- cli
- collections
- csv
- data
- downloaded
- external
- from
- hashlib
- inference
- infrastructure
- json
- markdown)
- models
- no
- pathlib
- random
- re
- seed
- sentences
- sources
- sweep-items
- tests
- training
- used
- via
- zero-shot

Log in or sign up for Devpost to join the conversation.