-
-

ChimeraForge landing page
-
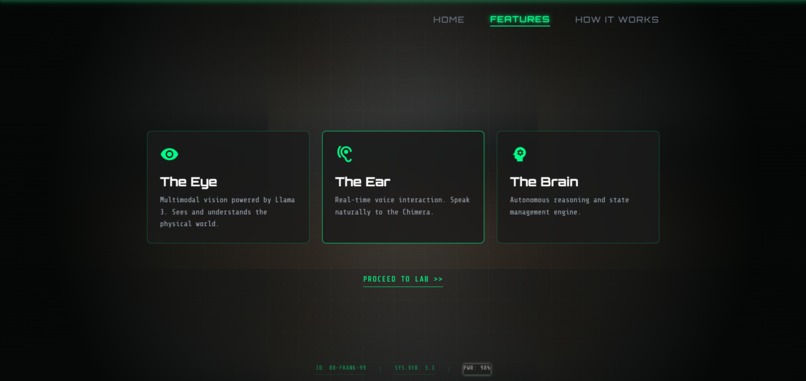
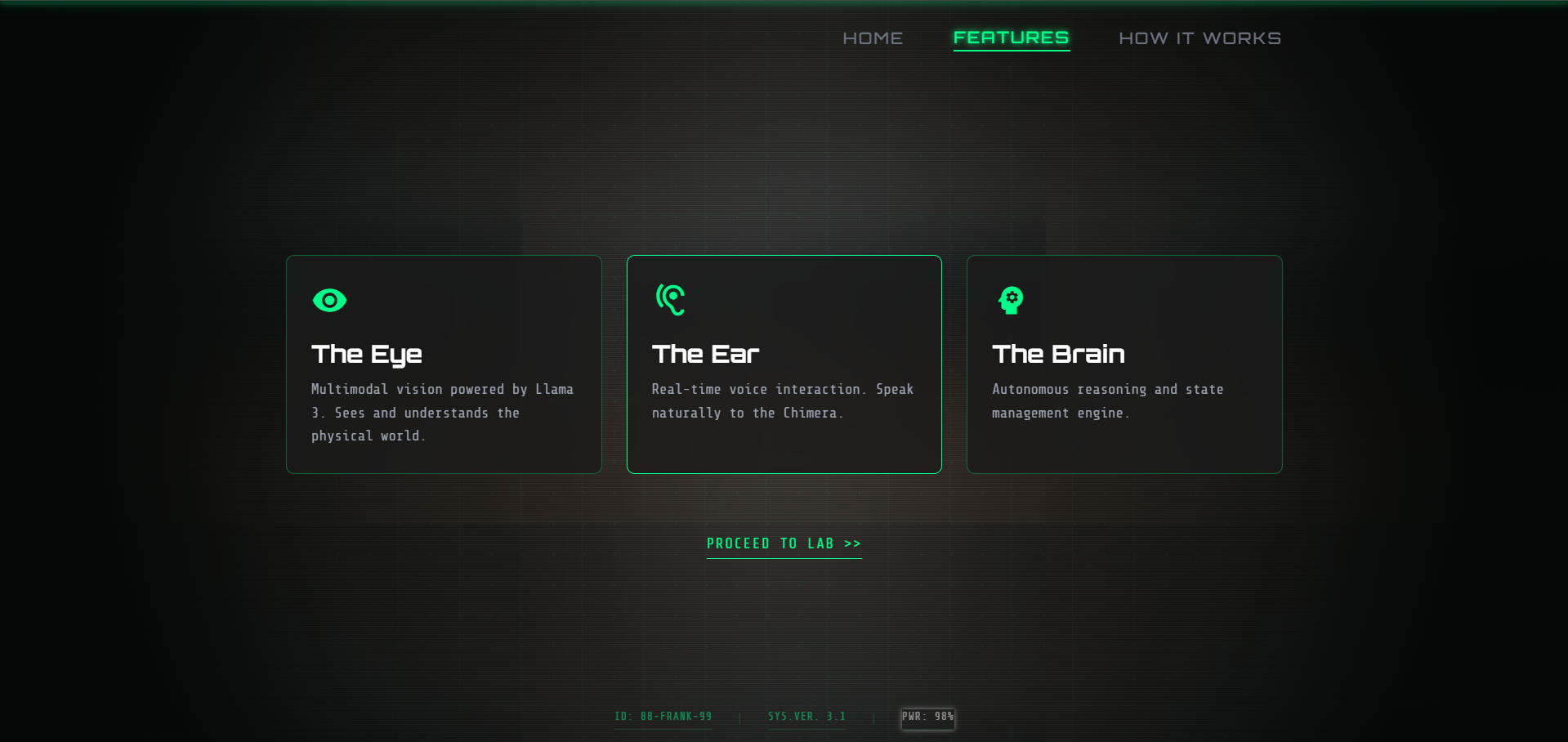
Features Page
-
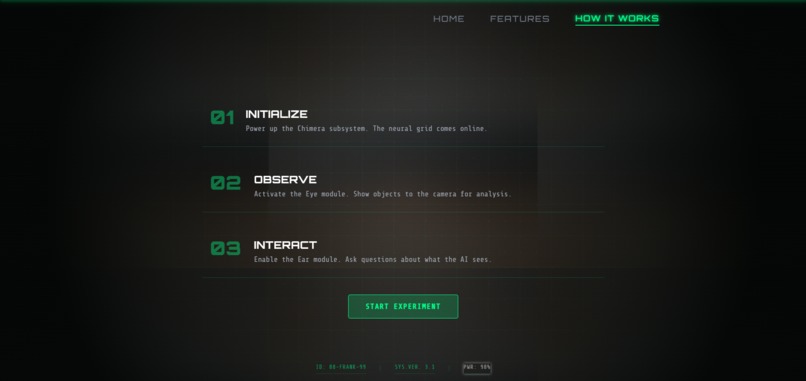
How to Use page
-

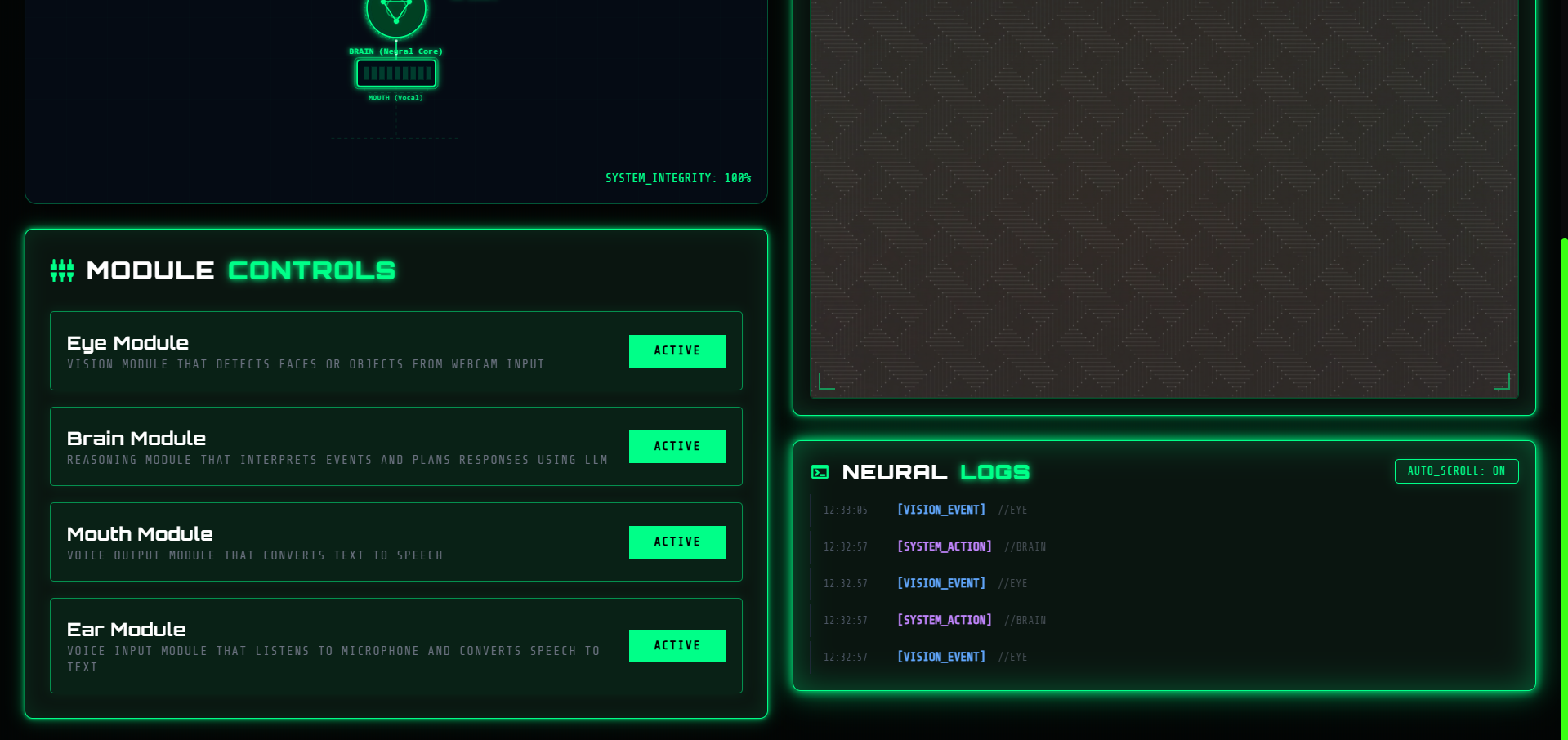
ChimeraForge interface
-
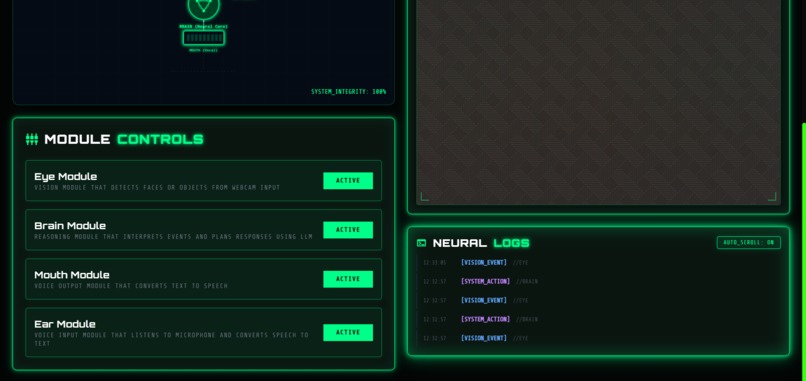
ChimeraForge Interface2


ChimeraForge: The Living AI Lab
🎃 Inspiration
The idea for ChimeraForge came from a simple question: What if you could build your own AI companion by mixing and matching abilities like building blocks?
Inspired by the concept of Frankenstein's monster and modular robotics, we wanted to create an AI system where users could toggle different "organs" on and off — giving the creature vision, hearing, reasoning, and speech. We designed it as a "Digital Lab" where users can experiment with these senses in real-time.
🧠 What It Does
ChimeraForge is a multimodal AI creature system with four deeply integrated modules:
👁️ The Eye (Vision)
A true multimodal vision system. It doesn't just "detect faces"—it sees. Using Llama 3.2 Vision, the creature analyzes webcam frames in real-time, describing objects, reading text, and understanding the physical world around it.
👂 The Ear (Hearing)
Listens to your voice using the Web Speech Recognition API, allowing for natural, hands-free conversation.
🧠 The Brain (Reasoning)
The core intelligence powered by Groq running Llama 3.3 & Llama 3.2 Vision. It holds the context, manages memory, and synthesizes inputs from all senses.
👄 The Mouth (Speech)
Gives the creature a voice, speaking responses aloud to complete the interaction loop.
✨ New Capabilities
- Conversation Memory: The creature now remembers your name and context throughout the session
- True Sight: Show it an object, and it will recognize it—not just faces!
- Session State: Memory automatically resets when you leave the lab (close the tab), ensuring a fresh experiment every time
🛠️ How We Built It
Architecture
Frontend (React + TypeScript) Backend (FastAPI + Python)
├── Eye Module (Webcam Stream) -------→ ├── Event Bus (Pub/Sub)
├── Ear Module (Speech API) ----------→ ├── Brain Module (Groq/Llama)
├── Mouth Module (TTS) <-------------- ├── Vision Processing
└── Creature Canvas (Framer Motion) <------ └── Session Memory Manager
Tech Stack
Backend:
- FastAPI: High-performance async Python framework
- Groq API: Leveraging the world's fastest inference engine to run Llama 3.3 70B and Llama 3.2 90B Vision
- Python AsyncIO: Managing concurrent streams of vision and audio events
Frontend:
- React 18 + TypeScript: Type-safe, component-based UI
- Tailwind CSS: Custom "Frankenstein" theme with neon glows, CRT effects, and dynamic layouts
- Framer Motion: Complex, code-driven animations (like the custom Neural Core splash screen)
- Web Speech API: Browser-native voice recognition
🔑 Key Implementation Details
Multimodal Fusion
We built a pipeline that fuses visual data (base64 frames) with audio context (transcribed text). The Brain module dynamically injects the latest visual frame into the LLM prompt only when relevant, optimizing for speed and cost.
Mathematical representation of the fusion process:
$$ \text{Response} = f_{\text{Brain}}(\text{Vision}t, \text{Audio}_t, \text{Memory}{t-k: t-1}) $$
where \(t\) is the current timestamp and \(k\) represents the memory window size.
Groq Speed Integration
Transitioned from Gemini to Groq. The ultra-low latency of Groq is critical for making a voice-and-vision AI feel "alive" and responsive rather than sluggish.
Latency improvement:
$$ \Delta t_{\text{Groq}} \ll \Delta t_{\text{Gemini}} $$
This reduction from \(\sim 3s\) to \(\sim 0.5s\) makes conversational interaction feel natural.
Active Memory System
Implemented a sliding-window memory buffer in the backend. It tracks the last 20 interactions, allowing for multi-turn conversations. We added a "Kill Switch" hook that detects SSE client disconnection to wipe the memory instantly when a user leaves.
Memory buffer representation:
$$ M_t = {(q_i, r_i)}_{i=\max(1, t-19)}^{t} $$
where \(q_i\) is the query and \(r_i\) is the response at interaction \(i\).
Procedural Animations
Instead of using heavy GIFs, we coded the "Neural Core" splash screen entirely in SVG and Framer Motion. It's a lightweight, scalable, and fully programmatic visual that represents the AI's state.
🚧 Challenges We Faced
1. Vision Latency vs. Real-Time Feel
Problem: Sending every frame to an LLM is too slow and expensive.
Solution: We implemented a hybrid system. The frontend handles raw streaming, while the backend smartly samples frames only when interaction occurs or significant motion is detected, preserving the "real-time" illusion.
Frame sampling strategy:
$$ \text{Sample}(f_t) = \begin{cases} 1 & \text{if } |f_t - f_{t-1}| > \theta \text{ or } t \bmod n = 0 \ 0 & \text{otherwise} \end{cases} $$
where \(\theta\) is a motion threshold and \(n\) is the periodic sampling rate.
2. Context Amnesia
Problem: Initially, the AI treated every sentence as a new conversation.
Solution: Built a stateful BrainModule with a conversation history buffer. The challenge was managing token limits while keeping the persona consistent.
Token management:
$$ \sum_{i=1}^{k} \text{tokens}(q_i, r_i) \leq T_{\max} $$
where \(T_{\max}\) is the maximum context window (typically 8192 tokens for Llama 3.3).
3. The "Uncanny Valley" of Delays
Problem: Voice interactions feel broken if there's a 3-second pause.
Solution: Optimizing with Groq reduced inference time massively. We also added UI states ("Thinking.. .", "Listening... ") to bridge the tiny remaining gaps, managing user expectations via good UX.
4. Deployment Hell
Problem: Synchronizing a Python backend with a React frontend across different hosting providers.
Solution: Adopted a hybrid deployment strategy—Vercel for the frontend (fast global CDN) and Render for the backend (containerized Python environment), connected via strict CORS policies.
🏆 Accomplishments
- ✅ True Multimodal AI: It can See, Hear, and Speak—all integrated into one cohesive experience
- ✅ Powered by Llama 3 on Groq: Utilizing cutting-edge open weights with industry-leading speed
- ✅ Conversation Memory: Successfully implemented context retention for natural dialogue
- ✅ Polished "Frankenstein" UX: A cohesive, high-fidelity dark theme with custom sound and visual effects
- ✅ Production Ready: Fully deployed and verifiable on the open web
📚 What We Learned
Latency Matters
In voice interfaces, speed is the most important feature. Groq changed the game for us here.
The perceived quality \(Q\) of a voice interface can be modeled as:
$$ Q \propto \frac{1}{\Delta t_{\text{response}}} $$
Multimodality Complexities
Managing state between what the AI sees and what it hears requires careful prompt engineering to prevent hallucinations.
State Management
Keeping frontend and backend state in sync (like "is the mic on?") requires a robust event protocol, not just simple API calls.
🚀 What's Next??
Emotion Synthesis
Use the vision model to detect user emotions and adjust the AI's "Mood" and color theme accordingly.
Emotion detection:
$$ e_t = \text{classify}(\text{Vision}_t) \in {\text{happy}, \text{sad}, \text{neutral}, \text{surprised}} $$
RAG Integration
Allow the creature to "read" uploaded documents and answer questions about them.
RAG pipeline:
$$ \text{Response} = \text{LLM}(\text{Query}, \text{retrieve}(\text{Query}, \text{Documents})) $$
3D Avatar
Replace the SVG core with a Three.js 3D head that lip-syncs to the audio.
📦 Installation & Setup
Prerequisites
- Node.js 18+
- Python 3.10+
- Groq API Key
Backend Setup
cd backend
python -m venv venv
source venv/bin/activate # On Windows: venv\Scripts\activate
pip install -r requirements.txt
Create a .env file:
GROQ_API_KEY=your_groq_api_key_here
Run the server:
uvicorn main:app --reload
Frontend Setup
cd frontend
npm install
npm run dev
🎮 Usage
- Open the lab in your browser (Chrome/Edge recommended)
- Toggle modules on the control panel:
- 👁️ Enable Eye to give the creature vision
- 👂 Enable Ear to let it hear you
- 🧠 Brain is always active (the core)
- 👄 Enable Mouth to let it speak
- Interact: Show objects, ask questions, have conversations!
- Reset: Close the tab to wipe memory and start fresh
🤝 Contributing
Contributions are welcome! Please feel free to submit a Pull Request.
🙏 Acknowledgments
- Groq for providing blazing-fast inference
- Meta AI for Llama 3.3 and Llama 3.2 Vision
- FastAPI and React communities
- The spirit of Frankenstein for inspiration
ChimeraForge proves that AI doesn't have to be a black box — it can be modular, transparent, and fun to experiment with!
Made with 🧪 and ⚡
Built With
- ai
- computer-vision
- fastapi
- grop
- machine-learning
- opencv
- python
- react
- real-time
- typescript
- voice-recognition
- web-speech-api



Log in or sign up for Devpost to join the conversation.